






第二周周报
代码学习和总结
OS模块学习
https://www.cnblogs.com/ltkekeli1229/p/15709442.html
模块学习demo是P016_arrange_dir --→分类文件
import os
os.listdir(path) # 返回path路径下的文件名列表
os.path.isdir(path) # 判断是否为目录/判断是否存在该目录
os.path.isfile(path) # 判断是否为文件/判断是否存在该文件
os.path.getsize(文件) # 以int型返回文件的大小字节
os.path.splitext(path) # 获取文件后缀名->将路径与后缀名分开,并以元组形式返回
# os.path.splitext('/path/to/aaa.mp3')
# --> 输出 ('/path/to/aaa', '.mp3')
os.walk(path) —→学习demo是p017 按文件大小排序
python os.walk()和os.path.walk()_weixin_33834075的博客-CSDN博客
函数返回一个元组,含有三个元素。这三个元素分别是:每次遍历的路径名、路径下子目录列表、目录下文件列表,当前根目录返回完后就会以下一层目录为根目录继续迭代
import os
for parent,dirnames,filenames in os.walk("./file"):
print(parent,dirnames,filenames)

————————————————————————————————————————————
shutil模块-→作为os模块的补充
https://www.cnblogs.com/ltkekeli1229/p/15709414.html
import shutil
shutil.move(source_path,target_path) # 将source_path路径文件移动到target_path
————————————————————————————————————————————
str.startwith(‘str’) --------str.endwith(‘str’)----输出为True 或者Flase,通常用来判断字符串或者判断文件后缀,从而识别文件类型—例如例题p020就有用到。
————————————————————————————————————————————
经典例题总结
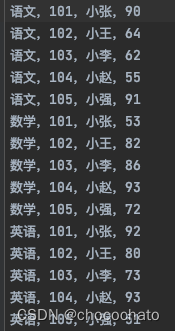
p018_分类统计实现
grade_file = '/Users/chatochoco/PycharmProjects/demo1/some/txt/grade.txt'
course_grades = {} # 由于要使用到科目和成绩,因此使用字典--> key:course values: grade
with open(grade_file) as file_obj:
for line in file_obj:
line = line[:-1] # 去掉末尾的空白,也可以用line.strip()
course, sno, name, grade = line.split(',') # 当知道str将字符串split成几段时,可以用变量直接接住
if course not in course_grades:
course_grades[course] = [] # key对应的valuse用列表形式存成绩更方便
course_grades[course].append(int(grade))
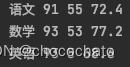
for course, grades in course_grades.items(): # .items()遍历字典
print(course,
max(grades),
min(grades),
round(sum(grades) / len(grades), 2)
)
————————————————————————————————————————————
p019_不同文件之间的关联
course_teacher = {}
with open('/Users/chatochoco/PycharmProjects/demo1/some/txt/teachers') as file_obj:
for line in file_obj:
line = line.rstrip()
course, teacher = line.split(',')
course_teacher[course] = teacher
with open('/Users/chatochoco/PycharmProjects/demo1/some/txt/grade.txt') as file_obj:
for line in file_obj:
line = line[:-1]
course, sno, name, grade = line.split(',')
teacher = course_teacher.get(course) # 获取字典的values有两种方式
print(course, teacher, sno, name, grade)
两个文件有course作为连接,因此在文件1中用字典类型存下来键值对方便文件2中通过course作为key来访问字典中的values
————————————————————————————————————————————
p020_txt文件的整合
import os
file_name = '/Users/chatochoco/PycharmProjects/demo1/some/txt'
content = []
for file in os.listdir(file_name):
file_path = f'{file_name}/{file}'
if os.path.isfile(file_path) and file.endswith('.txt'):
with open(file_path) as file_obj:
content.append(file_obj.read())
final_content = '\n'.join(content)
print(final_content)
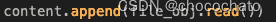
这里不直接用content.append( ‘\n’.join( file_obj.read() ) )的原因是’str’.join(内容),当内容是列表时,分割的是列表的每个’str1’,而当join内容是一段字符串,那么会以\n来分割每个单字符
p021_统计每个兴趣的学生人数
file_path = '/Users/chatochoco/PycharmProjects/demo1/some/txt/stu_like.txt'
stu_like = {}
with open(file_path) as file_obj:
for line in file_obj:
line = line.rstrip()
stu, likes = line.split(' ') # 分别接住split,此时返回的likse是一段字符
likes_list = likes.split(',') # 拆开likes的多种爱好,返回的likes_list 是一个一个爱好列表
for like in likes_list:
if like not in stu_like:
stu_like[like] = []
stu_like[like].append(stu)
else:
stu_like[like].append(stu)
print(stu_like)
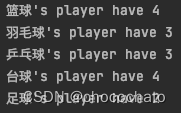
for like, stu in stu_like.items():
num_player = len(stu)
print(f"{like}'s player have {num_player}")

————————————————————————————————————————————
英文文献学习-ImageNet Classification with Deep Convolutional Neural Networks
摘要大概意思总结:
作者训练了很牛的卷积神经网络用来对120万张图片做了1000个分类。在测试集上面,top1和top5的错误率是37.5%和17.0% 。这个神经网络有6000W个参数和65W个神经元,有5个卷积层,一些最大值池化层,3个全链接层。然后作者为了提速又使用了GPU,为了减少过拟合,作者又使用了一种叫做“dropout”的正则办法。然后作者又把这个模型放到12年的一个竞赛中,得到的错误率是15.3%,相比第二名的26.2%很牛。
1、介绍
大概意思讲作者做了一个新的网络,然后在模型很大的情况下,如何利用GPU加速(在架构中看是将数据集切割,用两张GPU来训练),如何避免过拟合,跟摘要一样描述了一下神经网络的情况,5个卷积层,一些最大值池化层,3个全链接层。然后强调了一下在第三章第四章是重点创新部分。
2、数据集
作者表示有1500W的数据,然后有两万类。作者特别强调数据集是没有经过任何预处理,是直接利用原始图片,从中心点往两边裁剪reshape到256X256。
3、网络的架构
作者觉得很重要的点包括:
3、1在标准的神经网络里面的激活函数用的是tanh或者是sigmoid,但由于tanh或者sigmoid这类饱和的非线性激活函数比非饱和的非线性函数要慢。(百度的时候了解到ImageNet在作者发这个文章的时候训练是很贵的,所以速度就很重要),所以作者用到了ReLU。
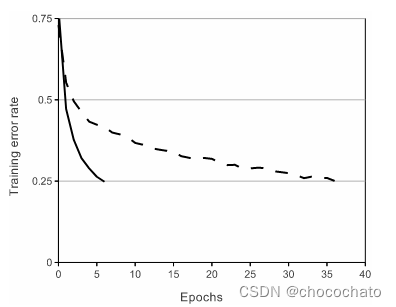
如上图所示,虚线是tanh,ReLU是实线部分。这个ReLU在后面深度学习卷积的时候有笔记介绍。
3、2作者在当时只有一个3GB的GTX580,但是数据集特别大,所以在3.2部分主要讲了如何用多个GPU来做训练。
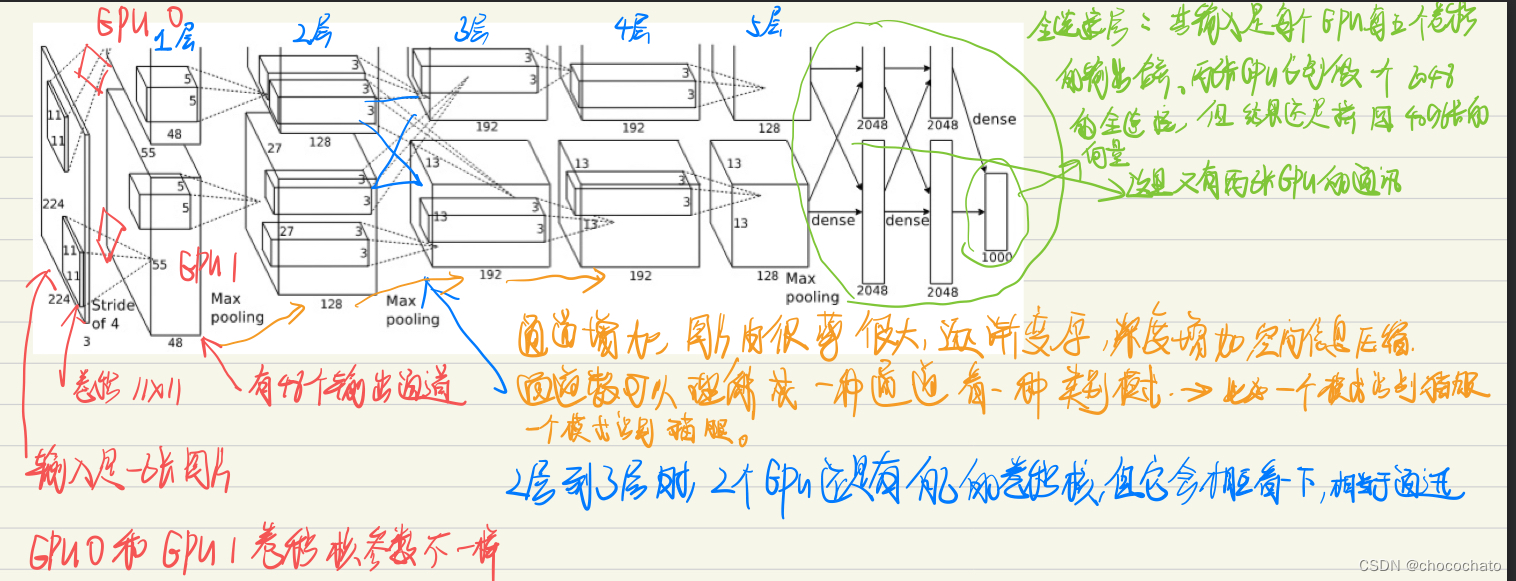
上面是对原论文中架构的解析。整个过程可以理解为把人能看懂的像素,通过特征提取,变成了一个4096的机器能看到的东西,这个东西既可以用来做各种搜索,也可以做分类之类的事情。那么薄那么大的一个图片,通过中间的一个模型压缩成一个向量,然后机器就可以识别,从而实现各种分类、搜索之类的工作。
4、怎么做到避免过拟合
前两种方法不太理解,所以我主要记录一下第三种Dropout方法。大概意思是随机的把隐藏层的输出50%的概率设为0,在作者的训练过程中发现有Dropout的话训练速度会慢两倍,没有Dropout的话,过拟合就很严重
实验结果:
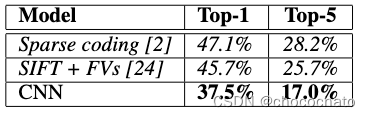
作者的结果跟别人结果对比可以发现,在top-1、top-5的错误率上明显有优化。

图一是一个分类正确率结果表示,图二是作者将倒数第二层的输出拿出来得到的一个长的向量,大概意思就是最后一层靠的很近的一些图片基本都是差不多的,相似的图片都会放分类到一起。
结论大概总结:
作者的结果显示,一个很大很深的卷积神经网络对于高难度的数据集上面能够做到一个特别好的结果,但是当减少一层神经网络,它的整体性能就会下降2%,所以作者认为网络的深度是很重要的。(网上有视频讲解这篇经典论文,意思说可以通过去掉一些层,然后把中间参数调一下也是可以实现五层时候的错误率)作者认为在当时的的IMAGENET上做的跟人的能力相比还是有很大的差距,作者展望了一下训练Video,前提是有钱有数据(网上有说这篇论文提到的 Video,意思音频中有很多时序的信息,时序的信息能够理解到空间的图片信息)。
卷积神经网络原理学习
输入
只要数据能够变成图像形式,都可以通过卷积神经网络来处理,类似音频、图像、文本等。
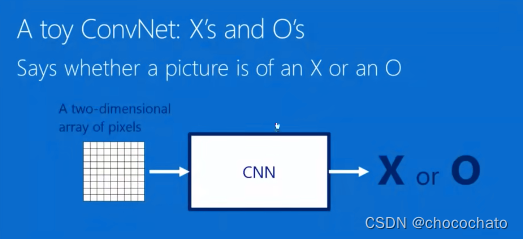
卷积神经网络可以说是一个函数,一个黑箱。其输入是一个二维像素阵列,输出就是图片是什么。
卷积:
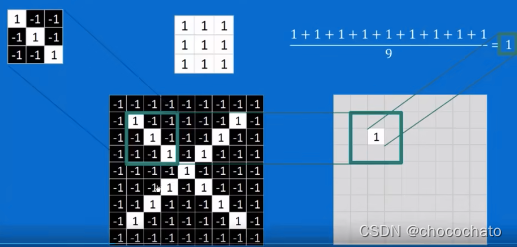
卷积核( 在这里先假装是自己选择特征)跟绿框进行判定:对应位置相乘相加/9,结果为1。这就表示图中绿框部分跟卷积核特征完全一样。
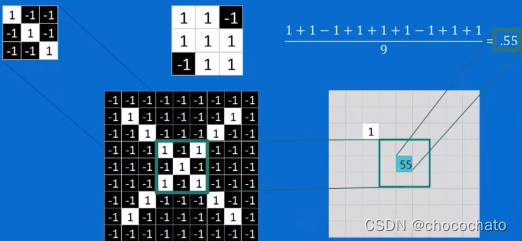
卷积核跟绿框进行判定:此时结果为0.55。这就表示虽然绿框跟卷积核不完全一致,但仍然有0.55卷积核的特征。

用卷积核对整个图形进行扫描后得到右边的结果。这就表示原图中包含卷积核的这类特征被卷积核提取出来到feature map,颜色越深表示符合度越低,1就是被提取出来的。像上图所示,就表示原图包含这类特征。
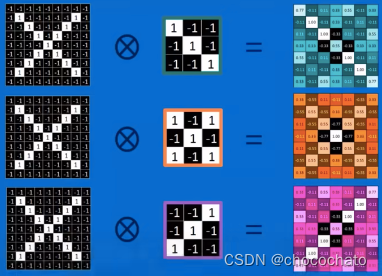
用不同的卷积核对原图扫描,得到右边的feature map,发现跟卷积核很相似,这就表明原图确实包含卷积核的特征。
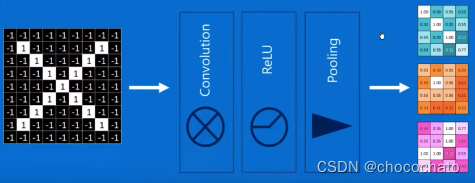
池化(下采样、Pooling:Shrinking the image stack):
对得道的feature map进行缩小。比如在自动驾驶的过程中要对人脸进行识别,不可能在短时间内用几万个卷积核对原图进行处理得道几万个feature map,这计算量是特别大的,不可能在毫秒级内完成。
池化在保持原图特征的情况下,还能把尺寸降下来。包活下图中的两种:
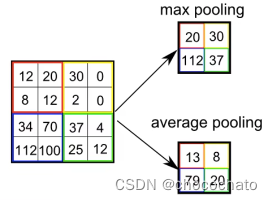
一个最大池化:把最大值取出。例如下图中的最大池化过程

由于步长是2,在边角的地方会补一圈0来提取边缘特征(zero padding),这是为什么右下角池化后取了0.77。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gVdcHiK1-1664119701360)(%E7%AC%AC%E4%BA%8C%E5%91%A8%E5%91%A8%E6%8A%A5%2078ad93f1-e000-47f0-9dc8-281b9beb6e29/%E5%9B%BE%E7%89%87%2018.png)]](https://img-blog.csdnimg.cn/eaf0f2fb869c4daa82a7ca0c51db7cbc.png)
上面卷积结果的feature map经过最大池化后得到的特征如图。可以看到特征仍然保持。
ReLUs:Rectified Linear Units(修正线性单元)
y在x<0时为0,在x>0时为x—→把所有负数化为0。目前学习的内容感觉ReLUs最大的好处就是带来计算方便。
卷积、抹零、池化作为一个单元可以多次重复。
全链接层
把得到的feature map 取出搞成一列

每个像素都有一个权重,比如对应X时可能0.9的权重更大,比如将权重乘以像素上的值求和,得到为X的概率为0.92。全链接层可以放很多层,类似下图就放了两层。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YPT4NZgJ-1664119701363)(%E7%AC%AC%E4%BA%8C%E5%91%A8%E5%91%A8%E6%8A%A5%2078ad93f1-e000-47f0-9dc8-281b9beb6e29/%E5%9B%BE%E7%89%87%2021.png)]](https://img-blog.csdnimg.cn/2f83dc3d160f4763948b898f9c4aa9c6.png)
卷积-→抹0→卷积→抹0→下采样→卷积→抹0→下采样→全链接→全链接。
训练
至于为什么某个地方它的权重大、卷积核又该如何选择,这就需要训练。反向传播—→通过喂大量的数据,得到Backpropagation,即神经网络得到一个结果,把这个结果跟真实结果对比。比如识别一个男人的照片却识别为一个女人,那么把真实结果跟神经网络的结果对比得到一个误差→即损失函数,训练的目标就是得到损失函数的最小值。数学上的求导能得到最小值,所以我们不断通过调节卷积核的参数,全链接中的权重,使损失函数最小 ,由于它会一层一层把误差返回,因此叫反向传播算法。 之前写卷积笔记的时候提到了卷积核,其实卷积核是在不断训练中机器自行选择的,这也就是为什么机器具有了学习能力,人只需要提供大量的数据喂,它会不断调节,梯度下降、损失函数越来越小。
总结:
这周用python做了一些实用的项目,学习了很多模块常用的一些函数方法。最大的问题还是读文献很多问题,一篇英文文献读了很久很久,包括这周读的这篇,3.4 3.5部分还是不懂,论文中的神经网络架构也是懵懵懂懂看不太懂,还需要再读一遍才能搞懂。然后网课学习了卷积神经网络,这部分还是基本听懂了。下周计划是把这篇论文再精读一遍,把这周没看懂的公式再读一遍,特别是SGD部分的公式之类的。















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









