






因工作变动接手了一个云平台改造项目,该项目属于己经上线且每月有大量交易订单的云平台,之前采用的是SpringMVC+Hibernate+FreeMarker+MySql架构,集web前端和接口为一体。经过对业务增长趋势的评估,预计将在数月之后无法支撑原有业务的增长。当前架构主要存在如下问题:1、扩展维护困难、2、性能逐渐缓慢。随着业务的快速增长逼迫我们对现有架构进行重构。由于是线上交易系统,留个我们改造的时间非常有限,不但需要维持线上系统的稳定还要支撑新需求的开发,否则将由于技术支撑不利错失业务发展关键时间窗口,基于务实的原则我们制定如下步骤进行逐步改造。
一、去hibernate迁移至mybatis
从hibernate迁移至mybatis, DAO层基本上需要重写一遍,其中主要工作量为理解原hibernate DAO层逻辑并翻译成sql,主要是细心活。其中需要注意的是mybatis动态表名的传入,需要将mapper的statementType类型修改为STATEMENT,并将SQL语句中#{}都改为${}。在使用${}传参过程中,需要特别注意SQL注入攻击危险。一般会在SpringMVC层将敏感字符转义。比如">"用“>”表示,网上有很多封装函数,或者apache common lang包的StringEscapeUtils.escapeHtml()。
二、去掉sql之间的表关联
去掉sql之间的表关联,传统关系型数据库理论中的三范式在互联网的数据库模型中是不适用的,主要造成的问题是无法进行分表分库。这就要求所有dao方法必须保持单表操作,保持单表操作为分表改造奠定了改造基础。
三、Service层对原子DAO业务逻辑进行组装
在去掉表关联后需要改造所有实体结构。首先取掉实体之间的一对一,多对一,多对多关联关系,将实体之间的引用关系修改为对实体ID的引用。同时为了上层方便使用需要引入业务BO对象,在service层调用多个原子的dao方法并组装成业务BO对象。
四、分表
在单张表超过2000万条记录后,mysql的查询性能开始降低,表变更字段等待时间漫长。分表后提升性能和扩展性后又带来如下问题:(1) 分表后老数据如何处理(路由策略)?(1)、如何根据主键、订单号等路由到正确的表?(2)、分表后如何进行分页查询?(3)、如何保证上线后分表数据平滑从老库过渡到新库?
1、 路由策略的选择
首先,我们对数据库中所有的表记录进行分析,统计每张表的数据量大小。经过统计后我们发现随着业务的增长业务数据也会快速进行增长的表主要为订单表、订单明细表。其它的表在近两年内并不会随着业务的增长而快速增长。所以只需要对订单表、订单明细表进行拆分。路由策略选择不可能做到完美,世界本来也是不完美的,关键是在合适的阶段选择合适的策略,即能满足商业战略时间窗口点又能在追求技术完美型中寻找平衡点。我们预测了业务近5年的发展目标为现有业5倍的增长,发现按月进行拆分可以保证每月数据量均低于2000万条,基于务实的原则我们选择了按月进行分表的路由策略。经过多方面考虑在能够兼固效率和降低改造复杂度的思路提出老数据老办法,新数据新办法。老数据中的主键己经生成,如果按新的主键策略重新生成,会牵扯到所有关联表中的ID都需要进行替换,这样会增加改造的复杂度和工作量,所以最终考虑将新数据按照新的主键生成策略进行生成。当按月分表仍不能满足业务支持要求时,可以再次以日信息计算更细粒度的拆分策略,例如可按周为单位进行表折分。
2、根据主键或订单号选择正确的表
主键的生成算 自增ID的生成,参考twitter Snowflake算法
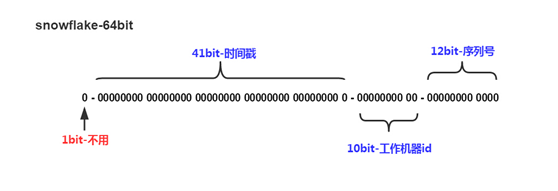
(图1)
在Java语言系统中,可以通过Long来表示主键,Long类型包含64个位,正好可以存储该ID, 1至41位的二进制数值用来表示日期时间戳,43至53位可以表示1024台主机,我们可以为每台API服务器分配一个工作机器ID,43至55位可以生成线程唯一的序列号。预留的工作机器ID可以作为南北双活机房的路由判断条件,如1,2,3,4号工作机器ID路由到北机房API服务器,5,6,7,8工作机号ID路由到南机房API服务器。
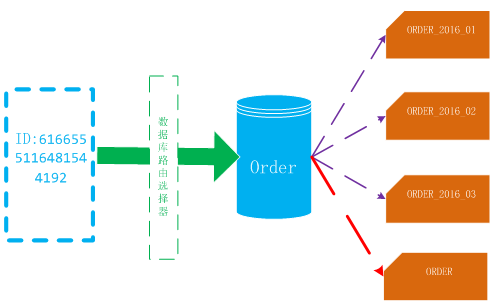
(图2)
当按订单号查询时系统首先根据订单号长度的不同,来选择是路由到新的切分订单表,还是路由到原订单表。因为新主键ID会包含日期信息,系统会根据主键解读出日期信息,根据月份的不同来选择该数据库对应的月份表,如果读取不出日期信息就可以判断出为原订单表。
3、 如何保证上线后分表数据平滑从老表过渡到新表
首先系统配置统一的分表切割时间公共变量,在插入订单时先判断是否在分表切换时间点之前,如果在分表切换时间点之前则将订单数据插入到老表,否则将订单数据按当前月份不同插入到新的拆分月表。
4、 分表后分页查询
在订单分表后存在的主要难点是分表后数据的分页查询操作。假设以2016-07-26 00:00:01 开始按月分表,查询2016-05-01 00:00:01至2016-09-11 12:00:05 期间的所有订单分解为如下几步:
(1) 通过开始时间、结束时间、分表时间计算出需要的路由信息集合。
a) 格式:表名|起始日期|结束日期
b) 路由集合: Order|2016-05-01 00:00:00|2016-07-26 00:00:01
Order_2016_07|2016-07-26 00:00:00|2016-07-01 23:59:59
Order_2016_08|2016-08-01 00:00:00|2016-08-31 23:59:59
Order_2016_09|2016-09-01 00:00:00|2016-09-11 12:00:05
(2) 按分页信息(pageNo,pageSize)及路由信息集合查询订单基本信息集合。
a) 遍历路由集合返回总记录数及表概括信息集合。
i. 表概括信息定义:表名、起始行数、记录数、路由信息;
ii. 表概括信息集合:
1. Order、1、137、Order|2016-05-01 00:00:00|2016-07-26 00:00:01
2. Order_2016_07、137、10、Order_2016_07|2016-07-26 00:00:00|2016-07-01 23:59:59
3. Order_2016_08、147、32、2016-08-01 00:00:00|2016-08-31 23:59:59
4. Order_2016_09、179、10、2016-09-01 00:00:00|2016-09-11 23:59:59
iii. 方法描述:
private RouteTableResult getRouteTableResult(OrderSearchModel searchModel, List<String> routeTables) {
Integer sumRow = new Integer(0);
Map<String, RouteTable> routeTableCountMap = new TreeMap<String, RouteTable>();
RouteTableResult routeTableResult = new RouteTableResult();
for (String routeTable : routeTables) {
String[] routeTableArray = routeTable.split("\\|");
if (routeTableArray.length == 3) {
String tableName = getTableByRouteTableAndSetSearchModel(searchModel, routeTableArray);
Integer orderCount = ticketOrderDao.searchOrderCount(tableName,searchModel);
Integer startIndex = sumRow.intValue();
RouteTable routeInfo = new RouteTable(startIndex, orderCount, routeTable);
routeTableCountMap.put(tableName, routeInfo);
sumRow += orderCount;
}
}
routeTableResult.setRouteTableCountMap(routeTableCountMap);
routeTableResult.setSumRow(sumRow);
return routeTableResult;
}
b) 根据分页信息,查询出该分页需要跨越的表路由信息集合,具体算法如下:
i. 遍历概括信息集合
ii. 当开始行和结束行与当前路由区有交集则说明有数据在该表内
iii. 并将该表加入遍历路由集合;
iv. 如果路由表信息集合中有数据且不满足上述条件则退出;
v. 返回需要跨越的表路由信息集合;
vi. 方法描述:
private List<String> getRouteTables(OrderSearchModel searchModel,Map<String, RouteTable> routeTableCountMap) {
List<String> routeTableInfoList = new ArrayList<String>();
Integer startIndex = (searchModel.getPageNo() - 1) * searchModel.getPageSize();
Integer endIndex = startIndex + searchModel.getPageSize() -1;
for (Entry<String, RouteTable> entry : routeTableCountMap.entrySet()) {
RouteTable routeTable = entry.getValue();
//当开始行和结束行与当前路由区有交集
if( !(startIndex > routeTable.getEndIndex()) && !(endIndex < routeTable.getStartIndex())){
routeTableInfoList.add(routeTable.getRouteInfo());
//如果路由表信息集合中有数据且不满足上述条件则退出
}else if (routeTableInfoList.size()>0) {
break;
}
}
return routeTableInfoList;
}
c) 查询该分页下的订单列表,具体算法如下:
i. 首先设置最后一次遍历的表为需要跨越路由信息集合的第一张表;
ii. 设置己读条数readCount等于0;
iii. 遍历需要跨越路由信息集合;
iv. 根据路由信息返回表名及设置搜索条件;
v. 根据表名获取路由概要信息;
vi. 计算开始行号,如果当前表名和最后遍历的表名相同,则开始行号等于(当前的页数-1)*原请求页面大小(originalPageSize)-当前表路由概要信息起始行,否则开行号设置为0;
vii. 计算当前页面大小pageSize为原请求页面大小(originalPageSize) – 己读条数(readCount);
viii. 设置搜索条件起始行号、当前页面大小;
ix. 设置最后一次遍历的表为当前表;
x. 根据当前表名、搜索条件调用dao返回订单基本信息列表,并加入订单总列表集合;
xi. 己读数增加当前订单列表大小;
xii. 如果己读数大于等于原请求页面大小则跳出循环,否则继续循环;
xiii. 返回订单总列表集合;
xiv. 方法描述:
private List<Order> getOrderListByRoutePageTable(OrderSearchModel searchModel,
Integer originalPageSize, Map<String, RouteTable> routeTableCountMap,
List<String> routePageTables) {
Integer readCount = 0;
List<Order> orderList = new ArrayList<Order>();
if (routePageTables != null && routePageTables.size() > 0) {
String[] routeTableArrayFirst = routePageTables.get(0).split("\\|");
String lastTableName = null ;
if (routeTableArrayFirst.length == 3) {
lastTableName = routeTableArrayFirst[0];
}
for (String routeTable : routePageTables) {
String[] routeTableArray = routeTable.split("\\|");
if (routeTableArray.length != 3) {
break;
}
String tableName = getTableByRouteTableAndSetSearchModel(searchModel, routeTableArray);
RouteTable routeTableInfo = routeTableCountMap.get(tableName);
Integer startRow = 0;
if( tableName.equals(lastTableName)){
startRow = (searchModel.getPageNo()-1)*originalPageSize - routeTableInfo.getStartIndex();
}
Integer pageSize = originalPageSize - readCount;
searchModel.setStartRow(startRow);
searchModel.setPageSize(pageSize);
lastTableName = tableName;
List<Order> orderListPage = orderDao.searchOrderList(tableName,searchModel);
orderList.addAll(orderListPage);
readCount += orderListPage.size();
if (readCount.intValue() >= originalPageSize) {
break;
}
}
}
return OrderList;
}
(3) 根据Order集合组装OrderBo集合
(4) 根据返回的总数及分页信息组装分页结果
五、mysql主从分离、引入三级缓存
为了提高性能,首先配置mysql主从分离,通过Spring多数据源来实现动态切换。引入三级缓存主要分为:(1)、线程级:当同一线程请求时,线程级缓存绑定在线程间ThreadLocal变量上,可以降低线程间切换造成的时间开销。(2)、进程级:进程级缓存在同一jvm中共享缓存,减速少跨进程间网络开销。(3)、跨进程的集中式缓存:使用redis或memcache内存缓存来降低对数据库系统的冲击。在做完以上优化后,我们的接口响应速度提高了近5倍。
六、分布式服务化
待续
七、异地南北机房双活
待续















 2039
2039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









