






九月份的工作内容主要是一个接口服务的开发,业务功能实现且功能测试没有问题之后,联系了压测的同事对该服务的性能进行了一系列的测试。在测试的过程中,遇到了一些奇怪的问题,经过笔者自己搜索资料并向老司机们请教,一一解决掉,在此做个总结,并与大家分享。
技术架构介绍:分布式服务接口读取EHCACHE或REDIS数据,计算后返回JSON格式数据,应用服务器为wildfly 9。
压测需求描述:服务接口是公司业务主流程的一个子分支,日均PV1亿,要求响应时间为50ms以内。
问题描述:本地开发机器中自测服务接口时,统计执行时间为400ms左右。在压测环境中,TPS为12时,服务接口的响应时间接近3s,详见下图:
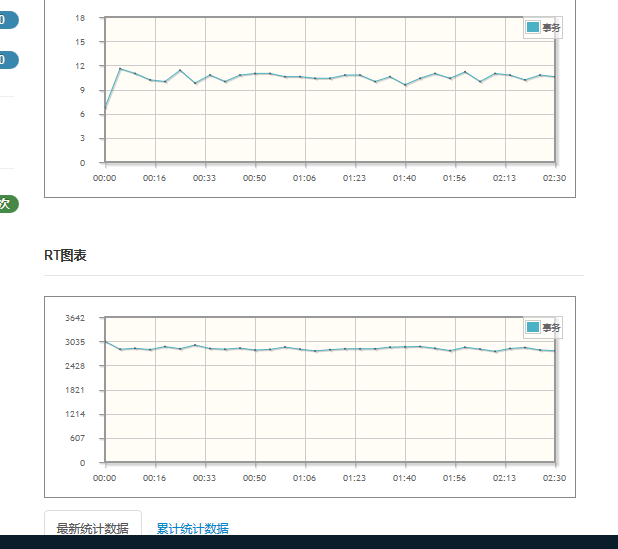
图一
解决过程:
【1】加大并发访问量,检查是jboss还是redis达到了性能瓶颈
vmstat命令,jboss机器指标如下:
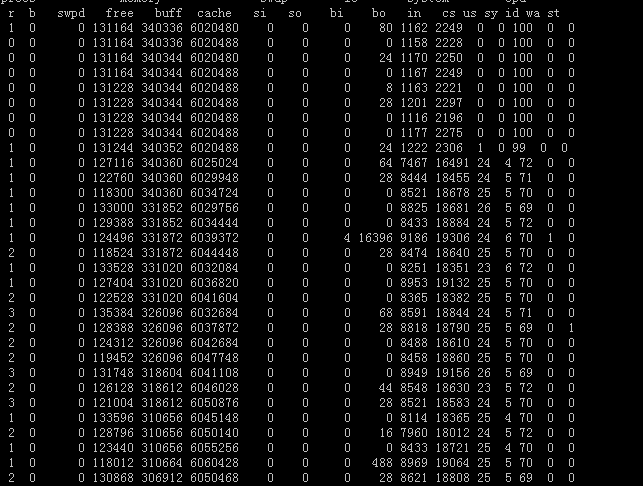
应用压力不到30%,距离70%的指标还差一大截。
redis机器指标如下:
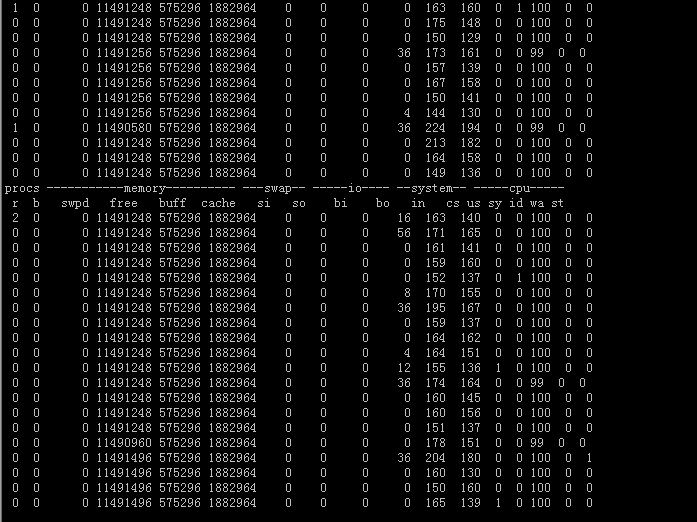
cpu空闲时间接近100%!!!
消耗时间依旧与图一相同!!!
【2】检查应用打印的日志
打开应用的日志目录,输入ll命令,截图如下:

发现debug日志接近40mb,这说明应用的日志级别为debug,且不停的打印日志,最终导致应用响应时间很长。修改应用的日志级别为error,删除之前的debug日志。
上述操作完成之后,重新执行压测,响应时间截图如下:
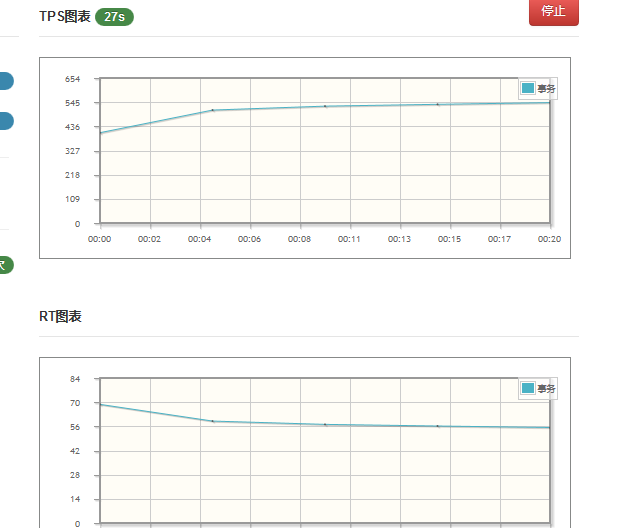
tps为545的时候,相应时间为56ms。
jboss的指标如下:
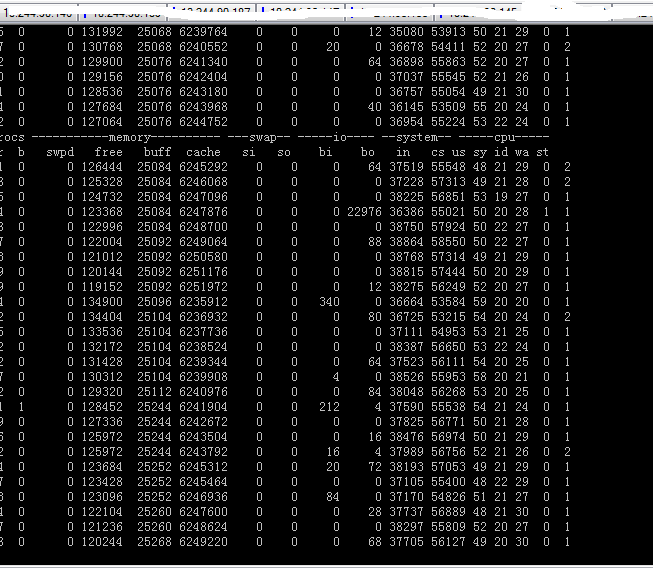
redis的指标截图如下:
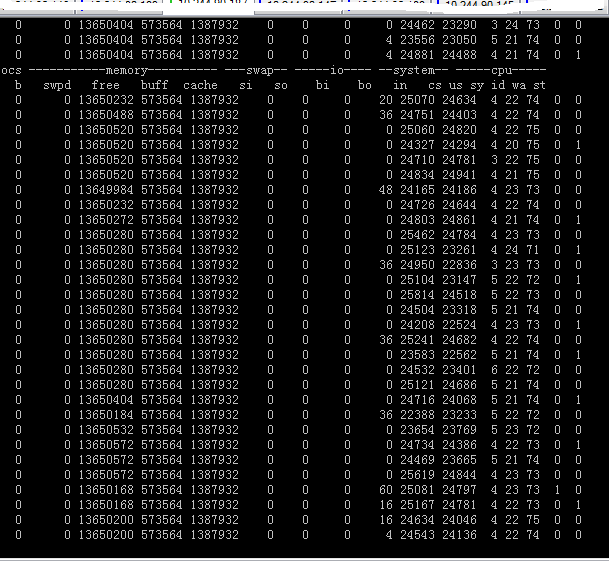
jboss和redis的指标都与预期一致。问题解决,大家长长的松了一口气,幸福的花儿从此刻开始绽放。
先去打杯水,压测同学继续执行后面的压测场景。
一天无事。。。
第二天,测试关闭二级缓存的数据。关闭掉ehcache之后,测试同学开始执行压测。
过了一小会儿,测试同学发来一个很让人失落的消息,接口响应又出现了昨天的缓慢情形。只是关闭了了ehcache,会有这么严重的影响?理智告诉我们,这是不合理的。出现这种情形只能有2个可能的原因:1、代码有问题;2、压测环境有问题。
本地测试数据可以排除代码问题,且负责业务测试的同学反馈接口响应时间以“肉眼”无法看到停顿。那就只能一个可能了:压测环境有问题。
redis性能指标截图:
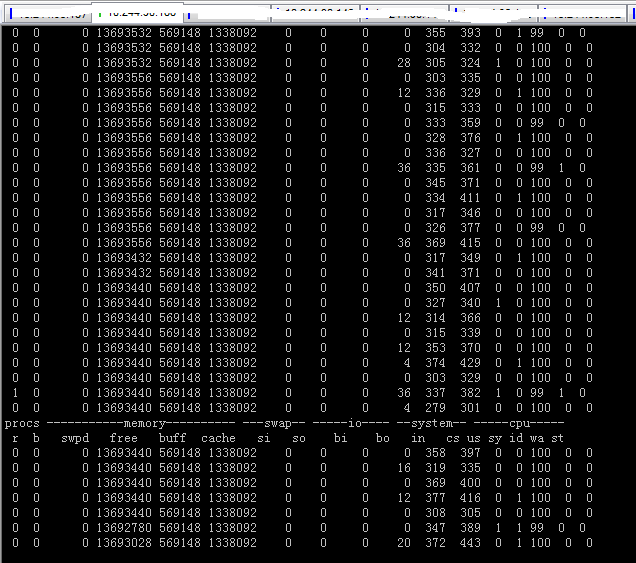
jboss指标截图:
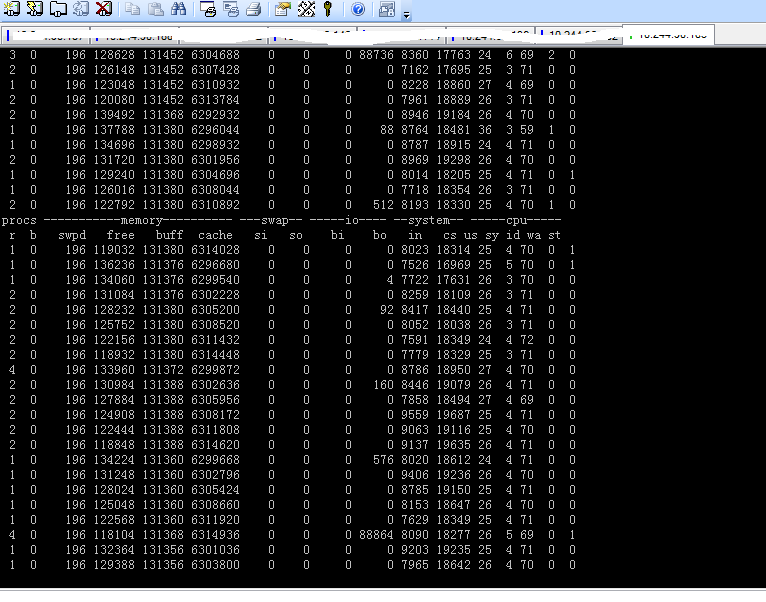
tps为12的时候,redis基本没有压力,jboss的cpu消耗为30%左右。
似乎山穷水尽了,看来只能放大招了:重启。
jboss和redis机器全部重启,数据重新写入redis缓存,一波操作下来,重新压测。
然并卵,压测结果是外甥打灯笼-----照舅(旧)。
开始怀疑是压测工具统计有问题了(我的程序怎么可能如此低效率??)
于是让测试同学保持压测的同时,我在浏览器里以http请求的方式执行测试桩,执行时间截图如下:
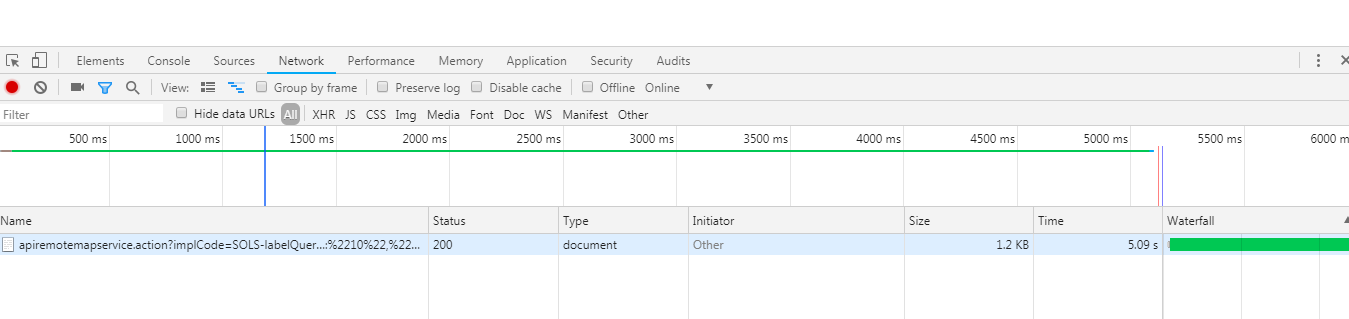
比压测统计的数据还要打脸,响应时间超过5s了。
都走开,我想静静。
程序为何突然变慢了?昨天不是已经解决日志级别的问题了么?会不会是有其它程序在jboss机器上运行,影响了服务接口的调用?
打开监控页面,找到jboss机器的流量信息,截图如下:
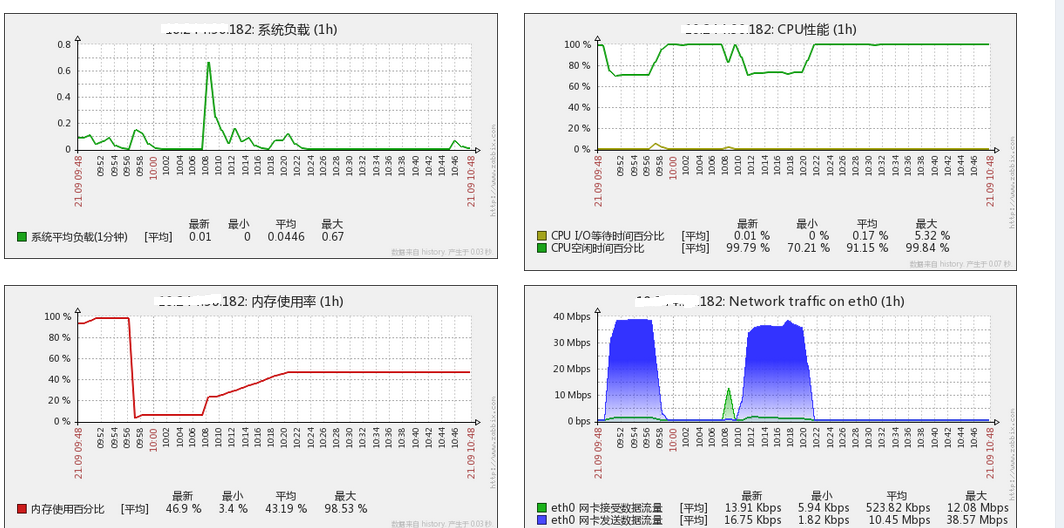
jboss机器的流量异常的大,正常情形下,服务器的流量应该为几百kb。于是开始着手监控jboss机器的实时流量。
给linux装上iftop工具,安装完成之后,输入"iftop"指令,然后让测试同学再执行压测,jboss机器实时流量截图如下:
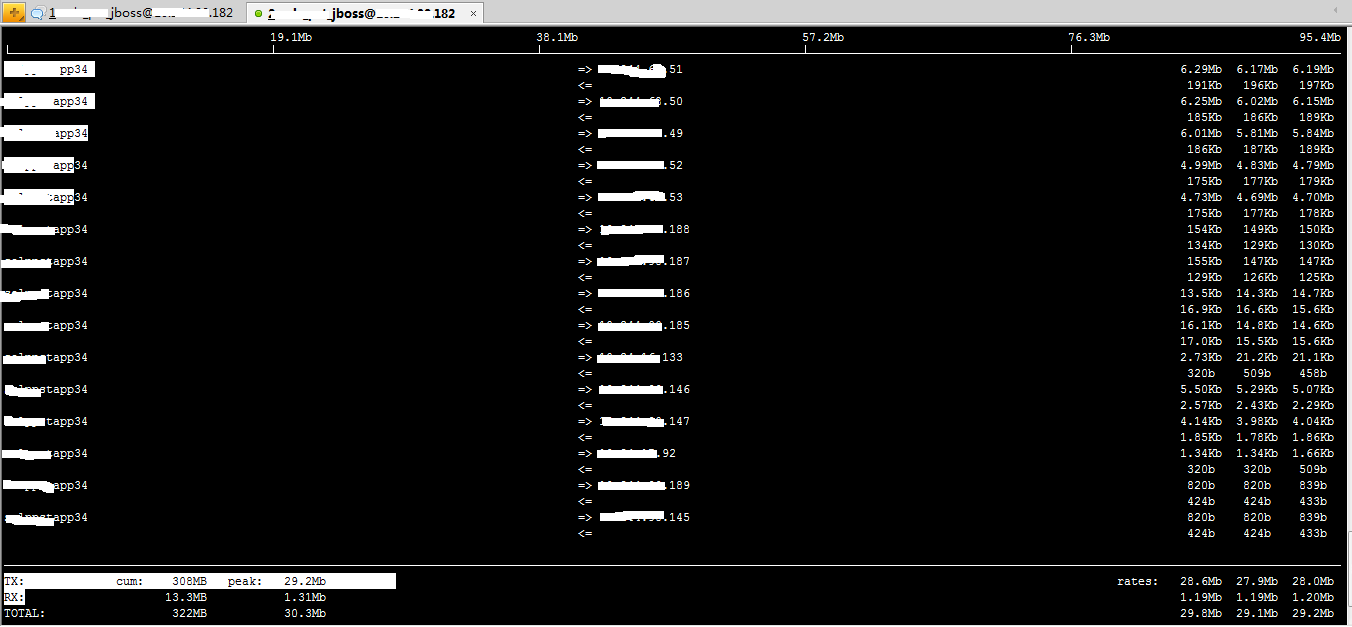
49、50、51、52这几台机器与jboss的流量交互很多,都在6mb以上,果断的去运维平台查这几台机器是干啥的。一通查询之后,发现这几台机器部署的是kafka集群,负责我司测试环境的服务接口日志采集。压测环境开通了日志采集,jboss机器的执行信息会不停的发送给kafka集群,最终流量过大导致jboss机器在执行业务接口的时候响应时间特别慢。
找到问题症结就好办了,限制日志采集的数据量,甚至直接关闭日志采集就好了。于是,我采取了暴力的手段:关掉。
关掉之后,继续压测,各项指标开始正常了。
傍晚时分,测试同学发来了压测结果:
















 2717
2717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









