







很多同学在开始学排序算法的时候都会觉得堆排序是比较难的,其实对于堆排序,只要理解了两点,应该就可以掌握堆排序了,下面说说要理解哪两点以及c语言的实现。
第一点:堆的特性。
下面的堆的特性定义来自算法导论:
最大堆特性是指除了跟以外的每个结点i,有A[PARENT[i]]>=A[i],即每个结点的值至多是和其父结点的值一样大。
最小堆特性是指出了跟以外的每个结点i,有A[PARENT[i]]<=A[i],即每个结点的值至少是和其父结点的值一样大。
也就是说,最大堆的父结点都大于等于其子结点,最小堆的父结点都小于等于其子结点。
第二点:数组下标和堆结点的关系。
对于有n个元素的数组a[n],其下标和堆结点的关系为:
父结点a[parent]的左右子结点分别是a[parent*2+1],a[parent*2+2], 0<= parent <= n/2-1;
数组下标从大到小看,下标为n/2-1的结点为堆的第一个非叶子结点。
假设我们现在有一个数组a[10] = {4,1,3,2,16,9,10,14,8,7},对应的二叉树为:
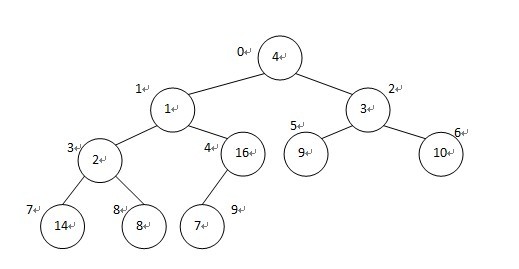
树结点外的数字就是该结点对应的数组下标。
跟结点4的下标为0,其左子结点1的下标为1,1 = 0 * 2 + 1;
其右子结点3的下标为2,2 = 0 * 2 + 2;
1的左子结点2的下标,3 = 1 * 2 + 1;右子结点16的下标 4 = 1 * 2 + 2;
3的左子结点9的下标,5 = 2 * 2 + 1; 右子结点10的下标 6 = 2 * 2 + 2;
2的左子结点14的下标,7 = 3 * 2 + 1;右子结点8的下标 8 = 3 * 2 + 2;
16的左子结点7的下标,9 = 4 * 2 + 1;
以最大堆为例,堆排序的过程就是将数组建立成一个最大堆,每次把跟结点取出来,就是最大的一个数,所以遍历完整个数组后,其算法复杂度就是O(n)*O(logn),其中O(n)是遍历数组的算法复杂度,O(logn)是调整堆的算法复杂度。
下面是c语言的实现:
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void buildMaxHeap(int a[], int parentIndex, int lastIndex)
{
int left;
int right;
int max;
left = parentIndex * 2 + 1; /* 左子结点下标 */
right = parentIndex * 2 + 2; /* 右子结点下标 */
while (left <= lastIndex)
{
max = left; /* 先假设左子结点为最大 */
/* 如果存在右子结点 */
if (right <= lastIndex)
{
if (a[left] < a[right])
{
max = right; /* 右子结点比左子结点要大 */
}
}
/* 如果父结点比子结点要小,那么子结点上升为父结点,
* 原先的父结点下降为子结点,继续重复调整
*/
if (a[parentIndex] < a[max])
{
swap(&a[parentIndex], &a[max]);
parentIndex = max;
}
else
{
return; /* 父结点比子结点都大,符合最大堆的特性,返回 */
}
/* 继续往下调整 */
left = parentIndex * 2 + 1;
right = parentIndex * 2 + 2;
}
}
/* n是数组元素的个数 */
void heapSort(int a[], int n)
{
int i;
int unsort;
/* 先将数组建立成一个最大堆*/
for (i = n / 2 - 1; i >= 0; i--)
{
/* 从最后一个非叶子结点开始调整 */
buildMaxHeap(a, i, n - 1);
}
swap(&a[0], &a[n - 1]);
/* 遍历数组,每次取一个最大的,然后调整堆 */
for (unsort = n - 1; unsort > 0; unsort--)
{
buildMaxHeap(a, 0, unsort-1);
swap(&a[0], &a[unsort-1]);
}
}
int main()
{
int i;
int a[] = {4,1,3,2,16,9,10,14,8,7};
heapSort(a, 10);
for (i = 0; i < 10; i++)
{
printf("%d ", a[i]);
}
printf("\n");
return 0;
}














 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









