






kudu基本架构如下图所示:
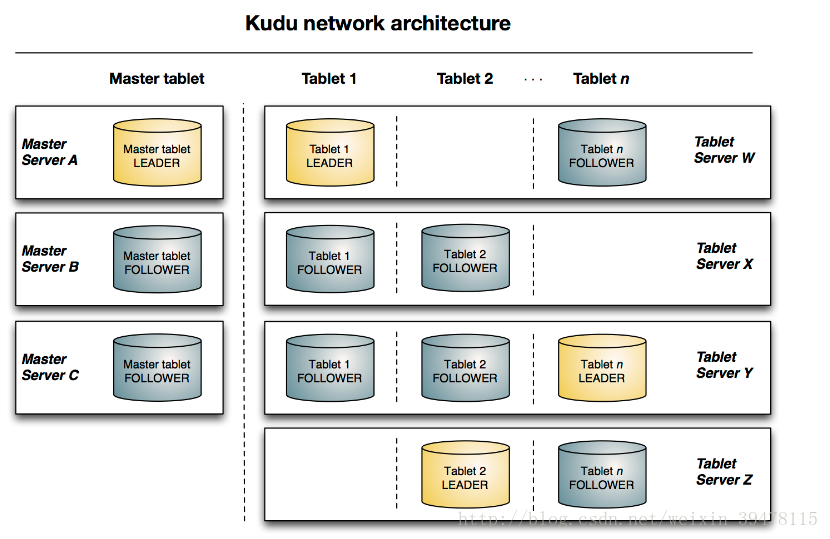
上图显示了一个具有三个 master 和多个tablet server的Kudu集群,每个服务器都支持多个tablet。它说明了如何使用 Raft 共识来允许master和tablet server的leader和follow。此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet follower。leader以金色显示,而 follower 则显示为蓝色。
总结:
1、KUDU分区数必须预先预定
2、在内存中对每个Tablet分区维护一个MemRowSet来管理最新更新的数据,默认是1G刷新一次或者是2分钟。后Flush到磁盘上形成DiskRowSet,多个DiskRowSet在适当的时候进行归并处理
3、和HBase采用的LSM(LogStructured Merge,很难对数据进行特殊编码,所以处理效率不高)方案不同的是,Kudu对同一行的数据更新记录的合并工作,不是在查询的时候发生的(HBase会将多条更新记录先后Flush到不同的Storefile中,所以读取时需要扫描多个文件,比较rowkey,比较版本等,然后进行更新操作),而是在更新的时候进行,在Kudu中一行数据只会存在于一个DiskRowSet中,避免读操作时的比较合并工作。那Kudu是怎么做到的呢? 对于列式存储的数据文件,要原地变更一行数据是很困难的,所以在Kudu中,对于Flush到磁盘上的DiskRowSet(DRS)数据,实际上是分两种形式存在的,一种是Base的数据,按列式存储格式存在,一旦生成,就不再修改,另一种是Delta文件,存储Base数据中有变更的数据,一个Base文件可以对应多个Delta文件,这种方式意味着,插入数据时相比HBase,需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此,Kudu是牺牲了写性能来换取读取性能的提升。
更新、删除操作需要记录到特殊的数据结构里,保存在内存中的DeltaMemStore或磁盘上的DeltaFIle里面。DeltaMemStore是B-Tree实现的,因此速度快,而且可修改。磁盘上的DeltaFIle是二进制的列式的块,和base数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的DeltaFiles文件,Kudu借鉴了Hbase的方式,会定期对这些文件进行合并。
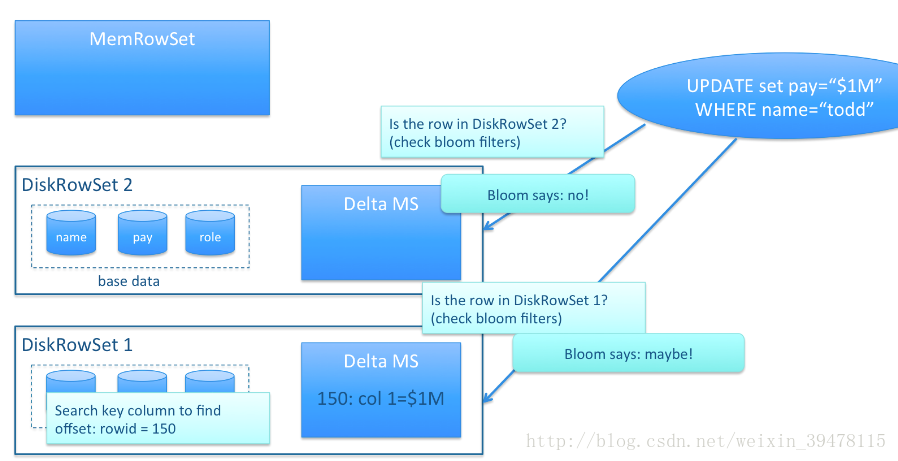
4、既然存在Delta数据,也就意味着数据查询时需要同时检索Base文件和Delta文件,这看起来和HBase的方案似乎又走到一起去了,不同的地方在于,Kudu的Delta文件与Base文件不同,不是按Key排序的,而是按被更新的行在Base文件中的位移来检索的,号称这样做,在定位Delta内容的时候,不需要进行字符串比较工作,因此能大大加快定位速度,但是无论如何,Delta文件的存在对检索速度的影响巨大。因此Delta文件的数量会需要控制,需要及时的和Base数据进行合并。由于Base文件是列式存储的,所以Delta文件合并时,可以有选择性的进行,比如只把变化频繁的列进行合并,变化很少的列保留在Delta文件中暂不合并,这样做也能减少不必要的IO开销。
5、除了Delta文件合并,DRS自身也会需要合并,为了保障检索延迟的可预测性(这一点是HBase的痛点之一,比如分区发生Major Compaction时,读写性能会受到很大影响),Kudu的compaction策略和HBase相比,有很大不同,kudu的DRS数据文件的compaction,本质上不是为了减少文件数量,实际上Kudu DRS默认是以32MB为单位进行拆分的,DRS的compaction并不减少文件数量,而是对内容进行排序重组,减少不同DRS之间key的overlap(重复),进而在检索的时候减少需要参与检索的DRS的数量。 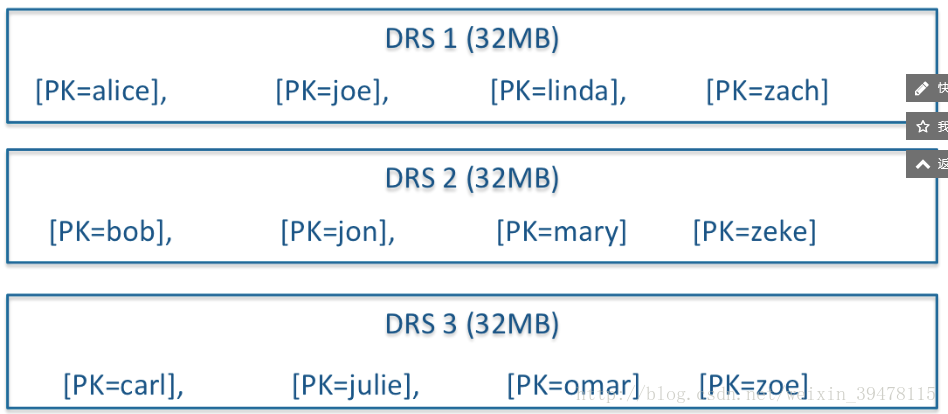















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









