






机器学习概论
简单记录机器学习的发展史:
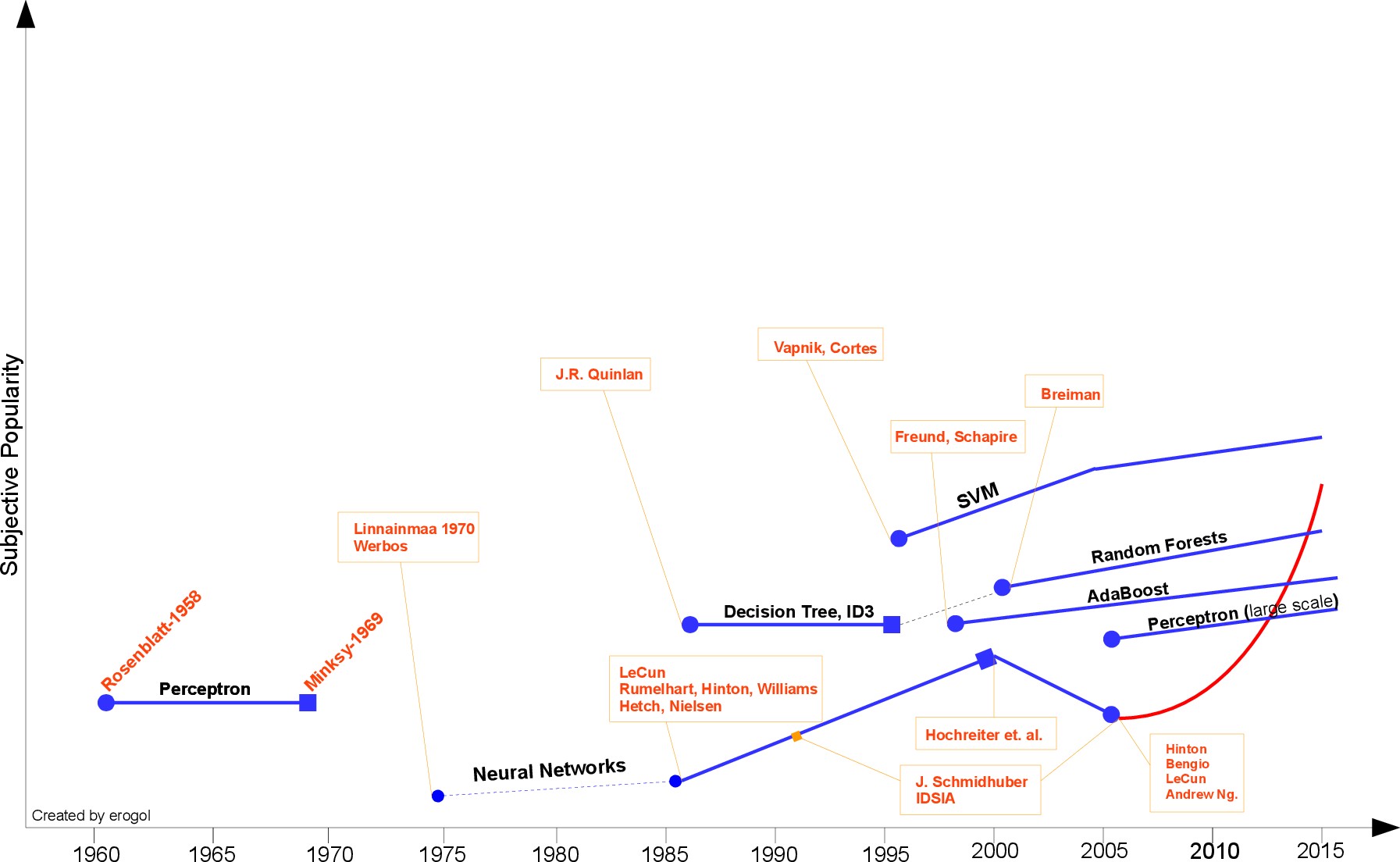
二十世纪五十年代到七十年代:推理期
“逻辑理论家”程序、“通用问题求解”、跳棋程序
连接主义(神经网络:感知机、Adaline)
二十世纪七十年代中期开始:知识期
符号主义(结构学习系统、基于逻辑的归纳学习系统、概念学习系统)
决策理论(学习技术、强化学习技术)
统计学习理论
二十世纪八十年代
符号主义:决策树,以信息熵的最小化为目标
基于逻辑的学习:归纳逻辑程序设计(ILP)
二十世纪九十年代
连接主义学习:基于神经网络的(BP)
统计学习:支持向量机(SVM)、核方法
二十一世纪初
深度学习:多层神经网络
重要定理结论:
1、“没有免费的午餐”原理:不同算法的期望性能相同(问题的出现机会相同的条件下)。
2、“奥卡姆剃刀”原则:若有多个假设与观察一致,则选最简单的那个。
3、统计学通过机器学习对数据挖掘发挥影响,机器学习领域和数据库领域是数据挖掘的两大支撑。
——以上内容来自周志华版的《机器学习》一书
开发机器学习应用程序的步骤:
(1) 收集数据;
(2) 准备输入数据;
(3) 分析数据;
(4) 训练算法;
(5) 测试算法;
(6) 使用算法。
——以上内容来自《机器学习实战》一书
HiveSQL的学习和操作。
HiveSQL优化:
1、 数据剪裁及job优化;(列剪裁、分区剪裁、利用hive的优化机制减少job数、job输入输出优化)
2、 Join操作及优化;(避免笛卡尔积、数据过滤、小表放前大表放后原则、Mapjoin、left semi join)
3、 输入输出优化;(合理使用动态分区、union all优化、合理使用union all、合理使用UDTF、多粒度计算优化)
4、 数据去重与排序;(distinct与group by、排序优化)
5、 数据倾斜;
数据表类型分类:
拉链表、非拉链表(增量表、全量表)
其他杂项:
进行数据挖掘适合使用python语言和R语言。安装anaconda,使用python比较方便,并且可以安装R软件。















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









