






一.Hadoop 1.X 和 Hadoop 2.X
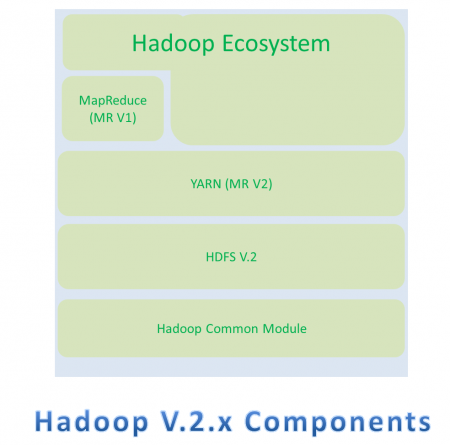
Hadoop 1.X 的组件,主要有两个
- HDFS (HDFS V1)
- MapReduce (MR V1)

Hadoop 2.X 的组件,主要有三个:
- HDFS V.2
- YARN (MR V2)
- MapReduce (MR V1)
Hadoop 1.X 的局限:
- 只适合大量数据的批处理操作
- 不适合实时的数据处理
- 不适合数据流处理
- 每个集群最多支持4000个节点
- JobTracker 一个组件做了很多事情:资源管理,作业调度,作业监控,重新调度作业。
- JobTracker 存在单点故障
- 不支持多租户(Multi-tenancy )
- 一个集群只有一个DataNode 和 NameSpace
- 不支持水平扩展
- 只能运行MR的作业
- 使用Slots 来分配资源(内存,CPU等),而且是静态的MAP和静态的Reduce,一旦给MR 的作业分配了资源就不能重用,即使Slots 是出于空闲状态。
eg:10 个map作业和10个Reduce作业正在使用10+10个slots运行计算,所有的Map 作业正在运行,而所有的Reduce作业出于空闲状态,我们不能使用这10个Slots 来做其他的事情。
总之,Hadoop1.X 系统只是一单个目标的系统,我们只能用于基于MR 的应用。
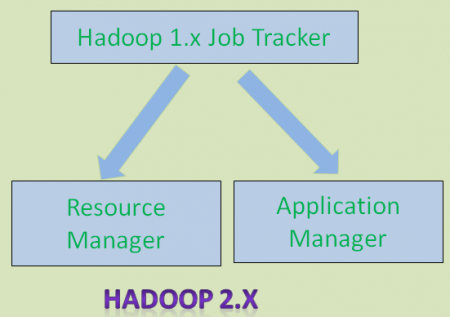
在 Hadoop 2.X 为了解决1.X 的这些局限问题,提出了新的组件YARN (Yet Another Resource Negotiator).

Hadoop 1.X Job Tracker :被分为两个组件
- Resource Manager:管理资源
- Application Master:管理应用(MR,Spark等)
- Hadoop 1.X 只有一个命名空间,而2.X 有多个
- Hadoop 1.X 只有MR 一个编程模式,而2.X有多种(MR,迭代,流式,图,Spark,Storm等)
- Hadoop 1.X 存在扩展限制,而2.X 解决了这些
- Hadoop 2.X 支持多租户,而 1.X 不支持
- Hadoop 1.X 使用确定大小的Slots进行存储,而Hadoop 2.X 使用可变的容器
- Hadoop 1.X 一个集群最多支持4000 个节点,而Hadoop 2.X 最多支持10000个节点
Hadoop 2.X Yarn 的好处
- 高扩展
- 高可用
- 支持多个编程模型
- 支持多租户
- 支持多个命名空间
- 提高了集群的利用率
- 支持水平扩展
二.Hadoop 2.X Yarn
YARN 有三个主要组件:
- ResourceManager
- NodeManager
- ApplicationMaster
- ResourceManager
该进程在主节点上(且不一定非的在NameNode上)
给不同的计算机应用程序以最佳的方式提供资源
协调Scheduler 和ApplicationManager
Scheduler
- 该进程在主节点上(和ResourceManager一起运行)
- 调度JOB的执行(通过ResourceManager接收到的提交请求)
- 给已经提交到集群的应用分配资源
- 和ApplicationManager协调,并且保持对正在运行的应用的资源进行监控
ApplicationManager
- 该进程在主节点上(和ResourceManager一起运行)
- 帮助Scheduler 协调监控正在运行的应用
- 接收来自客户端的执行请求
- 协商第一个容器Container,使用适合的ApplicationMaster(从节点上),来执行应用的特定任务,
2.NodeManager
- 该进程位于从节点(和DataNode进程一同运行)
- 管理和执行容器Container
- 监控资源使用情况(CPU,内存,网络等),并把情况报告返回给ResourceManager
- 周期性地发送心跳信息给ResourceManager,更新他的健康状态
3.ApplicationMaster
- 该进程位于从节点上(和NodeManager进程一同运行)
- 每个应用有一个具体的库和NodeManger一起工作来运行任务
- 此进程的每个实例即是一个应用,这意味着假如有多个提交的Job,则会有多个ApplicationMaster实例
- 通过ResourceManager在从节点上获取合适的资源容器
- 和一个或多个NodeManager一起工作,来监控从节点的任务执行情况
什么是容器(Container)?
- 一个很小的资源单元(CPU,内存,硬盘),位于从节点上
- Scheduler 进程和ResourceManager 进程一起运行对容器进行资源分配
- 通过Yarn 执行一个Job的初始阶段,容器允许ApplicationMaster进程在集群的从节点上利用一些资源
- Application通过在Yarn集群从节点的其他容器来来管理应用的执行。
Yarn 的架构
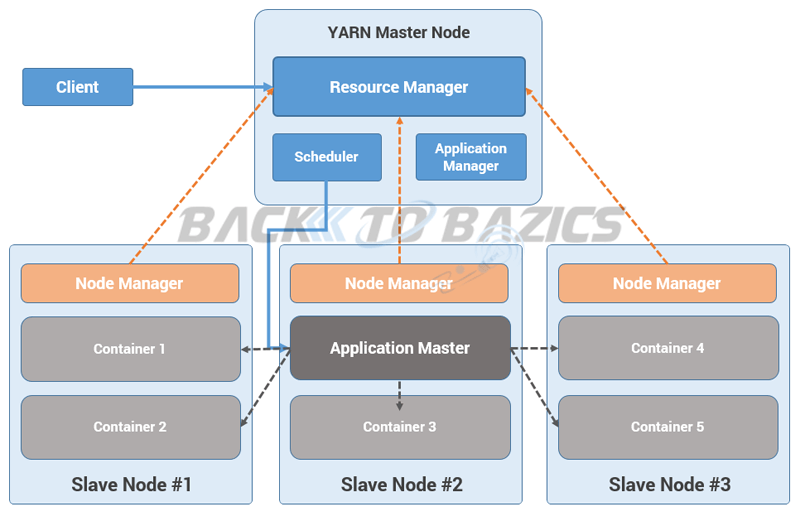
Step 1:Job/Application(可以是MR,Java/Scala应用,spark的DAGs作业等)通过Yarn应用的客户端提交到ResourceManager,与此同时,在NodeManager的任何容器中启动ApplicationMaster
Step 2: 在主节点上的ApplicationManager进程验证已提交的任务请求,并且通过Scheduler进行进行资源的分配
Step 3: Scheduler进程给在从节点上的ApplicationMaster分配一个容器
Step 4:NodeManager这个守护进程启动AppcationMaster服务,通过第一步的命令,在其中一个容器当中
Step 5:ApplicationMaster通过ResourceManger谈判协商其他的容器,来提供一些细节,诸如从节点的数据位置,请求的CPU,内存,核数等
Step 6:ResourceManger分配最合适的从节点资源,并且通过节点细节或是其他细节信息响应ApplicaionMaster
Step 7:ApplicationMaster 给NodeManager(建议的从节点上)发送请求,来启动容器
Step 8: 当作业执行是,ApplicationMaster管理已经请求的容器的资源,并在执行完成后通知ResourceManger
Step 9: NodeManagers周期性的通知ResourceManger,节点的可用资源的当前状态信息,这个信息可以被scheduler 在集群中的其他应用所使用。
Step 10: 如果在从节点上有任何的失败,ResourceManager 将会试着在最合适的节点上分配新的容器,那样 ApplicationMaster 能够在新的容器中完成相应的处理操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









