







实践出真知,否则快速遗忘。
今天是放假以来最充实、最踏实的一天。
自定义Dataset和DataLoader的两种方法
在处理任何机器学习问题之前都需要数据读取,并进行预处理。Pytorch提供了许多方法使得数据读取和预处理变得很容易。
- torch.utils.data.Dataset是代表自定义数据集方法的抽象类,你可以自己定义你的数据类继承这个抽象类,非常简单,只需要定义** __ len __ ** 和 **__ getitem __**这两个方法就可以。通过继承torch.utils.data.Dataset的这个抽象类,我们可以定义好我们需要的数据类。
- 当我们通过迭代的方式来取得每一个数据,但是这样很难实现取batch,shuffle或者多线程读取数据,所以pytorch还提供了一个简单的方法来做这件事情,通过torch.utils.data.DataLoader类来定义一个新的迭代器,用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入。
总之,通过torch.utils.data.Dataset和torch.utils.data.DataLoader这两个类,使数据的读取变得非常简单,快捷。
import numpy as np
from torch.utils.data import Dataset,Dataloader
# 自定义dataset
# method one
class MyDataset(Dataset):
# 也可以定义其他函数,如取数据等
def __init__(self,training=True):
self.data = list(range(1000))
self.label = list(np.random.randint(0,10,size=1000))
def __len__(self):
return len(self.data)
def __getitem__(self,idx):
return (self.data[idx],self.label[idx])
trainloader = Dataloader(MyDataset, batch_size=1, shuffle=False, num_workers=0, drop_last=False,worker_init_fn=None)
# method two
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
batch_size = 10
# combine featues and labels of dataset
dataset = Data.TensorDataset(features, labels)
# put dataset into DataLoader
data_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # whether shuffle the data or not
num_workers=2, # read data in multithreading
)
定义网络模型的四种方法
几种简单方法
# method one
net1 = nn.Sequential(
nn.Linear(num_inputs, 1)
# other layers can be added here
)
# method two
net2 = nn.Sequential()
net2.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ......
# method three
from collections import OrderedDict
net3 = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
]))
'''将以上三种方法放到class中也可以产生三种方法'''
# method four
class net4(nn.Module):
def __init__(self, n_feature):
super(net4, self).__init__() # call father function to init
self.linear = nn.Linear(n_feature, 1) # function prototype: `torch.nn.Linear(in_features, out_features, bias=True)`
def forward(self, x):
y = self.linear(x)
return y
net = net4(num_inputs)
# method five
class net5(nn.Module):
def __init__(self):
super(net5, self).__init__()
self.layer = nn.Sequential(
Conv2d(3, 3, 1),
Conv2d(3, 3, 1)
)
def forward(self, x):
return self.conv1(self.conv2(x))
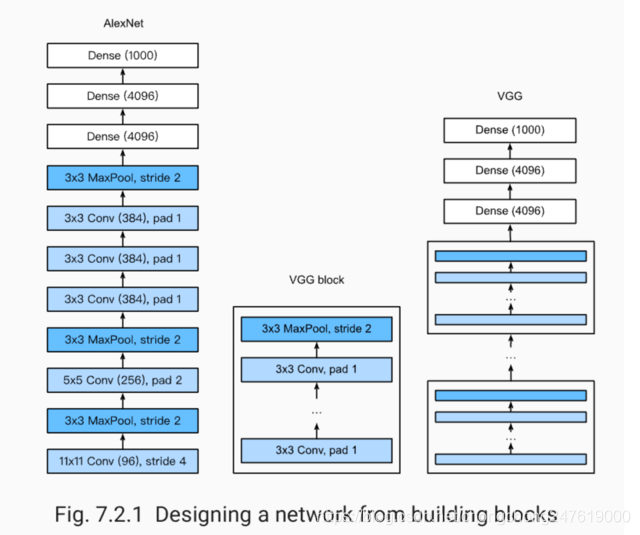
网络中嵌套block
# 第一种,网络中嵌套block(VGG)
def vgg_block(num_convs, in_channels, out_channels): #卷积层个数,输入通道数,输出通道数
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 这里会使宽高减半
return nn.Sequential(*blk)
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
# 每经过一个vgg_block都会使宽高减半
net.add_module("vgg_block_" + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
# 模型初始化
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7 # c * w * h
fc_hidden_units = 4096 # 任意
net = vgg(conv_arch, fc_features, fc_hidden_units)
X = torch.rand(1, 1, 224, 224)
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
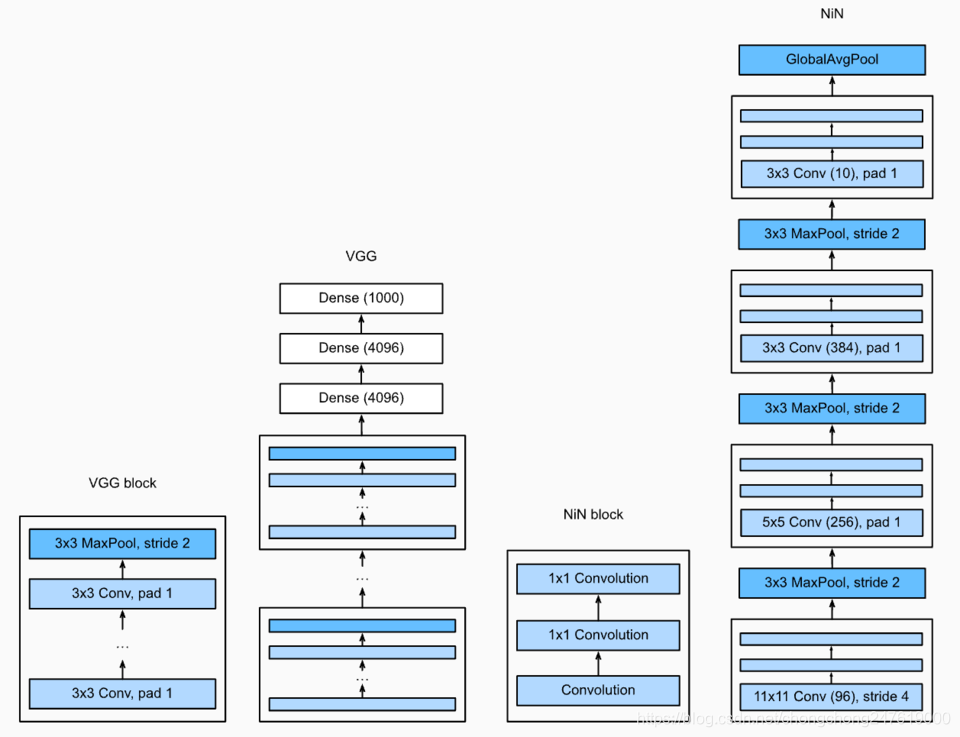
NiN
# 第二种:NiN(Googl)
def nin_block(in_channels, out_channels, kernel_size, stride, padding):
blk = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU())
return blk
# 已保存在d2lzh_pytorch
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, stride=4, padding=0),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(96, 256, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=3, stride=2),
nin_block(256, 384, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, stride=1, padding=1),
GlobalAvgPool2d(),
# 将四维的输出转成二维的输出,其形状为(批量大小, 10)
d2l.FlattenLayer())
X = torch.rand(1, 1, 224, 224)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









