






Python 生成器 yield 是编写基于处理管道,流或数据流程序的一种极其强大的方式,在《Python参考手册》中有一则实例非常简单实用,略加修改,分享一下给大家。如果你对生成器yield还不是很了解,可以查看《觉得Python中的生成器(yield)晦涩难懂?看完本文你就知道了》。
需求分析
假设服务器有一个日志文件,每隔一秒都会更新日志的内容,日志每行中都有一组类似:2017-12-21 14:07:26.471691 99123 数据被写入日志。 我们的目的是分析日志中的数字如果大于5000就要打印出来。 这样来看,我们需要一个程序负责模拟日志写入,另一个程序负责分析日志打印数据。
模拟日志写入
server_log.py:
import random
from datetime import *
import os
import time
def server_log():
# 生成模拟的日志数据
server_int = random.randint(1,99999)#生成需要的随机数
server_date = datetime.now()#获取当前系统时间
return str(server_date) + ' ' + str(server_int)#拼装日志字符串
while True:
#模拟系统写入日志
#打开日志文件并写入日志
with open(os.path.join(os.path.dirname(__file__),'server_log.log'),'at') as f :
s = server_log()
print(s)
f.write(s + '\n')
time.sleep(1)
上边的代码已经添加了相关的注释,这样我们就有了一个日志文件,每秒会有一第记录插入到日志中。
利用生成器yield解析日志
生成器可以返回一个迭代的流式的对象,我们可以通过这种方式便捷的获得相关数据,而且代码也更清晰易懂
tail.py 代码如下:
import time
def tail(f):
f.seek(0,2)#移动到文件尾部。
while True:
line = f.readline()
if not line :
time.sleep(1)
continue
yield line
def grep(lines):
for l in lines:
k = int(l.split()[2])
if k >50000:
yield l
serverlog = tail(open('server_log.log'))
lines = grep(serverlog)
for line in lines:
print(line)
我们运行两个文件看下效果:
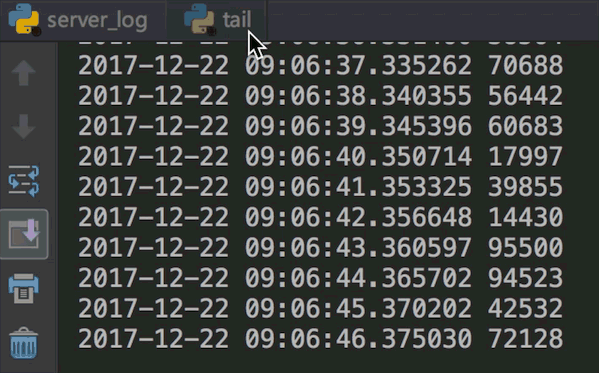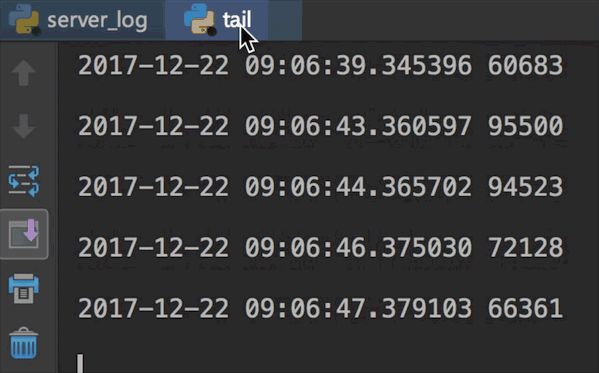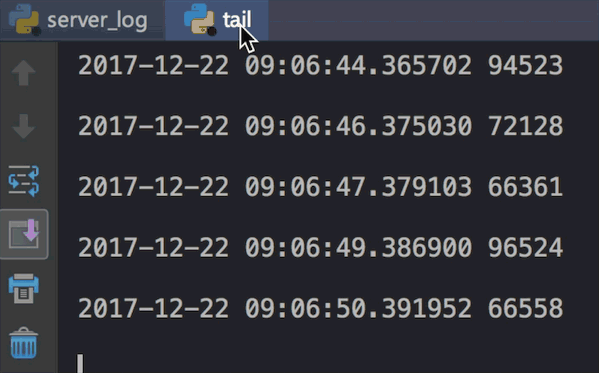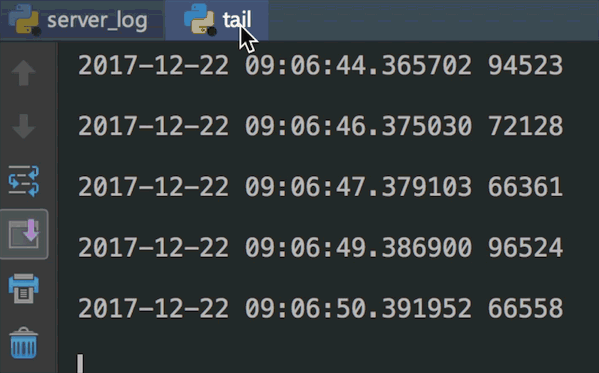
代码虽然简单,但值得细细品味,感受python的简约与强大吧。
【专业Python IDE推荐】——PyCharm
PyCharm 是一款Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。此外,该IDE提供了一些高级功能,以用于Django框架下的专业Web开发。















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









