






昨天讲了 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
import pandas as pd
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, .17, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
print(frame)
产生的DataFrame如下:
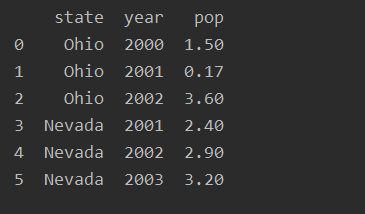
对于大型的DataFrame,head方法可以筛选出前5行。
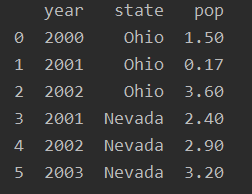
如果你指定列顺序,DataFrame将会按指定顺序排列。
frame_col = pd.DataFrame(data,columns=['year', 'state', 'pop'])
print(frame_col)
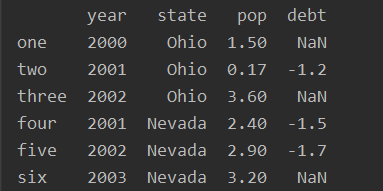
如果传递的值不在字典中,将会在结果中出现缺失值:
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
print(frame2)
print(frame2.columns)


DataFrame中的一列,可以看做是Series: # 按字典标记 print(frame2['state']) # 按属性使用 print(frame2.year)
注意:frame[column]对于任意列名均有效,如果该列不存在,可以生成新列。但是frame.column只在列名是有效的python变量名时有效,并且不可以生成新列。

# 行可以通过位置或特殊属性loc进行选取
print(frame2.loc['three'])
列的引用是可以修改的。如空的‘debt’列可以赋值为标量值或数组值。
frame2['debt'] = 16.5
print(frame[2])
frame2['debt'] = np.arange(6.)
print(frame2)

val = pd.Series([-1.2, -1.5, -1.7],index=['two', 'four', 'five'])
frame2['debt'] = val
print(frame2)
这一列是布尔值,判断条件是state列是否为‘Ohio’:
frame2['eastern'] = frame2.state == 'Ohio'
del方法可以用于移除之前新建的列
del frame2['eastern']
从DataFrame中选取的列是数据的视图,而不是数据的拷贝。因此对Series的修改会映射到DataFrame中。















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









