






前提条件
- 集群内的节点(物理机或虚拟机)安装的是以下任一操作系统:
- Ubuntu 16.04+
- Debian 9
- CentOS 7
- RHEL 7
- Fedora 25/26 (best-effort)
- HypriotOS v1.0.1+
- Container Linux (tested with 1800.6.0)
- 每个节点有2 GB或更多的内存
- 有至少两个或以上的CPU
- 在集群内所有的节点的网络连接是通的 (无论公有还是私有网络都可以)
- 确认每个节点拥有唯一的 hostname, MAC address, 和 product_uuid。以centOS为例:
- 用"ip add"命令查看ip和MAC地址;
- 用"hostname -s"查看hostname;
- 用"sudo cat /sys/class/dmi/id/product_uuid"查看product_uuid;
- 开放节点上的指定端口。具体可以参照下面文章内的详细步骤。查看更多
- 禁止Swap. 为了让Kubelet正常工作, 必须禁止swap
根据需要选择想要实现的HA集群方式
目前有两种实现k8s HA集群的方式
-
堆栈式的etcd拓扑结构(Stacked etcd topology)
- 外置的etcd拓扑结构(External etcd topology)
在安装之前你必须选择适合的拓扑结构来实现集群的HA。详情可以参考官方文档。
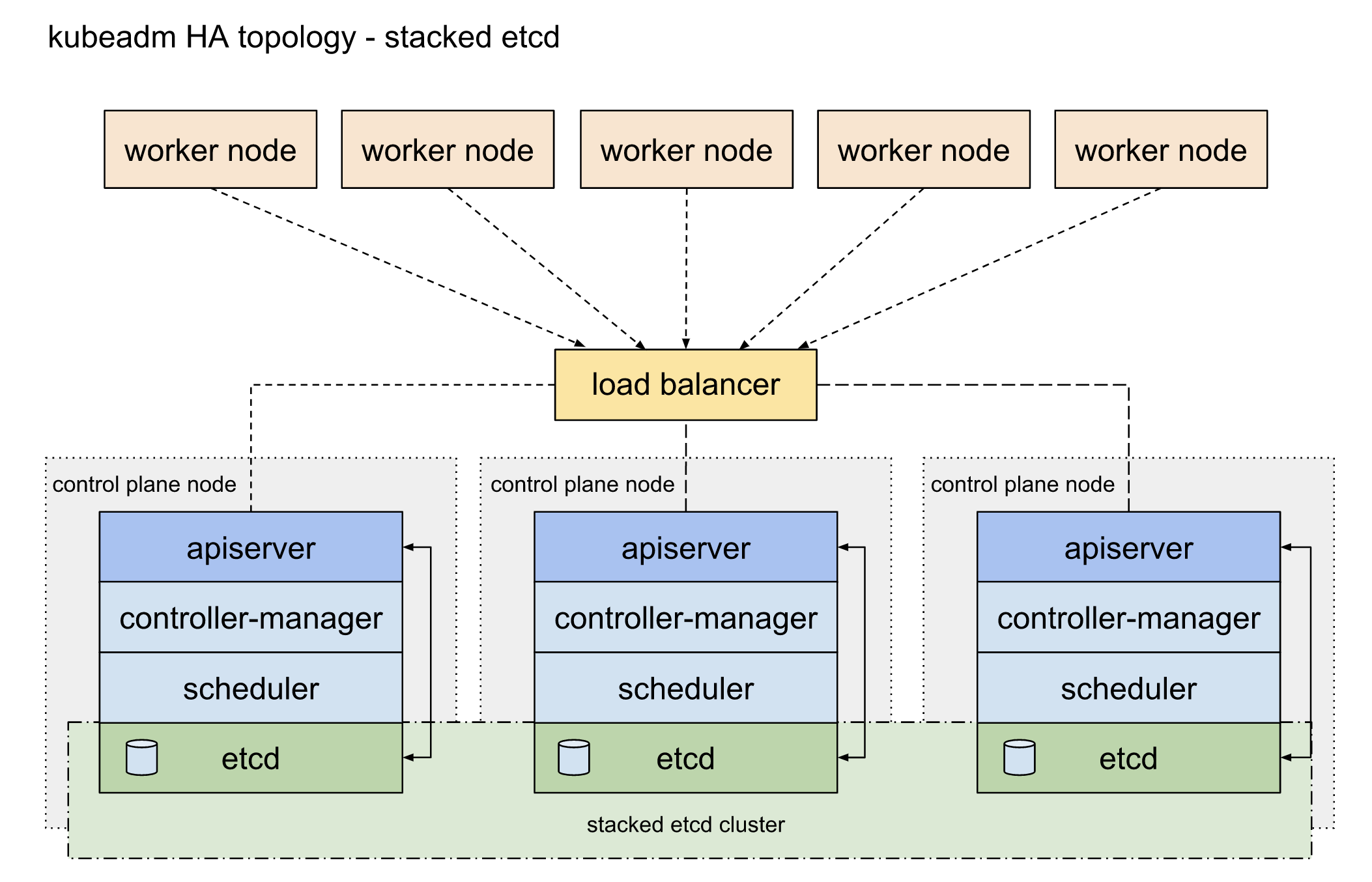
选择第一种堆栈式的etcd意味着由ETCD提供的分布式数据存储集群,将堆叠在由kubeadm管理并运行着一系列管理组件的节点形成的集群之上。每一个管理几点都运行着kube-apiserver, kube-scheduler, and kube-controller-manager的实例。kube-apiserver 将通过load balancer暴露给worker nodes。每一个管理节点都会创建一个local的etcd成员,并且这个etcd member只能通过同一节点上的kube-apiserver进行通信。kube-controller-manager和Kube-scheduler也和etcd一样。这样的拓扑结构是control planes和etcd结合在同一个节点上,易于安装和便于管理。但是这样的方式有无法解耦的风险:一旦一个节点down了,意味着etcd和control plane的实例都会消失。当然如果你安装更多的类似节点将可以降低此类风险。另外,当使用kubeadm和kubeadm join --control-plane的时候,local etcd member默认是自动安装的。
这个拓扑结构意味着你至少要安装3个节点来实现高可用的k8s集群。
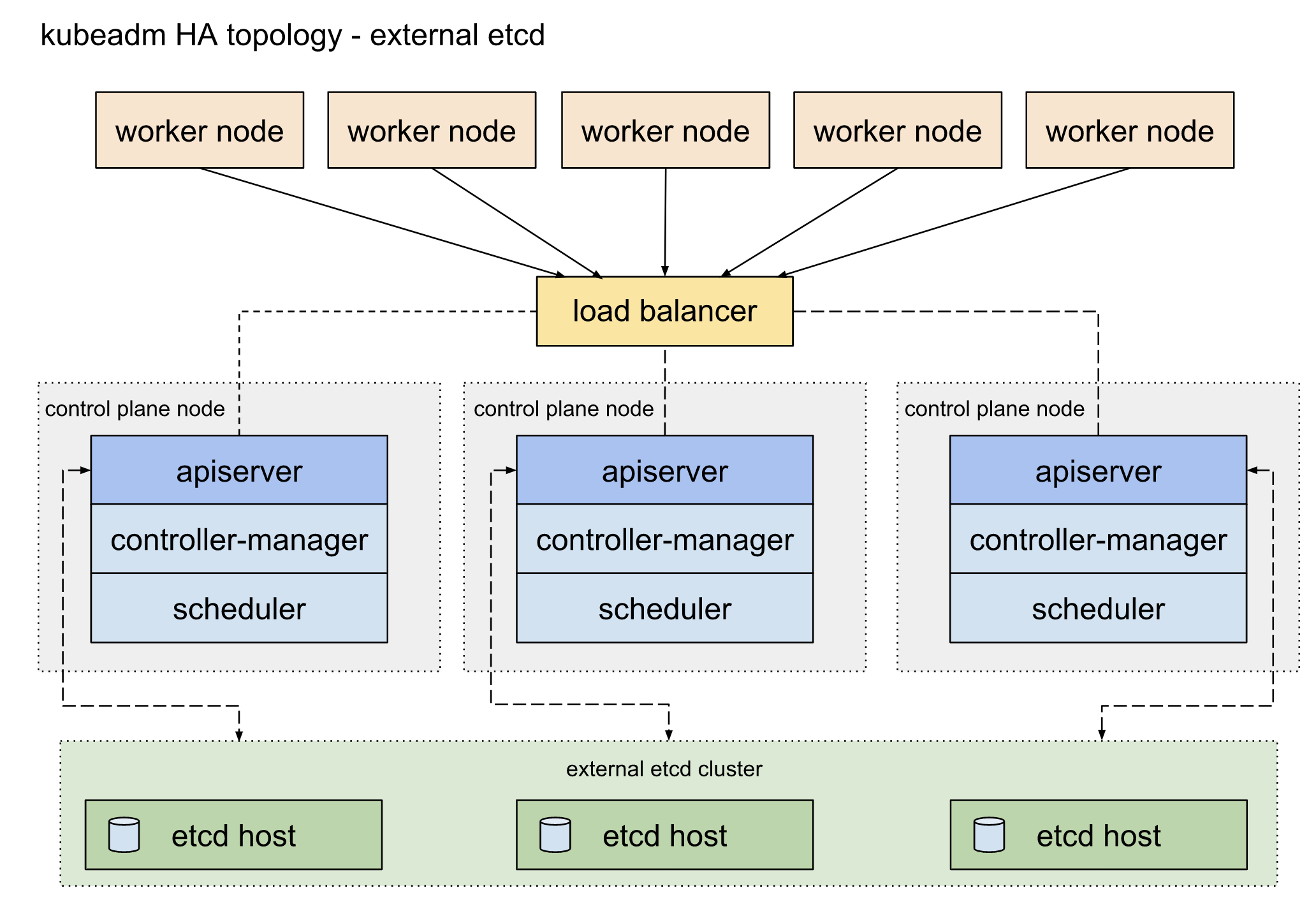
如果选择第二种外部etcd的结构,则意味着由etcd实现的分布式数据存储在安装在运行control plane组件的节点之外的。像堆栈式etcd的结构一样,每一个control plane的节点都会运行kube-apiserver, kube-scheduler, 和 kube-controller-manager. 并且 kube-apiserver 也会通过load blancer暴露给工作节点。但是etcd成员将运行在另外的节点,每一个etcd的节点通过 kube-apiserver 来与 每一个control plane 节点进行通信。这种拓扑结构解耦了control plane和etcd member。为集群提供了高可用性,当失去control plane的实例或etcd的时候对集群的影响要远远小于stacked HA topology.但是这样的拓扑结构意味着比堆栈式的结构至少多三个节点。
这种拓扑结构的要求是最少5个host, 3个运行etcd,3个运行管理平台。
为了简化,我们将选取第一种拓扑结构来实现高可用k8s集群的安装。
安装环境
| Hostname: | kmaster1 | kmaster2 | kmaster3 | kworker1 | kworker2 |
| IP Address: | 192.168.7.67/24 | 192.168.7.68/24 | 192.168.7.69/24 | 192.168.7.71/24 | 192.168.7.75/24 |
| Cluster Role: | K8s master | K8s master | K8s master | K8s node | K8s node |
| CPU: | 2.6 Ghz (2 cores) | 2.6 Ghz (2 cores) | 2.6 Ghz (2 cores) | 2.6 Ghz (2 cores) | 2.6 Ghz (2 cores) |
| Memory: | 2 GB | 2 GB | 2 GB | 2 GB | 2 GB |
| Storage: | 15 GB | 15 GB | 15 GB | 15 GB | 15 GB |
| Operating System: | CentOS 7.6 | CentOS 7.6 | CentOS 7.6 | CentOS 7.6 | CentOS 7.6 |
| Docker version: | 18.09.7 | 18.09.7 | 18.09.7 | 18.09.7 | 18.09.7 |
| Kubernetes version: | 1.14.1 | 1.14.1 |
为每个节点设置hostname
[root@10 ~]# hostnamectl set-hostname kworker1
1. 初始化环境 (所有node都需按同样步骤初始化环境)
1.0 安装Docker之前所需要安装的依赖
[fibodt@kmaster ~]$ sudo yum update
[fibodt@kmaster ~]$ sudo yum install -y device-mapper-persistent-data lvm2 yum-utils wget
1.1 设置防火墙
Kubernetes 在 Master node 默认使用端口如下:
| Port | Protocol | Purpose |
| 6443 | TCP | Kubernetes API server |
| 2379-2380 | TCP | etcd server client API |
| 10250 | TCP | Kubelet API |
| 10251 | TCP | kube-scheduler |
| 10252 | TCP | kube-controller-manager |
在master node的防火墙上允许关于Kubernetes service的端口
[root@kmaster ~]# firewall-cmd --permanent --zone=public --add-port={6443,2379,2380,10250,10251,10252}/tcp
success
[root@kmaster ~]# firewall-cmd --reload
success
Kubernetes 在 Worker node上使用端口如下:
| Port | Protocol | Purpose |
| 10250 | TCP | Kubelet API |
| 30000-32767 | TCP | NodePort Services |
在worker node的防火墙上允许关于Kubernetes service的端口
[root@kworker1 ~]# firewall-cmd --permanent --zone=public --add-port={10250,30000-32767}/tcp
success
[root@kworker1 ~]# firewall-cmd --reload
success
切换 SELinux 到 Permissive mode. 这样可以允许container访问所在节点的文件系统。比如pod networks就需要访问。在kubelet改进对SELinux的support之前这一步是必须执行的。
[root@kmaster ~]# setenforce 0 [root@kmaster ~]# sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
1.2 关闭Swap
[root@kmaster ~]# swapoff -a && sysctl -w vm.swappiness=0
vm.swappiness = 0
[root@localhost ~]# vi /etc/fstab
#/dev/mapper/centos-swap swap swap defaults 0 0
1.3 设置Docker所需参数
有些用户report了issues,流量有时会绕过iptables导致不能正常的路由。你必须确认net.bridge.bridge-nf-call-iptables 是设置为1的。
[root@kmaster ~]# vi /etc/sysctl.d/k8s.conf net.ipv4.ip_forward = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 vm.swappiness=0 [root@kmaster ~]# modprobe br_netfilter [root@kmaster ~]# sysctl -p /etc/sysctl.d/k8s.conf
1.4 安装Docker
[root@kmaster ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
[root@kmaster ~]# yum makecache fast
[root@kmaster ~]# yum install docker-ce -y
## Create /etc/docker directory.
[root@kmaster ~]# mkdir /etc/docker
# Setup daemon.
[root@kmaster ~]# vi /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
[root@kmaster ~]# mkdir -p /etc/systemd/system/docker.service.d
# Restart Docker
systemctl daemon-reload
systemctl restart docker
1.5 所有节点配置host
- k-master1要可以SSH到所有节点,同样k-master2和3也要同样可以ssh
#创建ssh key (一路回车) ssh-keygen #copy token 到master节点 ssh-copy-id kmaster2 ssh-copy-id kmaster3
- 所有节点需要添加ip地址和hostname的映射到/etc/hosts
192.168.7.67 kmaster1 192.168.7.68 kmaster2 192.168.7.69 kmaster3 192.168.7.100 k8s-vip #虚拟IP
- 修改语言和时区
echo 'LANG="en_US.UTF-8"' >> /etc/profile;source /etc/profile #修改系统语言
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime # 修改时区(如果需要修改)2. 安装HAProxy+Keepalived作为Load Balancer
- Keepalived:提供虚拟网络位址(VIP)。
- HAProxy:提供负载平衡器。
性能调优
[root@kmaster1 haproxy]# vi /etc/sysctl.conf net.ipv4.ip_forward=1 net.bridge.bridge-nf-call-iptables=1 net.ipv4.neigh.default.gc_thresh1=4096 net.ipv4.neigh.default.gc_thresh2=6144 net.ipv4.neigh.default.gc_thresh3=8192
sysctl -p
2.1 安装keepalive
- kmaster1安装keepalive
[root@kmaster1 haproxy]# yum install -y keepalived
[root@kmaster1 haproxy]# vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
xxxx@xxxx.com
}
smtp_server 192.168.7.100
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance haproxy_vip {
state MASTER
interface ens8
virtual_router_id 51
priority 99
advert_int 3
unicast_src_ip 192.168.7.67
unicast_peer {
192.168.7.68
192.168.7.69
}
virtual_ipaddress {
192.168.7.74
}
track_script {
check_haproxy weight 20
}
}
启动Keepalived
[root@kmaster1 fibodt]# systemctl enable keepalived.service && systemctl start keepalived.service
检查虚拟ip是否生效
[root@kmaster1 fibodt]# ip a | grep "192.168.7.74"
inet 192.168.7.74/32 scope global enp0s8
- kmaster2和kmaster3按照同样的配置,除了IP和priority稍作调整。
2.2 安装HAProxy
查看默认仓库中的HAProxy版本
[fibodt@kmaster1 manifests]$ sudo yum info haproxy
Failed to set locale, defaulting to C
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: ftp-srv2.kddilabs.jp
* extras: ftp-srv2.kddilabs.jp
* updates: ftp-srv2.kddilabs.jp
Available Packages
Name : haproxy
Arch : x86_64
Version : 1.5.18
Release : 8.el7
Size : 834 k
Repo : base/7/x86_64
Summary : TCP/HTTP proxy and load balancer for high availability environments
URL : http://www.haproxy.org/
License : GPLv2+
Description : HAProxy is a TCP/HTTP reverse proxy which is particularly suited for high
: availability environments. Indeed, it can:
: - route HTTP requests depending on statically assigned cookies
: - spread load among several servers while assuring server persistence
: through the use of HTTP cookies
: - switch to backup servers in the event a main server fails
: - accept connections to special ports dedicated to service monitoring
: - stop accepting connections without breaking existing ones
: - add, modify, and delete HTTP headers in both directions
: - block requests matching particular patterns
: - report detailed status to authenticated users from a URI
: intercepted by the application
可以看到仓库中版本为1.5。我们将会安装最新release的稳定版2.0.但目前并没有在任何标准仓库中。
#安装依赖包
sudo yum install gcc pcre-static pcre-devel -y
#安装编译工具
sudo yum install openssl-devel make -y
#获取haproxy安装包
wget http://www.haproxy.org/download/2.0/src/haproxy-2.0.1.tar.gz
# 解压
tar -xf ~/haproxy-*.tar.gz -C ~/
cd haproxy-2.0.1
# 普通安装方式,haproxy不支持SSL
sudo make TARGET=linux-glibc ARCH=x86_64 prefix=/usr/local/haproxy install
# 需要haproxy支持SSL时,使用如下编译方式
sudo make TARGET=linux-glibc ARCH=x86_64 USE_OPENSSL=1 ADDLIB=-lz prefix=/usr/local/haproxy
sudo make install
#将haproxy和openssl库连接
ldd haproxy | grep ssl
#配置软连接
sudo ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy
#进入编译的目录下的example目录,将haproxy.init文件复制到/etc/init.d/
sudo cp haproxy.init /etc/init.d/haproxy
#在赋予/etc/init.d/haproxy 755权限
sudo chmod 755 /etc/init.d/haproxy
#在/etc/下创建haproxy目录
mkdir /etc/harpoxy
#在配置目录下创建文件: haproxy.cfg
global
chroot /var/lib/haproxy
daemon
group haproxy
user haproxy
log 127.0.0.1:514 local0 warning
pidfile /var/lib/haproxy.pid
maxconn 60000
spread-checks 3
nbproc 8
defaults
log global
mode tcp
retries 3
option redispatch
listen https-apiserver
bind 192.168.7.4:8443
mode tcp
balance roundrobin
timeout server 15s
timeout connect 15s
server apiserver01 192.168.7.67:6443 check port 6443 inter 5000 fall 5
server apiserver02 192.168.7.68:6443 check port 6443 inter 5000 fall 5
server apiserver03 192.168.7.69:6443 check port 6443 inter 5000 fall 5
重启haproxy
sudo systemctl restart haproxy
3. 安装部署Kubernetes
3.1 安装kubeadm和kubelet,kubectl
需要在所有的节点上安装kubeadm和kubelet,kubectl是可以选装的。
-
kubeadm: 引导集群的组件。(如kubeadm init或join) -
kubelet: 运行在集群中所有节点上的,用来启动pods和containers. -
kubectl: 使用命令行与集群对话.
添加kubernetes的repository,如果国内连不上可以把repo的URL换成国内的镜像
国内镜像
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kube* EOF
官方镜像
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOF
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes systemctl enable kubelet.service
3.2 使用Kubeadm初始化集群
kubeadm init 命令默认使用的docker镜像仓库为k8s.gcr.io,国内无法直接访问,我们可以通过 docker.io/mirrorgooglecontainers 中转一下。
首先查看下究竟需要哪些image
kubeadm config images list
#输出如下结果
k8s.gcr.io/kube-apiserver:v1.15.0
k8s.gcr.io/kube-controller-manager:v1.15.0
k8s.gcr.io/kube-scheduler:v1.15.0
k8s.gcr.io/kube-proxy:v1.15.0
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.3.10
k8s.gcr.io/coredns:1.3.1批量下载及转换标签
kubeadm config images list | sed -e 's/^/docker pull /g' -e 's#k8s.gcr.io#docker.io/mirrorgooglecontainers#g'| sh -x
docker images | grep mirrorgooglecontainers | awk '{print "docker tag ", $1 ":" $2 , $1 ":" $2 }' | sed -e's#mirrorgooglecontainers#k8s.gcr.io#2' | sh -x
docker images | grep mirrorgooglecontainers | awk '{print "docker rmi ", $1 ":" $2 }' | sh -x
由于镜像中没有coredns需要另外下载
docker pull coredns/coredns:1.3.1 docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1 docker rmi coredns/coredns:1.3.1
也可以直接create一个shell文件并执行
#!/bin/bash
images=(kube-apiserver:v1.15.0 kube-controller-manager:v1.15.0 kube-scheduler:v1.15.0 kube-proxy:v1.15.0 pause:3.1 etcd:3.3.10 )
for imageName in ${images[@]} ; do
docker pull mirrorgooglecontainers/$imageName
docker tag mirrorgooglecontainers/$imageName k8s.gcr.io/$imageName
docker rmi mirrorgooglecontainers/$imageName
done
docker pull coredns/coredns:1.3.1
docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
docker rmi coredns/coredns:1.3.1
完成后查看列表
[fibodt@kmaster1 ~]$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE calico/node v3.7.4 84b65b552a8f 5 days ago 155MB calico/cni v3.7.4 203668d151b2 5 days ago 135MB calico/kube-controllers v3.7.4 e67ede28cc7e 5 days ago 46.8MB k8s.gcr.io/kube-proxy v1.15.0 d235b23c3570 2 weeks ago 82.4MB k8s.gcr.io/kube-apiserver v1.15.0 201c7a840312 2 weeks ago 207MB k8s.gcr.io/kube-scheduler v1.15.0 2d3813851e87 2 weeks ago 81.1MB k8s.gcr.io/kube-controller-manager v1.15.0 8328bb49b652 2 weeks ago 159MB k8s.gcr.io/coredns 1.3.1 eb516548c180 5 months ago 40.3MB k8s.gcr.io/etcd 3.3.10 2c4adeb21b4f 7 months ago 258MB k8s.gcr.io/pause 3.1 da86e6ba6ca1 18 months ago 742kB
创建一个配置文件:kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: stable controlPlaneEndpoint: 192.168.7.3:6443 networking: podSubnet: 192.168.0.0/16
用kubeadm初始化第一个master node
#这里pod的cidr是按照calico的官方文档进行设置的,这里的apiserver选择做了HA的虚拟路由地址 [fibodt@kmaster1 ~] sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
为了保证kubectl可以在非root用户的时候使用,可以执行以下命令将k8s的配置文件拷贝到需要执行kubectl的用户路径下。
请注意:这些配置文件是在执行kubeadm init之后产生的。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看当前节点
[fibodt@kmaster1 ~]$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
kmaster1 NotReady master 60m v1.15.0 192.168.7.67 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://18.9.7
此时有一台control plane了,且状态为"NotReady"
查看所有的pod
[fibodt@kmaster1 ~]$ kubectl get pods --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system coredns-5c98db65d4-d2f2b 0/1 Pending 0 62m <none> <none> <none> <none>
kube-system coredns-5c98db65d4-ljfjc 0/1 Pending 0 62m <none> <none> <none> <none>
kube-system etcd-kmaster1 1/1 Running 0 61m 192.168.7.67 kmaster1 <none> <none>
kube-system kube-apiserver-kmaster1 1/1 Running 0 61m 192.168.7.67 kmaster1 <none> <none>
kube-system kube-controller-manager-kmaster1 1/1 Running 0 61m 192.168.7.67 kmaster1 <none> <none>
kube-system kube-proxy-c8h6q 1/1 Running 0 62m 192.168.7.67 kmaster1 <none> <none>
kube-system kube-scheduler-kmaster1 1/1 Running 0 61m 192.168.7.67 kmaster1 <none> <none>
因为还没有安装网络插件,所以Croedns处于 Pending。
参考calico的官网,视集群大小选择默认的文件下载
curl https://docs.projectcalico.org/v3.7/manifests/calico.yaml -O
kubectl apply -f calico.yaml再次查看pod的状态,这个时候你会发现网络插件Calico已经在正常运行了,之前pending状态的coredns也正常运行了
[fibodt@kmaster1 ~]$ kubectl get pods --all-namespaces -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-system calico-kube-controllers-658558ddf8-2vhnr 1/1 Running 0 31s 192.168.69.193 kmaster1 <none> <none> kube-system calico-node-7sb6c 1/1 Running 0 31s 192.168.7.67 kmaster1 <none> <none> kube-system coredns-5c98db65d4-qnxwm 1/1 Running 0 4m38s 192.168.69.194 kmaster1 <none> <none> kube-system coredns-5c98db65d4-xg2t4 1/1 Running 0 4m38s 192.168.69.195 kmaster1 <none> <none> kube-system etcd-kmaster1 1/1 Running 0 3m39s 192.168.7.67 kmaster1 <none> <none> kube-system kube-apiserver-kmaster1 1/1 Running 0 3m50s 192.168.7.67 kmaster1 <none> <none> kube-system kube-controller-manager-kmaster1 1/1 Running 0 3m45s 192.168.7.67 kmaster1 <none> <none> kube-system kube-proxy-frk25 1/1 Running 0 4m38s 192.168.7.67 kmaster1 <none> <none> kube-system kube-scheduler-kmaster1 1/1 Running 0 3m35s 192.168.7.67 kmaster1 <none> <none>
再次查看node状态,可以发现kmaster1已经ready了。
[fibodt@kmaster1 ~]$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME kmaster1 Ready master 6m59s v1.15.0 192.168.7.67 <none> CentOS Linux 7 (Core) 3.10.0-957.21.3.el7.x86_64 docker://18.9.7
查看kmaster1的config file
kubectl -n kube-system get cm kubeadm-config -o yaml
kmaster2, kmaster3 可以用上面kmaster1初始化时候的token加入节点,请注意,这里是以control plane的身份加入,而不是worker的身份。
sudo kubeadm join 192.168.7.4:6443 --token 4c7xkn.krdd8tomamgcj0sm --discovery-token-ca-cert-hash sha256:eb7681c84f6a70c57d20c6b9395041f316d12b77292dabe43c276ac94f3d710f --experimental-control-plane --certificate-key e8225d88c42821b514f148e5838cce500198824de2ea2b2a986a0fd4b2c106a8
其他worker的节点加入命令如下
sudo kubeadm join 192.168.7.4:6443 --token 4c7xkn.krdd8tomamgcj0sm --discovery-token-ca-cert-hash sha256:eb7681c84f6a70c57d20c6b9395041f316d12b77292dabe43c276ac94f3d710f
下面段落是针对不使用kubeadm进行集群安装的客户,已完成上面所有步骤的用户可以不用参考
1. 参考上面的“前提条件”
2. 在k8s master node上生成证书
2.1 创建k8s安装目录
[fibodt@kmaster ~]$ mkdir /k8s/etcd/{bin,cfg,ssl} -p
[fibodt@kmaster ~]$ mkdir /k8s/kubernetes/{bin,cfg,ssl} -p
2.2 安装及配置CFSSL
[root@kmaster k8s]$ wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 [root@kmaster k8s]$ wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 [root@kmaster k8s]$ wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 [root@kmaster k8s]$ chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64 [root@kmaster k8s]$ mv cfssl_linux-amd64 /usr/bin/cfssl [root@kmaster k8s]$ mv cfssljson_linux-amd64 /usr/bin/cfssljson [root@kmaster k8s]$ mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo [root@kmaster k8s]$ cfssl version
根据认证对象可以将证书分成三类:服务器证书server cert,客户端证书client cert,对等证书peer cert(表示既是server cert又是client cert),在kubernetes 集群中需要的证书种类如下:
etcd节点需要标识自己服务的server cert,也需要client cert与etcd集群其他节点交互,当然可以分别指定2个证书,也可以使用一个对等证书master节点需要标识 apiserver服务的server cert,也需要client cert连接etcd集群,这里也使用一个对等证书kubectlcalicokube-proxy只需要client cert,因此证书请求中 hosts 字段可以为空kubelet证书比较特殊,不是手动生成,它由node节点TLS BootStrap向apiserver请求,由master节点的controller-manager自动签发,包含一个client cert和一个server cert
2.3 创建etcd证书
配置证书生成策略,规定CA可以颁发那种类型的证书
[fibodt@kmaster ~]$ cd /k8s/etcd/ssl
[fibodt@kmaster ssl]$ cat << EOF | tee ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
创建etcd client证书签名请求
[fibodt@kmaster ssl]$ cat << EOF | tee etcd-client-csr.json
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "JiangSu",
"ST": "SuZhou"
}
]
}
EOF
创建etcd server证书签名请求
[fibodt@kmaster ssl]$ cat << EOF | tee etcd-server-csr.json
{
"CN": "etcd",
"hosts": [
"192.168.7.67",
"192.168.7.68",
"192.168.7.69"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Shenzhen",
"ST": "Shenzhen"
}
]
}
EOF
生成证书所必需的文件ca-key.pem(私钥)和ca.pem(证书),还会生成ca.csr(证书签名请求),用于交叉签名或重新签名。
[fibodt@kmaster ssl]$ ls ca-config.json ca-csr.json server-csr.json [fibodt@kmaster ssl]$ cfssl gencert -initca ca-csr.json | cfssljson -bare ca - [fibodt@kmaster ssl]$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
2.4 创建API Server证书
[fibodt@kmaster ssl]$ cd /k8s/kubernetes/ssl/
[fibodt@kmaster ssl]$ cat << EOF | tee ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
[fibodt@kmaster ssl]$ cat << EOF | tee ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "JiangSu",
"ST": "SuZhou",
"O": "k8s",
"OU": "System"
}
]
}
EOF
[fibodt@kmaster ssl]$ cat << EOF | tee server-csr.json
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.7.67",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "JiangSu",
"ST": "SuZhou",
"O": "k8s",
"OU": "System"
}
]
}
EOF
[fibodt@kmaster ssl]$ ls
ca-config.json ca-csr.json server-csr.json
[fibodt@kmaster ssl]$ cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
[fibodt@kmaster ssl]$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
2.5 创建Kube-proxy证书
[fibodt@kmaster ssl]$ cat << EOF | tee kube-proxy-csr.json
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "JiangSu",
"ST": "SuZhou",
"O": "k8s",
"OU": "System"
}
]
}
EOF
[fibodt@kmaster ssl]$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
3. 添加SSH
[fibodt@kmaster kubernetes]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/fibodt/.ssh/id_rsa): Created directory '/home/fibodt/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/fibodt/.ssh/id_rsa. Your public key has been saved in /home/fibodt/.ssh/id_rsa.pub. The key fingerprint is: SHA256:RHkyPG+XZjodJpYGHSRlYoQ2soEtKzGcYhZZjWKOSek fibodt@kmaster The key's randomart image is: +---[RSA 2048]----+ |..*+o +*==. | |+@o.+.+oB+o | |X+.o = ..B . . | |+E. . . B B | | . S+ O . | | o . | | . | | | | | +----[SHA256]-----+ [fibodt@kmaster kubernetes]$ ssh-copy-id fibodt@192.168.7.68 [fibodt@kmaster kubernetes]$ ssh-copy-id fibodt@192.168.7.69
4. 部署ETCD















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









