







1 背景调研
1.1 检查robots.txt
在爬取之前检查robots.txt可以最小化爬虫被禁封的可能,而且还能发现和网站结构相关的线索。在本书中获取robots.txt的方式为在完整网站首页后面加上/robots.txt,即http://example.webscraping.com/robots.txt 但是本人在尝试时并没有发现robots.txt,依然是网站的首页。如果哪位大神看到了有思路的话还希望指点一二本文以搜狗为例,获取robots.txt如下所示:

回归到本书中的robots.txt介绍。
在本书中的获取的robots.txt如下(纯手工抄的):
#section 1
User-agent:BadCrawler
Disallow:/
#section 2
User-agent:*
Crawl-delay:5
Disallow:/trap
#section 3
Sitemap: http://example.webscraping.com/sitemap.xml
在section2中,robots.txt规定无论使用哪种用户代理,都应该在下载请求之间给出5秒的抓取延迟。这里的/trap链接用于封禁那些爬取了不允许链接的恶意爬虫。如果访问了这个链接,服务器会封禁你的ip一分钟,甚至永久封禁。
1.2 检查网站地图
网站提供的sitemap文件(1.1中robots.txt中的section3部分)可以帮助爬虫定位网站最新的内容,而无需爬取每一个网页。但是该文件经常存在缺失、过期或者不完整的问题。(在本书提供的链接中依然没有发现sitemap文件)
1.3 估算网站大小
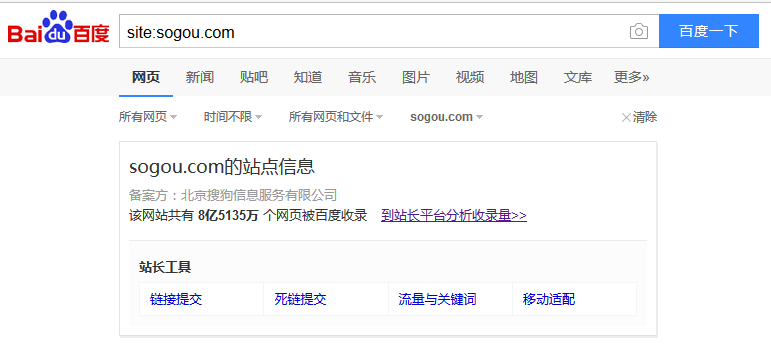
估算网站大小的方式为 site:域名。以搜狗为例,输入site:sogou.com即可获得网站大小:
1.4 识别网站所用的技术
首先安装builtwith模块
pip install builtwithimport builtwith
print builtwith.parse('http://example.webscraping.com/'){u'javascript-frameworks': [u'jQuery', u'Modernizr', u'jQuery UI'],
u'web-frameworks': [u'Web2py', u'Twitter Bootstrap'],
u'programming-languages': [u'Python'],
u'web-servers': [u'Nginx']}
1.5 寻找网站的所有者
首先安装python-whois
pip install python-whoisimport whois
print whois.whois('appspot.com'){
"updated_date": [
"2017-02-06 10:26:49",
"2017-02-06T02:26:49-0800"
],
"status": [
"clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited",
"clientTransferProhibited https://icann.org/epp#clientTransferProhibited",
"clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited",
"serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited",
"serverTransferProhibited https://icann.org/epp#serverTransferProhibited",
"serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited",
"clientUpdateProhibited (https://www.icann.org/epp#clientUpdateProhibited)",
"clientTransferProhibited (https://www.icann.org/epp#clientTransferProhibited)",
"clientDeleteProhibited (https://www.icann.org/epp#clientDeleteProhibited)",
"serverUpdateProhibited (https://www.icann.org/epp#serverUpdateProhibited)",
"serverTransferProhibited (https://www.icann.org/epp#serverTransferProhibited)",
"serverDeleteProhibited (https://www.icann.org/epp#serverDeleteProhibited)"
],
"name": "DNS Admin",
"dnssec": "unsigned",
"city": "Mountain View",
"expiration_date": [
"2018-03-10 01:27:55",
"2018-03-09T00:00:00-0800"
],
"zipcode": "94043",
"domain_name": [
"APPSPOT.COM",
"appspot.com"
],
"country": "US",
"whois_server": "whois.markmonitor.com",
"state": "CA",
"registrar": "MarkMonitor, Inc.",
"referral_url": null,
"address": "2400 E. Bayshore Pkwy",
"name_servers": [
"NS1.GOOGLE.COM",
"NS2.GOOGLE.COM",
"NS3.GOOGLE.COM",
"NS4.GOOGLE.COM",
"ns4.google.com",
"ns2.google.com",
"ns3.google.com",
"ns1.google.com"
],
"org": "Google Inc.",
"creation_date": [
"2005-03-10 02:27:55",
"2005-03-09T18:27:55-0800"
],
"emails": [
"abusecomplaints@markmonitor.com",
"dns-admin@google.com"
]
}
2 编写第一个网络爬虫
2.1下载网页
(1)重试下载
下载时遇到的错误经常是临时性的,但是4xx错误发生在请求出现问题时,比如网页不存在,一般不做处理。5xx错误则是发生在服务器端的问题,需要重试下载。
def download(url,num_retries=2):
print 'Downloading: ',url
try:
html=urllib2.urlopen(url).read()
except urllib2.URLError as e:
print 'Download error',e.reason
html=None
if num_retries>0:
if hasattr(e, 'code') and 500<=e.code<=600:
return download(url, num_retries-1)
return html(2)设置用户代理
默认情况下,urllib2使用Python-urllib/2.7作为用户代理下载网页,但是一些网站会封禁这个默认的用户代理,所以要进行用户代理的设定。本书中设定“wswp”为默认的用户代理。代码如下:
def download(url,user_agent='wswp',num_retries=2):
print 'Downloading: ',url
headers={'User-agent':user_agent}
request=urllib2.Request(url,headers=headers)#Request!!
try:
html=urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'Download error:',e.reason
html=None
if num_retries>0:
if hasattr(e, 'code') and 500<=e.code<=600:
download(url, user_agent, num_retries-1)
return html2.2 ID遍历爬虫
本书示例网站http://example.webscraping.com/中每个国家的网址区别在于URL的结尾处:
http://example.webscraping.com/places/default/view/Afghanistan-1
http://example.webscraping.com/places/default/view/Aland-Islands-2
http://example.webscraping.com/places/default/view/Albania-3
但是如果将URL后面的结果直接改为1,2,3效果依然相同。
http://example.webscraping.com/places/default/view/1
http://example.webscraping.com/places/default/view/2
http://example.webscraping.com/places/default/view/3
所以考虑利用URL后面的ID进行爬虫。即使用http://example.webscraping.com/places/default/view/+ID数字的形式进行每一个国家的爬取。此时如果数据库ID表示连续的或者中间偶尔出现间隔,那么爬虫访问到间隔点时会退出。这时候应该考虑连续多次下载错误时在退出的问题。
max_errors=5
num_error=0
for page in itertools.count(1):
url='http://example.webscraping.com/places/default/view/-%d'%page
html=download(url)
if html is None:
num_error+=1
if num_error==max_errors:
break
else:
num_error=02.3 链接爬虫
这里就是利用正则表达式进行所有链接的筛选,因为网页中的href链接是相对路径,所以本书中利用urlparse.urljoin(seed_url, link)进行绝对路径的拼接。同时为了防止重复遍历爬取过的链接,本书中通过列表和集合进行了判断。具体分析如下代码。
#-*- coding:utf-8 -*-
import re
from common import download
import urlparse
def link_crawler(seed_url, link_regex):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
seen = set(crawl_queue) #用于记录爬取过的网页
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
# 检查增则匹配
if re.match(link_regex, link):
# 获取绝对路径
link = urlparse.urljoin(seed_url, link)
# 检查是否爬取过
if link not in seen:#这里的逻辑是将遍历到的link链接都分别加入到seen和crawl_queue。但是在之后调用download函数时只是取crawl_queue中的链接,而
seen.add(link) #seen中的链接不动。所以在这里可以进行是否爬取过的判断。
crawl_queue.append(link)
def get_links(html):
"""Return a list of links from html
"""
#增则预编译,选取所有的href链接
webpage_regex = re.compile('<a href="(.*?)">', re.IGNORECASE)
# 更具上面的正则预编译返回html页面内的所有链接
return webpage_regex.findall(html)
if __name__ == '__main__':
link_crawler('http://example.webscraping.com', '/places/default/view/.*?-\d|/places/default/index')(1)解析robots.txt文件
利用python自带的robotparser模块进行robots.txt解析。robotparser模块首先会加载robots.txt文件,然后通过can_fetch()函数确定指定的用户代理是否允许访问网页。
import robotparser
rp=robotparser.RobotFileParser()
rp.set_url('http://example.webscraping.com/robots.txt')
rp.read()
url='http://example.webscraping.com/'
user_agent='BadCrawler'
rp.can_fetch(user_agent,url)#结果为false
user_agent='GoodCrawler'
rp.can_fetch(user_agent,url)#结果为true(2)支持代理
当时用支持代理进行访问某个网站时可以利用如下代码进行设置
request = urllib2.Request(url, data, headers)
opener = urllib2.build_opener()
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
response = opener.open(request)
html = response.read()为了避免下载过快而导致被封禁,应该在两次下载之间添加延时,从而对爬虫进行限速。
class Throttle:
"""Throttle downloading by sleeping between requests to same domain
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
domain = urlparse.urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
#domains最初为一个空的字典,当第一次从里面取数据时必然为空。所以该句代码将返回的domain设为字典的键将现在的时刻设置为键的值
#domain为example.webscraping.com。第一次存进domains的也是example.webscraping.com。将wait函数下载download之前
#即可实现下载的限速。
一些网站会动态生成网页内容,这样会有无限多个网页,爬虫将永无止境,这就是爬虫陷阱。为了避免这种陷阱可以设置深度。深度就是到达当前网页经过了多少个链接。当到达最大深度时,爬虫就不再像队列中添加该网页中的连接了。
def link_crawler(。。。max_depth=-1):
crawl_queue = Queue.deque([seed_url])
seen = {seed_url: 0}
while crawl_queue:
url = crawl_queue.pop()
depth = seen[url]
if depth != max_depth:
for link in links:
if link not in seen:
seen[link] = depth + 1#初始depth为0,当将第一个网页内所有的链接都放进seen中,同时将depth设置为1.代表这是第一个下载网页里面的所有链接。同理当对第二个链接进行网页内容下载时
#depth就被设置为2了。这时候就不会在往seen里面增加链接。
crawl_queue.append(link)
代码最终版本如下:
#-*-coding:utf-8-*-
import re
import urlparse
import urllib2
import time
from datetime import datetime
import robotparser
import Queue
def link_crawler(seed_url, link_regex=None, delay=5, max_depth=-1, max_urls=-1, headers=None, user_agent='wswp', proxy=None, num_retries=1):
"""Crawl from the given seed URL following links matched by link_regex
"""
# the queue of URL's that still need to be crawled
crawl_queue = Queue.deque([seed_url])
# the URL's that have been seen and at what depth
seen = {seed_url: 0}
# track how many URL's have been downloaded
num_urls = 0
rp = get_robots(seed_url)
throttle = Throttle(delay)
headers = headers or {}
if user_agent:
headers['User-agent'] = user_agent
while crawl_queue:
url = crawl_queue.pop()
# check url passes robots.txt restrictions
if rp.can_fetch(user_agent, url):
throttle.wait(url)
html = download(url, headers, proxy=proxy, num_retries=num_retries)
links = []
depth = seen[url]
if depth != max_depth:
# can still crawl further
if link_regex:
# filter for links matching our regular expression
links.extend(link for link in get_links(html) if re.match(link_regex, link))
for link in links:
link = normalize(seed_url, link)
# check whether already crawled this link
if link not in seen:
seen[link] = depth + 1#初始depth为0,当将第一个网页内所有的链接都放进seen中,同时将depth设置为1.代表这是第一个下载网页里面的所有链接。同理当对第二个链接进行网页内容下载时
#depth就被设置为2了。这时候就不会在往seen里面增加链接。
# check link is within same domain
if same_domain(seed_url, link):
# success! add this new link to queue
crawl_queue.append(link)
# check whether have reached downloaded maximum
num_urls += 1
if num_urls == max_urls:
break
else:
print 'Blocked by robots.txt:', url
class Throttle:
"""Throttle downloading by sleeping between requests to same domain
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
domain = urlparse.urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.now() - last_accessed).seconds
if sleep_secs > 0:
time.sleep(sleep_secs)
self.domains[domain] = datetime.now()
#domains最初为一个空的字典,当第一次从里面取数据时必然为空。所以该句代码将返回的domain设为字典的键将现在的时刻设置为键的值
#domain为example.webscraping.com。第一次存进domains的也是example.webscraping.com。将wait函数下载download之前
#即可实现下载的限速。
def download(url, headers, proxy, num_retries, data=None):
print 'Downloading:', url
request = urllib2.Request(url, data, headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
response = opener.open(request)
html = response.read()
code = response.code
except urllib2.URLError as e:
print 'Download error:', e.reason
html = ''
if hasattr(e, 'code'):
code = e.code
if num_retries > 0 and 500 <= code < 600:
# retry 5XX HTTP errors
return download(url, headers, proxy, num_retries-1, data)
else:
code = None
return html
def normalize(seed_url, link):
"""Normalize this URL by removing hash and adding domain
"""
link, _ = urlparse.urldefrag(link) # remove hash to avoid duplicates
return urlparse.urljoin(seed_url, link)
def same_domain(url1, url2):
"""Return True if both URL's belong to same domain
"""
#用于判断是否是需要遍历的网址,即只要netloc部分(example.webscraping.com/)相同就符合要求
return urlparse.urlparse(url1).netloc == urlparse.urlparse(url2).netloc
def get_robots(url):
"""Initialize robots parser for this domain
"""
rp = robotparser.RobotFileParser()
rp.set_url(urlparse.urljoin(url, '/robots.txt'))
rp.read()
return rp
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile('<a href="(.*?)">', re.IGNORECASE)
# list of all links from the webpage
return webpage_regex.findall(html)
if __name__ == '__main__':
link_crawler('http://example.webscraping.com', '/places/default/view/.*?-\d|/places/default/index', delay=5, num_retries=1, user_agent='BadCrawler')
link_crawler('http://example.webscraping.com', '/places/default/view/.*?-\d|/places/default/index', delay=0, num_retries=1, max_depth=2, user_agent='GoodCrawler')















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









