







作者:刘旭晖 Raymond 转载请注明出处
Email:colorant at 163.com
BLOG:http://blog.csdn.net/colorant/
## == 是什么 ==
Kudu是Todd Lipcon@Cloudera带头开发的存储系统,其整体应用模式和HBase比较接近,即支持行级别的随机读写,并支持批量顺序检索功能。
那既然有了HBase,为什么还需要Kudu呢,简单的说,就是嫌弃HBase在OLAP场合,SQL/MR类的批量检索场景中,性能不够好。通常这种海量数据OLAP场景,要不走预处理的路,比如像EBAY麒麟这样走Cube管理的,或者像谷歌Mesa这样按业务需求走预定义聚合操作。再有就是自己构建数据通道,串接实时和批量处理两种系统,发挥各自的特长。
但是OLAP是个复杂的问题,场景众多,必然不可能有完美的通用解决方案,Kudu定位于应对快速变化数据的快速分析型数据仓库,希望靠系统自身能力,支撑起同时需要高吞吐率的顺序和随机读写的应用场景(可能的场景,比如时间序列数据分析,日志数据实时监控分析),提供一个介于HDFS和HBase的性能特点之间的一个系统,在随机读写和批量扫描之间找到一个平衡点,并保障稳定可预测的响应延迟
那为什么不能想办法改进HBase呢?Todd自己做为HBase的重要贡献者之一,没有选择这条路,自然是因为任何系统设计时都有Tradeoff,基于HBase的设计思想很难实现Kudu所定位的目标
相关链接:
## == 核心思想 ==
### 数据模型:
数据模型定义上,Kudu管理的是类似关系型数据库的结构化的表,表结构由类Sql的Schema进行定义,相比于HBase这样的NoSql类型的数据库,Kudu的行数据是由固定个数有明确类型定义的列组成,并且需要定义一个由一个或多个列组成的主键来对每行数据进行唯一索引,相比于传统的关系型数据库,kudu在索引上有更多的限制,比如暂时不支持二级索引,不支持主键的更新等等。
尽管表结构类似于关系型数据库,但是Kudu自身并不提供SQL类型的语法接口,而是由上层其他系统实现,比如目前通过Impala提供SQL语法支持。
Kudu底层API,主要面对简单的更新检索操作,Insert/Update/Delete等必须指定一个主键进行,而Scan检索类型的操作则支持条件过滤和投影等能力。
### 集群架构:
Kudu的集群架构基本和HBase类似,采用主从结构,Master节点管理元数据,Tablet节点负责分片管理数据,
和HBase不同的是,Kudu没有借助于HDFS存储实际数据,而是自己直接在本地磁盘上管理分片数据,包括数据的Replication机制,kudu的Tablet server直接管理Master分片和Slave分片,自己通过raft协议解决一致性问题等,多个Slave可以同时提供数据读取服务,相对于HBase依托HDFS进行Region数据的管理方式,自主性会强一些,不过比如Tablet节点崩溃,数据的迁移拷贝工作等,也需要Kudu自己完成。
### 存储结构:
因为数据是有严格Schema类型定义,所以Kudu底层可以使用列式存储的方案来提高存储和投影检索效率(不过,设计kudu时,因果关系我估计是倒过来的,先决定要使用列式存储,再决定需要schema)
和HBase一样,Kudu也是通过Tablet的分区来支持水平扩展,与HBase不同的是,Kudu的分区策略除了支持按照Key Range来分区以外,还支持Hash based的策略,实际上,在主键上,Kudu可以混合使用这两种不同的策略
Hash分区的策略在一些场合下可以更好的做到负载均衡,避免数据倾斜,但是它最大的问题就是分区数一旦确定就很难再调整,所以目前Kudu的分区数必须预先指定(对Range的分区策略也有这个要求,估计是先简单化统一处理),不支持动态分区分裂,合并等,因此表的分区一开始就需要根据负载和容量预先进行合理规划。
在处理随机写的效率问题方面,Kudu的基本流程和HBase的方案差不多,在内存中对每个Tablet分区维护一个MemRowSet来管理最新更新的数据,当尺寸超过一定大小后Flush到磁盘上形成DiskRowSet,多个DiskRowSet在适当的时候进行归并处理
和HBase采用的LSM(LogStructured Merge)方案不同的是,Kudu对同一行的数据更新记录的合并工作,不是在查询的时候发生的(HBase会将多条更新记录先后Flush到不同的Storefile中,所以读取时需要扫描多个文件,比较rowkey,比较版本等),而是在更新的时候进行,在Kudu中一行数据只会存在于一个DiskRowSet中,避免读操作时的比较合并工作。那Kudu是怎么做到的呢? 对于列式存储的数据文件,要原地变更一行数据是很困难的,所以在Kudu中,对于Flush到磁盘上的DiskRowSet(DRS)数据,实际上是分两种形式存在的,一种是Base的数据,按列式存储格式存在,一旦生成,就不再修改,另一种是Delta文件,存储Base数据中有变更的数据,一个Base文件可以对应多个Delta文件,这种方式意味着,插入数据时相比HBase,需要额外走一次检索流程来判定对应主键的数据是否已经存在。因此,Kudu是牺牲了写性能来换取读取性能的提升。
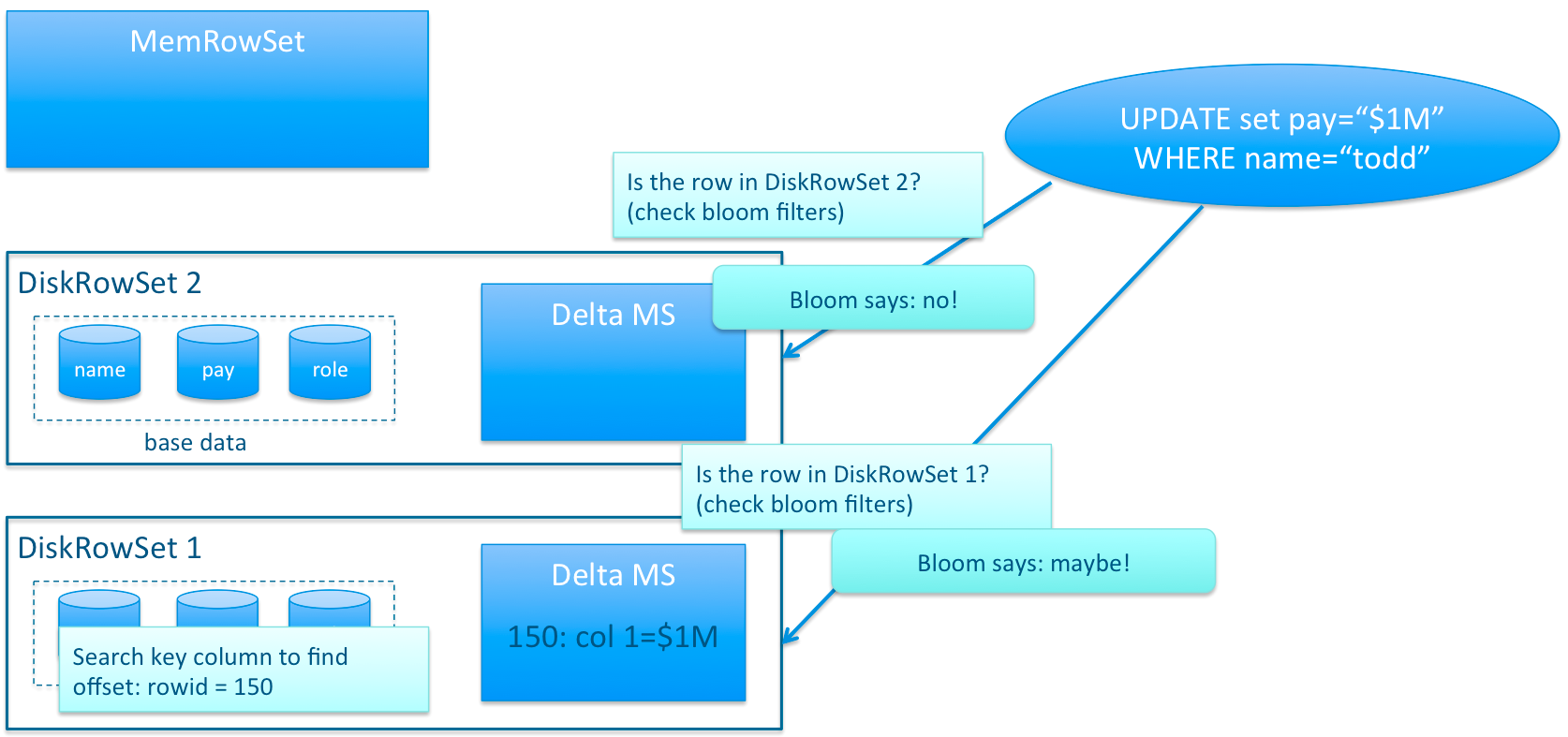
既然存在Delta数据,也就意味着数据查询时需要同时检索Base文件和Delta文件,这看起来和HBase的方案似乎又走到一起去了,不同的地方在于,Kudu的Delta文件与Base文件不同,不是按Key排序的,而是按被更新的行在Base文件中的位移来检索的,号称这样做,在定位Delta内容的时候,不需要进行字符串比较工作,因此能大大加快定位速度。但是无论如何,Delta文件的存在对检索速度的影响巨大。因此Delta文件的数量会需要控制,需要及时的和Base数据进行合并。由于Base文件是列式存储的,所以Delta文件合并时,可以有选择性的进行,比如只把变化频繁的列进行合并,变化很少的列保留在Delta文件中暂不合并,这样做也能减少不必要的IO开销。
除了Delta文件合并,DRS自身也会需要合并,为了保障检索延迟的可预测性(这一点是HBase的痛点之一,比如分区发生Major Compaction时,读写性能会受到很大影响),Kudu的compaction策略和HBase相比,有很大不同,kudu的DRS数据文件的compaction,本质上不是为了减少文件数量,实际上Kudu DRS默认是以32MB为单位进行拆分的,DRS的compaction并不减少文件数量,而是对内容进行排序重组,减少不同DRS之间key的overlap,进而在检索的时候减少需要参与检索的DRS的数量。
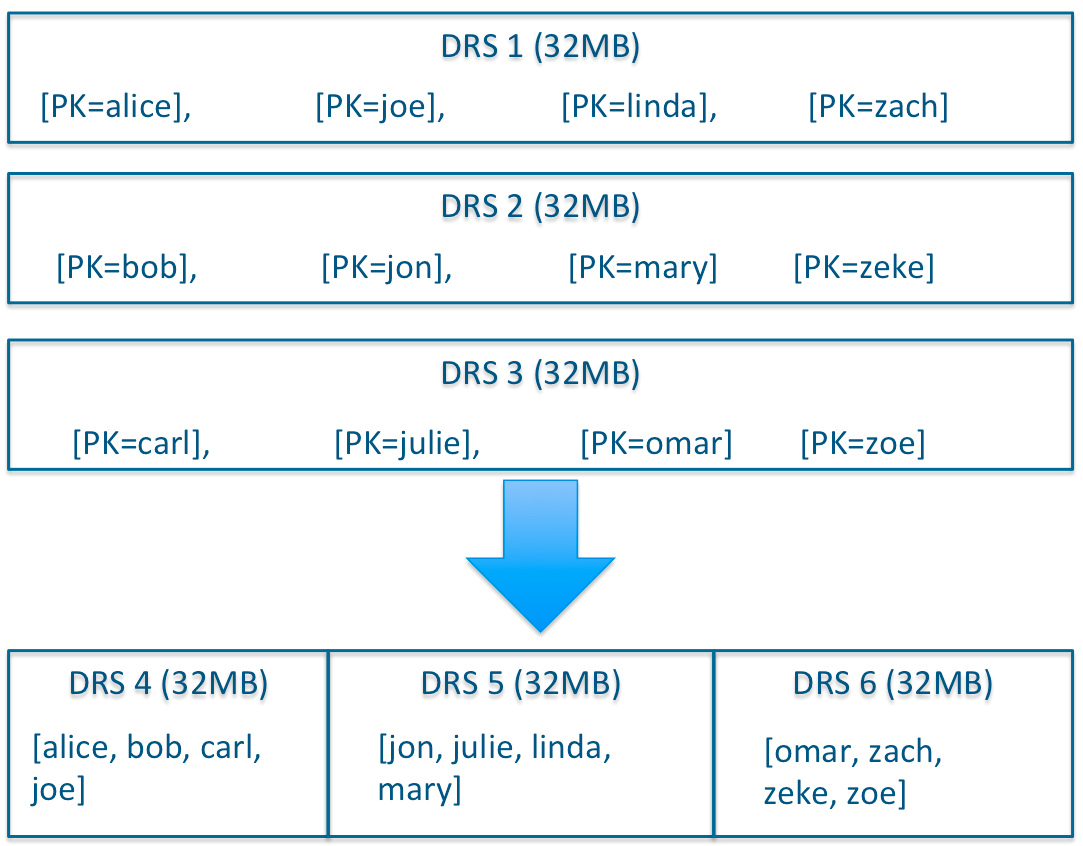
以32MB这样小的单位进行拆分,也是为了能够以有限的资源快速的完成compaction的任务,及时根据系统负载调整Compaction行为,而不至于像HBase一样,Major Compaction动作成为导致性能不稳定的一个重要因素。所以对于Kudu来说,IO操作可以是一个持续平缓的过程,这点对响应的可预测性至关重要。
### 其它
Kudu底层核心代码使用C++开发,对外提供Java API接口,没有使用Java开发核心代码,也许有部分原因是希望通过自己管理内存,更好的适应和利用当前服务器上普遍越来越大的内存空间(256G+),另外也便于在关键逻辑中更好的优化代码。
## == 小结 ==
总体来说,个人感觉,Kudu本质上是将性能的优化,寄托在以列式存储为核心的基础上,希望通过提高存储效率,加快字段投影过滤效率,降低查询时CPU开销等来提升性能。而其他绝大多数设计,都是为了解决在列式存储的基础上支持随机读写这样一个目的而存在的。比如类Sql的元数据结构,是提高列式存储效率的一个辅助手段,唯一主键的设定也是配合列式存储引入的定制策略,至于其他如Delta存储,compaction策略等都是在这个设定下为了支持随机读写,降低latency不确定性等引入的一些Tradeoff方案
官方测试结果上,如果是存粹的随机读写,或者单行的检索请求这类场景,由于这些Tradeoff的存在,HBASE的性能吞吐率是要优于Kudu不少的(2倍到4倍),kudu的优势还是在支持类SQL检索这样经常需要进行投影操作的批量顺序检索分析场合。
目前kudu还处在Incubator阶段,并且还没有成熟的线上应用(小米走在了前面,做了一些业务应用的尝试),在数据安全,备份,系统健壮性等方面也还要打个问号,所以是否使用kudu,什么场合,什么时间点使用,是个需要好好考量的问题 ;)
----
顺道,推销一下个人公众号 "望月的蚂蚁", 和技术完全无关。。。。 以一些有趣的兴趣爱好等为主题,比如乐高,桌游,旅行,摄影。。。工作生活要平衡不是;)


















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









