






Spring Boot 2.0.3-webflux-上手教程
StackTrace
开始
Webflux是响应式开发框架,由Spring boot 2.0开始对响应式编程进行了支持;在此之前,响应式主要在前端的开发上有体现,大Java社区为了争上这口气,从该版本开始正式踏入响应式编程的行列;Spring boot2.0-webflux对JDK有要求,必须使用JDK8以上、默认使用的容器是netty,spring使用spring5的版本,且不支持关系型数据库(例如:mysql);
在国内的万岁长城封堵下,网上提供的一些中文资料比较零散,而且有一些问题需要翻墙到国外才可找到;写这篇博文,一方面是总结之前在使用webflux做项目踩过的坑,一方面也想通过此篇文章,让想接触响应式开发的兄弟姐妹们可快速上手学习;
示例工程是基于接口的请求方式进行描述的,暂不涉及界面开发(例如:thymeleaf)与Websocket、SSE(https://www.ibm.com/developerworks/cn/java/spring5-webflux-reactive/index.html)。
本文章中的示例代码工程已上传至码云:https://gitee.com/hom_git/spring-boot2.0.3-webflux-demo
博客中的图片不能引用外部链接上传,如需要查看图片,请跳至:https://gitee.com/hom_git/spring-boot2.0.3-webflux-demo/wikis/pages
基础
性能比较
开始学习之前,先看看webflux在性能上带来的优势。
下面性能比较使用的框 架分别是:“spring mvc + tomcat”与“spring webflux + netty”框架,相关的测试环境描述如下:
-
系统:
windows10_64位
-
工具:
ApacheBench、JConsole
-
测试场景:
并发数:2000
总请求数:20000
接口功能:程序休眠2秒,返回hello
结果如下:
-
并发数:

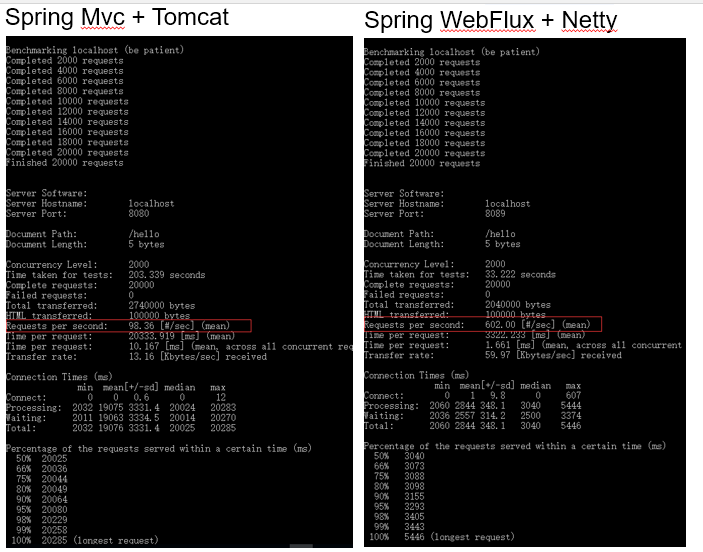 图一
图一图一的左图的RPS是98.36,代表每秒能处理的请求数;右图的RPS是602;
-
线程数:
 图二
图二图三
众所周知,tomcat的默认最大线程数是200,故图二中,当tomcat上到了200后就没有再继续增加线程;而netty的优势通过图三就可以看到,只需要使用少量的结程就可以达到很好的效果; 通过图一、二、三就可以看到,在初始的默认工程环境下,同样的请求数,同样的系统,webflux+netty的优势是非常明显的,单凭这一点,响应式编程就值得学习;另外,初步来看,spring cloud的相关组件,不少也是基于响应式(reactor)开发出来的,有兴趣的同学,可以看看gateway的源码。
推荐文章
Webflux,看它的源码就会发现,大量的使用了jdk8的新特性(lambda与流)与响应式编码,在开动前,需要先了解这两方面的知识;有位前辈对这块的上手文章写得非常好,强烈推荐,地址如下,一定要了解何为订阅,响应式是在什么场景触发才会执行:
[http://blog.51cto.com/liukang/2090163](http://blog.51cto.com/liukang/2090163)创建项目
看完基础篇推荐的文章后,基本对这块已经有一定的了解,就可以直接开始搭建项目;推荐使用idea的自动生成webflux工程项目的方式(如果有同学想亲手加包,也可以在创建好maven工程后,手工一个个的将相关的包加进去),自动生成的示例如下:
-
lombok是一神器,非常好用,省下了不少创建bean的时间,spring boot中的源码也是使用此框架;
-
加入Validation,是为了在后面的实际工程演示中支持参数校验而添加的;
-
Reactive Web就是webflux的包;
-
由于webflux暂只支持nosql类型的数据库,故此处添加的redis与mongodb的包都是reactive,即响应式代码包;
注意:如果通过spring.io创建初始工程时,如果看不到相关的包或者工程创建好后,maven导不进包,此时,尝试下翻墙后再试;
点击上图next,设置好项目的保存路径,就完成了webflux的初始项目搭建,如下图,可以看到初始导入的maven包,此处自动创建的方式有个好处,默认会使用spring boot最新的发布版,省去了去找版本的时间:
图四
启动运行项目后,从日志中可以看到,使用的容器是netty:
图五
注意:图五的左上角,默认创建的工程目录,这里有小坑:DemoApplication.java这个类不是在默认的classpath(com.example.webflux)目录下,这会导致后续新创建的需要spring注入的类会扫描不到,有两种解决方案:-
在DemoApplication.java的启动类上添加注解@ComponentScan("com.example.webflux"),让工程在启动时,自动扫描此目录下的类;
-
修改DemoApplication.java的路径,将它移至classpath目录下;
推荐使用第二种方案,使用第一种方案的话,如果存在多个不同扫描路径或者引用了同样包路径的工程时,注解的方式就会变得冗肿或者烦躁,且不好维护。
初始工程创建好后,下面就进入编码。
示例编码
响应请求
Webflux支持两种请求处理风格,分别是:
- 1. Spring mvc的方式,通过声明Controller与RequestMapping的方式,如下示例代码:
图六
图七
从图六中可以看到,创建了IndexController.java类,以常用的MVC的方式进行声明,留意启动日志,对应的请求路径“/hello/mvc”已经绑定,浏览器可以正常请求; 注意:RequestMapping标注的方法返回类型已改成Mono类型(什么是Mono,请查看上手篇中推荐的文章);经过测试发现,返回类型即使不是Mono类型,请求一样可以处理;
另一种方式则是webflux的函数式定义方式,如下:
图八
图九
-
2. 函数式方式的路由定义的流程说明:
先定义请求处理类(IndexHandler)->定义路由(WebConfig.indexApiRouter)->建立绑定关系(说明indexHandler的哪个方法处理哪个Url,接口是以什么方法调用的,参数是以什么格式传输的);注意事项:
- 请求处理类需声明为spring的容器类,使用了注解@Component;
- 路由的方法需要返回指定的类型“RouterFunction”;
- handler的处理方法也一样,需要返回指定的类型Mono与指定的入参ServerRequest;
如不按此规定,则对应的请求不会被处理,特别是handler的请求处理方法的入参类型必须为ServerRequest;我刚学习的时候,不知这规定,以为webflux可以像spring mvc那样,以对象的形式注入参数,结果修改了参数类型后,对应的url一直无法响应处理,新手一定要注意此坑。
配置
本地机器安装了mongodb与redis,都没有设置密码,故可以直接连接;如对应项有增加用户认证的机制,请自行增加用户名与密码的配置; 修改全局的关于json序列化的配置,spring boot2.0默认使用“fasterxml.jackson.databind”;经过初步尝试发现,阿里的fastjson暂不支持webflux的全局json序列化设置。json的配置主要添加对日期型的格式化,jdk8新增了LocalDateTime的格式,示例代码中的日期类型使用该类,需要格式化后才能支持参数类型转换,且同时添加mongodb的objectId类型的序列化格式转换配置,如下:
传参、新增、查询
基于上面的工程与配置,下面为示例添加方法“IndexHandler.add”,对应的url为“/hello/webflux/add”,并且创建一个vo类User,步骤如下:
1.新增User类
上图中的@Data、@ToString、@NoArgsConstructor是lombok提供的注解,@Data表示在编译时,会自动生成被标记的类的属性的getter与setter方法,另外两个见名思议;@Document是mongodb的包提供的,标识此类为集合对象(即mysql中对应的表);2. 增加“IndexHandler.add”方法与绑定URL,并且注入mongodb的操作类,为了方便演示,示例代码中并没有区分service层与dao层,操作都在handler上执行:
注意:此处注入的mongo操作类,是mongo响应式包中的ReactiveMongoTemplate;另外,要从请求流中获取POST的传参,必须要使用request.bodyToMono的方式才可以;如需要获取URL中的参数,则使用request.pathVariable()方法即可。3.编译启动运行,使用restFul的工具请求接口,结果如下:
上面的红框是请求对象,下面的是返回结果已包含ObjectId的值(通过配置章节中讲到的ObjectId序列化配置,可转换为字符串返回),对应mongo中的文档如下:
4.第“2”步骤中讲到的add方法的写法看上去和普通的命令式编程方式没什么区别,实际上在框架底层,Mono类修饰的语句已经转换成响应式的实现,一定要注意,方法在无订阅操作或阻塞时,语句中的实际操作是不会执行的,如下举例:
上图中的第3步返回的是一个新创建的user对象,此时在程序运行过程中,第1步与第2步中对user的操作是没有执行的,因为这两步的mono类并未有订阅;上述的写法是偏向于命令式的写法,可将它转换成流的写法,如下addStream方法:
当代码逻辑较多时,这种写法对于代码结构亦会比较简洁,而且也符合响应式编程强调的函数式编程的方式。
5.实现查询方法“IndexHandler.list”,绑定URL“/hello/webflux/list”,在查出来的结果中,需要将所有记录的age加1再返回,在实现之前先往user集合中插入多条记录(name与createTime是升序排列的),如下:
代码实现的方法如下:
注意:上图一中的“reactiveMongoTemplate.find(query, User.class)”中返回的是Flux对象,当调用Flux.flatMap方法时,flatMap内部使用的是多线程的处理方式,即处理后的列表对象有可能已经变成乱序,如需要保证返回结果是有序性的,则需要改成用flatMapSequential方法,如下:上图中的Query是spring-data-mongo包中的对象,具体使用方法可查阅网上资料。
运行并调用后的结果如下:
Redis操作
在配置的章节已经添加了redis的配置,此处直接添加操作redis的功能,实现功能:在新增用户时,将成功插入mongo中的用户同时插入redis中,key为用户的id字符串,value为用户对象序列化后的json字符串信息,添加“IndexHandler.addStreamRedis”方法,如下:
上图中,注入了响应式的redis操作类“ReactiveRedisTemplate”,并且在执行oprForValue时声明了序列化的方式为字符串,如果想全局定义“ReactiveRedisTemplate”的序例化格式,可以将此类定义成spring的容器类,让它在启动时,自行注入并加载,这样就不需要每次在操作时添加序列化的格式;obj2Json是手工将对象转换成Json字符串的方法。注意:redis的操作,必须声明序例化的格式,否则在插入redis中,将会是一串字节码,此时通过json的方式是无法查看,并且key会是乱码。
执行后,可看到redis中已添加该记录:
从图中可以看到在redis中,user对象的json字符串的id值与createTime值包含了其它额外的信息,如果只想实现保存字符串的话,可以修改obj2Json的代码,添加类似配置章节中添加的格式即可,修改obj2Json的代码如下:
此时,redis中的结果如下:
Redis的查询方法类似,在此不作举例。
高级玩法
-
流的窥听
响应式编写方式的代码只有在被订阅或者手工调用阻塞的方法时,才会执行,如果想查看flatmap执行后的流转日志时,可以通过在flatmap方法后增加.log的方法打印出流转日志:
上图就是log方法前面对应的flatmap的执行日志;
另外,reactor本身提供了一些窥探的方法,例如:Mono\[doOnSubscribe、doOnError、doOnSuccess……\],这些方法可以供输出转换流后的对象信息,并且不会消费流的内容,从而避免使用窥探方法后的其它处理无法获取到对象的情况:
doOnSubscribe,表示方法被订阅时执行的动作;
-
如何添加响应时间
如果要统一为每个请求都添加进入时的时间与结束处理后的时候时,可以通过添加统一过滤器进行处理,而无需为每个请求添加同样的逻辑。
webflux没有拦截器,它只有过滤器,在过滤器中可以处理例如:鉴权,请求时间的统一打印等等。实现WebFilter接口就可以创建自定义的过滤器,但要注意filter的order顺序,顺序值越小,越先执行:
-
全局异常的拦截
添加全局异常有两种方法:
-
在webflux.filter中添加onErrorReturn的方法,将返回值写到response即可:
在“/hello/webflux/list”方法中使用Mono.error方法抛出异常进行测试:
-
实现默认的错误属性类DefaultErrorAttributes与AbstractErrorWebExceptionHandler:
注意:经过测试发现,当实现了A方式后,如果同时也实现B方式的话,则B方式会无效,请求里面的处理都被A方式拦截了。建议:采用B方式,这样可以统一处理所有的异常,而不需要依赖指定的filter。
-
-
## 如何添加全局变量
在webflux,ThreadLocal这种线程变量是不可用的,特别是在flatmap处理列表的时候。如果要共享线程变量,可以通过下述的两种方法实现:
-
将需要共享的变量作为方法参数传入,修改“/hello/webflux/addStream”对应的方法,添加字符串“Test.”,将User.Name的值修改为“Test.” + User.Name:
-
使用webflux流共享变量(Context)的方式,修改“/hello/webflux/add/redis”方法,添加字符串“Test.SubscriberContext.”,将User.Name的值修改为“Test.SubscriberContext.” + User.Name:
注意:B方式中的subscriberContext(Context.of("share_str", "Test.SubscriberContext."))要放在入口方法的流末尾处,这样才代表该处理逻辑中共享此上下文变量,因为subscriber代表从方法头开始生效。如果上下文定义的位置有误,在获取相应的相下文变量时,则会出现“java.util.NoSuchElementException: Context is empty”异常。
建议:使用B方式,减少像A方式中的代码侵入。
-
如何校验参数
Spring boot 2.0.3的webflux的函数式路由方式不支持JSR3(Validater)的验证方
式,如果仍然想继续使用这种参数验证方法,需要手工调用验证方法才可以实现:
修改“/hello/webflux/addStream”的方法,为User.Age添加入参值的校验,该值的范围必须为“1-18”:
注意:上图的Default.class,表示使用Validation的默认分组验证方式,如不同的场景下校验不同的入参时,自定义一个分组验证接口类作为标识即可。具体可查看网上关于Validation分组验证规则。
总结
至此,webflux的基本用法已介绍完毕。
注意:在开动之前,一定要认真熟习JDK8新特性与reactor的用法,不然在实际使用时会懵圈。














 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









