








本文转载自: http://blog.csdn.net/yick_liao/article/details/62222153
简介
fastText是一种Facebook AI Research在16年开源的一个文本分类器。
其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间,这些都可以在作者的paper中看到。
原理
模型架构
fastText的架构和word2vec中的CBOW的架构类似,因为它们的作者都是Facebook的科学家Tomas Mikolov,而且确实fastText也算是words2vec所衍生出来的。
Continuous Bog-Of-Words

fastText

fastText的模型架构类似于CBOW,两种模型都是基于Hierarchical Softmax,都是三层架构:输入层、 隐藏层、输出层。
CBOW模型又基于N-gram模型和BOW模型,此模型将
W(t−N+1)……W(t−1)
作为输入,去预测
W(t)
fastText的模型则是将整个文本作为特征去预测文本的类别。
层次之间的映射
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
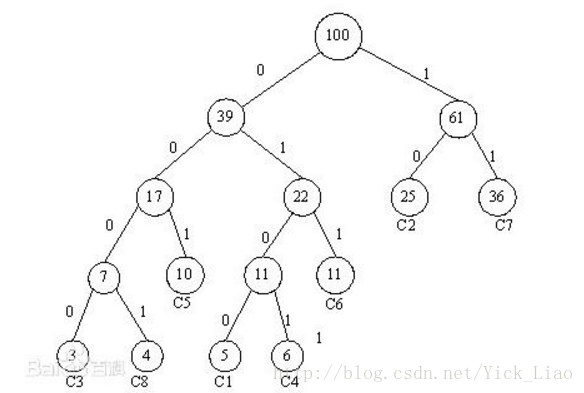
模型的训练
Huffman树中每一叶子结点代表一个label,在每一个非叶子节点处都需要作一次二分类,走左边的概率和走右边的概率,这里用逻辑回归的公式表示
正类别的概率:
σ(Xiθ)=11+e−xiθ
负类别的概率:
1−σ(Xiθ)
每个label都会有又一条路径,对于训练样本的特征向量
Xi
和对应的label
Yi
,预测出来
Xi
的样本属于所对应的label是
Yi
的概率:
P(Yi|Xi)=∏lj=2P(dj|Xi,θj−1)
其中:
P(dj|Xi,θj−1)={σ(Xiθ),1−σ(Xiθ),if d_j=1if d_j=0
极大似然估计
当模型是条件概率分布,损失函数可用对数函数表示,经验风险最小化等价于极大似然估计。
对数似然函数:
L(Y,P(Y|X))=−logP(Y|X)
目标函数:
ι=1nΣni=1logP(Yi|Xi)
将上述所用到的式子不断的带入带入再带入,变换变换再变换,就变成了一个只关于
θj
的式子,用随机梯度上升法求出当
θj
取何值时式子的值最大。
如何做到fast
在作者的paper中讲到,当类别的数量巨大时,计算线性分类器的计算量相当高,更准确的说,计算复杂度是
O(kh)
,
k
是类别的数量,
h
是文本特征的维度数。基于 Huffman 树的 hierarchical softmax,可以将计算复杂度降到
O(hlog2(k))
。
建立Huffman树结合优先队列,计算复杂度可以是
O(hlog2(k))
。
在用n个训练样本进行训练时,根据每个类别出现的次数作为权重来建Huffman树,出现次数多的类别的样本,路径就短,出现次数少的类别的样本,路径就长。经过计算,单个样本在经过训练时所需的时间复杂度应该是
hlog2(k)
。
但fastText在预测时,计算复杂度仍然是
O(kh)
,因为预测时计算量确实很小,所以这可能也不是fastText的初衷所在。















 731
731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









