






Redis
自己马上也想换个工作了,抽个空把redis整理一下,以面对面试官的狂轰乱炸。话不多说,马上开始!
redis特性(为什么要用redis):
1:速度快;2:持久化;3:支持多种数据结构;4:支持多种编辑语言;5:功能丰富;6:简单;7:集群高可用;
速度快
官方给出的数据是每秒处理(单机)10w ops。速度快的原因是以下几点:
1.数据存在内存中:计算机存储速度由高到底依次是:寄存器—》一级缓存—》二级缓存—》内存—》本地硬盘—》远程硬盘 ;
2.最底层的c语言编写;
3.单线程模式:避免多线程的线程切换以及多线程的数据不安全机制;
持久化
RDB
快照存储,会在硬盘中创建一个RDB二进制文件进行存储数据。当执行save(同步阻塞)或者bgsave(异步非阻塞)命令时或者达到配置文件配置的条件时,就会触发rdb存储。rdb存储的是数据,是redis默认的存储模式。
过程:
1)当有相关操作时,redis父进程调用fork(),创建子进程。
2)父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间中的数据是fork()时刻整个数据库的一个快照。
3)当子进程将快照写入临时文件完毕后,用临时文件替换原有的快照文件,然后子进程退出。
Redis的client也可以使用"save"或者"bgsave"命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程(即单进程)来处理所有client的请求,这种方式将会阻塞所有client请求,不推荐使用。
缺点:
1.每次RDB都是将内存数据完整写入到磁盘一次,并不是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘IO操作,可能会严重影响性能。
2.RDB是根据保存策略来保存数据库,自己定义的保存策略有时间间隔,如果在这个时间间隔redis挂掉,有可能会丢失数据。
AOF
将client发送的每一天有效的命令(修改的命令)写入aof文件尾部。其实是redis将每次写命令刷新到缓存中,然后根据配置的aof策略(三种策略:always 每条都写入;everysec每秒都写入,默认的aof方式;no:由操作系统决定什么时候刷新到硬盘中)将将缓存区的数据保存在磁盘中。aof重写可以解决写命令过多的问题,比如set a 1;set a 10;set a 100配置aof重写之后只保留set a 100这条命令,大大的节省磁盘空间和效率。
过程
1. 所有的写入命令追加到aof_buf缓冲区中。
2. AOF会根据对应的策略向磁盘做同步操作。刷盘策略由appendfsync参数决定。
3. 定期对AOF文件进行重写。重写策略由auto-aof-rewrite-percentage,auto-aof-rewrite-min-size两个参数决定。
重写流程:
1. 执行AOF重写请求。 如果当前进程正在执行bgsave操作,重写命令会等bgsave执行完再执行。
2. 父进程执行fork创建子进程。
3. fork操作完成后,主进程会继续响应其它命令。所有修改命令依然会写入到aof_buf中,并根据appendfsync策略持久化到AOF文件中。
4. 因fork操作运用的是写时复制技术,所以子进程只能共享fork操作时的内存数据,对于fork操作后,生成的数据,主进程会单独开辟一块aof_rewrite_buf保存。
5. 子进程根据内存快照,按照命令合并规则写入到新的AOF文件中。每次批量写入磁盘的数据量由aof-rewrite-incremental-fsync参数控制,默认为32M,避免单次刷盘数据过多造成硬盘阻塞。
6. 新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息。
7. 父进程将aof_rewrite_buf(AOF重写缓冲区)的数据写入到新的AOF文件中。
8. 使用新AOF文件替换老文件,完成AOF重写。
缺点:1.数据恢复没有RBD方式快。
2.AOF常用的持久化策略是everysec,在这种策略下,fsync同步文件操作由专门线程每秒调用一次。当系统磁盘较忙时,会造成Redis主线程阻塞。
3. 主线程负责对比上次AOF同步时间。1> 如果距上次同步成功时间在2s内,主线程直接返回。2> 如果距上次同步成功时间超过2s,主线程会阻塞,直到同步操作完成。每出现一次阻塞,info Persistence中aof_delayed_fsync的值都会加1。所以,使用everysec策略最多会丢失2s数据,而不是1s。
RDB和AOF对比选择?
| 命令 | RDB | AOF |
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略可能丢数据 |
| 轻重 | 重 | 轻 |
数据结构
String
其实只是key是string类型的,value可以使其他数据类型,比如Integer json set类型,但是value不能大于512M,我们一般用这种类型进行缓存,分布式锁,计数器,,,,等等一些功能。
Hash:hash结构是 key field value结构,一个key对应多个field value,简单点理解就是map里面value又是一个map,基本操作:hget key field ;hset key field value;hdel key field;例如:hset user:1:info age 23 理解就是给 user:1:info 这个对象的age属性设置为23;hget user:1:info age 得到user:1:info这个对象的age属性;hgetall user:1:info 得到user:1:info这个对象的所有属性值。hdel user:1:info age 删除user:1:info对象的age属性。
Lists:key-value结构,但是value是一个有序的可重复的队列,操作:rpush key values1 value2 values3.....valueN 右边进行插入。lpop key从左边进行弹出一个item;ltrim key start end 按照索引范围修剪列表;lrang key start end 获取列表指定索引范围所有item。lindex key index 获取列表指定索引item。
Sets:key-value结构,value是一个无序不可重复的集合, 并且支持集合之间的交集并集差集的操作。基本操作是:sadd key element ;删除:srem key element;例如:sadd user:1:follow it news his sports;添加值。smembers user:1:follow;得到所有集合的值。spop user:1:follow;弹出一个值。
Sort Sets:key-value结构,value是一个有序不可重复的集合。在添加key-value的时候会给value一个score分数,分数越低排名靠前。用法:zadd key score element ;element不能重复。zrem key element;删除元素。 zscore key element 返回这个元素的分数。例如:zadd player:rank 1000 ronaldo 900 messi 800 ronaldo 600 kaka; zrank player:rank ronaldo 获取ronaldo排名;
新增的
BitMaps:位图
HyperLogLog:超小内存唯一值计数
GEO:地理信息定位
多语言支持
java php python ruby lua nodejs等等都有相应的redis api调用。
功能丰富
处理对redis做一些简单的存储之外。还可以做一些发布订阅 事务 Lua脚本自定义功能 pipeline,,,,,等等功能。
(pipeline功能不是原子性的,只是将所有的命令集中在一起,一次访问,减少多次访问的网络开销。pipeline命令没有原生的mget mset命令快,mget mset是原子性命令,但是pipeline命令能够处理不同的key,而m系列的命令只能对一个key进行操作);
发布订阅:publish channel message 发布消息 。比如:publish sohu:tv "hello world" ;subscribe sohutv 当前客户端订阅这个频道; unsubscribe sohu:tv 当前客户端取消订阅这个频道
简单
单机的核心代码只有23000行,集群代码大概在50000行左右。redis不需要依赖外部库,而且是单线程模式。
Redis安装
wget http://download.redis.io/releases/redis-3.0.7.tar.gz 下载
tar -xzf redis-3.0.7.tar.gz 解压
redis-3.0.7 redis 建立软连接方便以后升级
cd redis
make && make install 安装
安装完成之后 会看到
redis-server:redis服务器。 redis-cli:redis命令行客户端。
redis-benchmark:redis性能测试工具。 redis-check-aof:AOF文件修复工具。
redis-check-dump:RDB文件检查工具。 redis-sentinel:Sentinel服务器
Redis启动(三种)
最简单启动:redis-server redis的默认配置文件启动。
动态参数启动: redis-server --port 6380 手动添加参数进行启动
配置文件启动:redis-server configPath(配置文件路径) 启动的时候指定配置文件 (推荐!!)
启动完成可以用 ps -ef | grep redis 或者 netstat -antpl | grep redis 进行查看启动状态
redis客户端连接
redis-cli -h ip地址 -p 端口号 这样就可以连接已经启动的客户端。
redis常用配置(redis.conf)
daemonize:是否是守护进程(no/yes),一般设置yes;
port:Redis对外的端口号,默认是6379;
logfiel:Redis系统日志;
dir:Redis工作目录;
redis基本命令
select 1:选择redis在哪个库(redis默认支持16个数据库);
get keyName:根据key得到value;
set key value:设置保存key value;
keys *:查看所有的key,时间复杂度是O(n)不建议用;
dbsize:计算key的总数;
exists key:判断key是否存在(1存在0不存在);
del key:删除指定key-value;
expire key seconds:key在seconds秒后过期;
ttl key:查看key剩余的过期时间;
persist key:去掉key的过期时间;
type key:返回key的类型;
redis与java客户端的使用(jedisAPI使用)
String:jedis.set("hello","world"); jedis.get("hello"); jedis.incr("counter");
hash:jedis.hset("myhash","key1","value1"); jedis.hset("myhash","key2","value2"); jedis.getAll("myhash");
list:jedis.rpush("mylist","1"); jedis.rpush("mylist","2"); jedis.rpush("mylist","3") ; jedis.lrange("mylist",0,-1);
set:jedis.sadd("myset","a"); jedis.sadd("myset","b"); jedis.sadd("myset","a"); jedis.smembers("myset");
zset:jedis.zadd("myzset",99,"tom"); jedis.zadd("myzset",66,"peter"); jedis.zadd("myzset" ,33,"yaoming"); jedis.zrangWithScores("myzset",0,-1);
jedis连接方案:
jedis直连:1.生成je dis对象;2.jedis执行命令;3.返回执行结果;4.关闭jedis连接。(每次建立tcp连接并且完成之后需要关闭,不推荐)。
jedisPool使用:如图: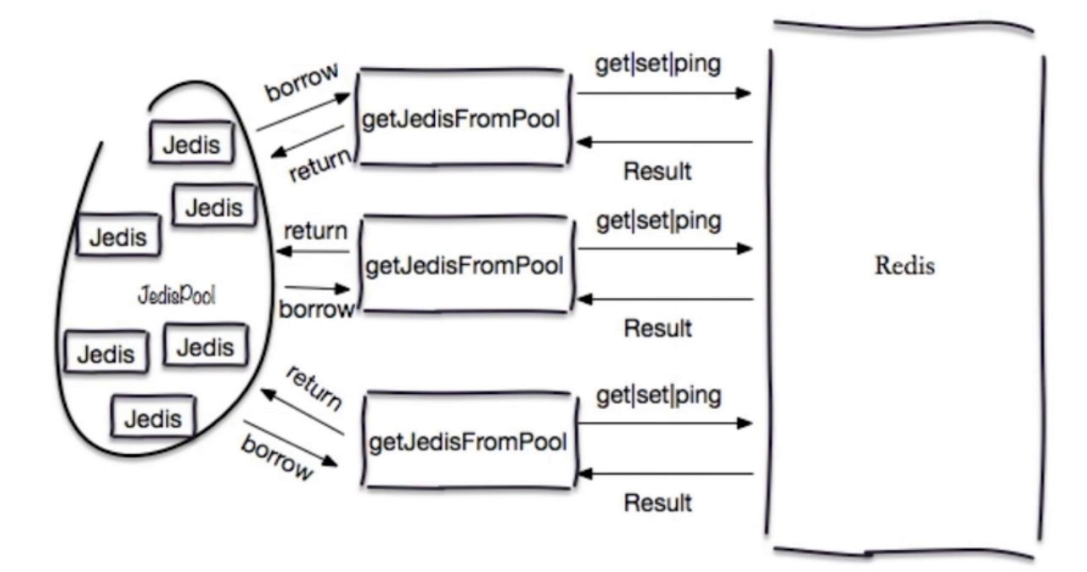
1.从资源池借用jedis对象 2.jedis执行命令 3.返回执行结果 4.归还jedis对象给连接池。
分布式集群高可用
redis单机存在redis机器故障,容量瓶颈,QPS瓶颈这系列问题,布置高可用的redis部署非常重要。
主从复制
redis主从复制无需过多的配置,只需要在从节点配置主节点的id即可。slaveof id port;配置之后就形成了简单的主从复制的架构。
主节点master:master节点一般对外写数据,一个master可以有多个slave;
从节点slave:slave节点对外提供读数据,一个slave只能有一个master,数据会从master同步到slave;
当master的数据发生变化时,会将数据同步到slave上,数据流向只能是master——>slave上。
当slave第一次需要同步数据时,会全量复制master上数据,具体步骤如下:
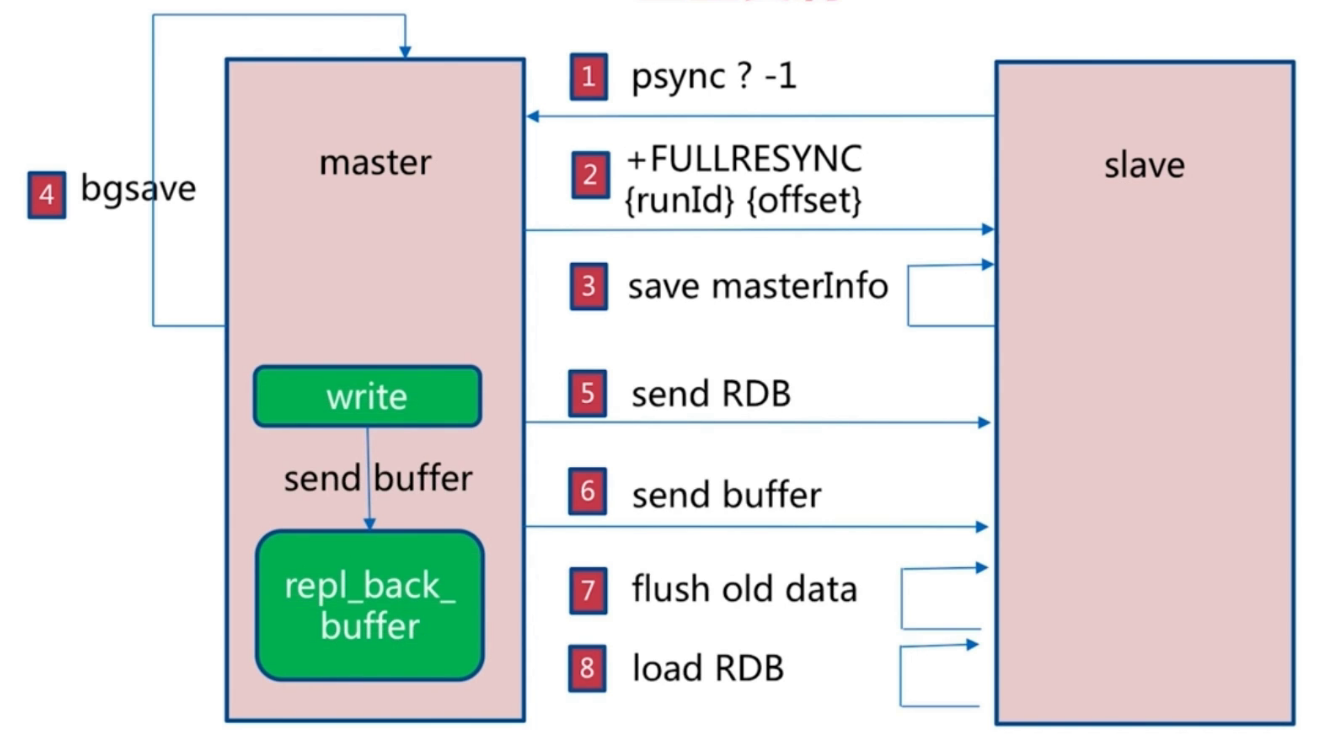
1.slave发送psync传个?-1参数到master表示slave自身并不知道runid和偏移量是多少。
2.master将自身的偏移量和runid发给slave。
3.slave保存master的runid和slave。
4.master启动beslave命令生成RDB数据文件。并且将心进来的写数据缓存在一个buffer内存中。
5.master发送RDB数据文件。
6.master发送buffer缓存数据。
7.slave清除自身旧数据。
8.slave加载RDB和buffer数据。
全量复制会有大量资源开销,很占内存:
1.bgsave时间;2.RDB文件从master传slave的网络开销;3.slave清除数据;4.slave加载RDB文件;
当slave并非第一次数据同步时或者网络连接断开恢复,会部分复制master上数据,具体步骤如下:
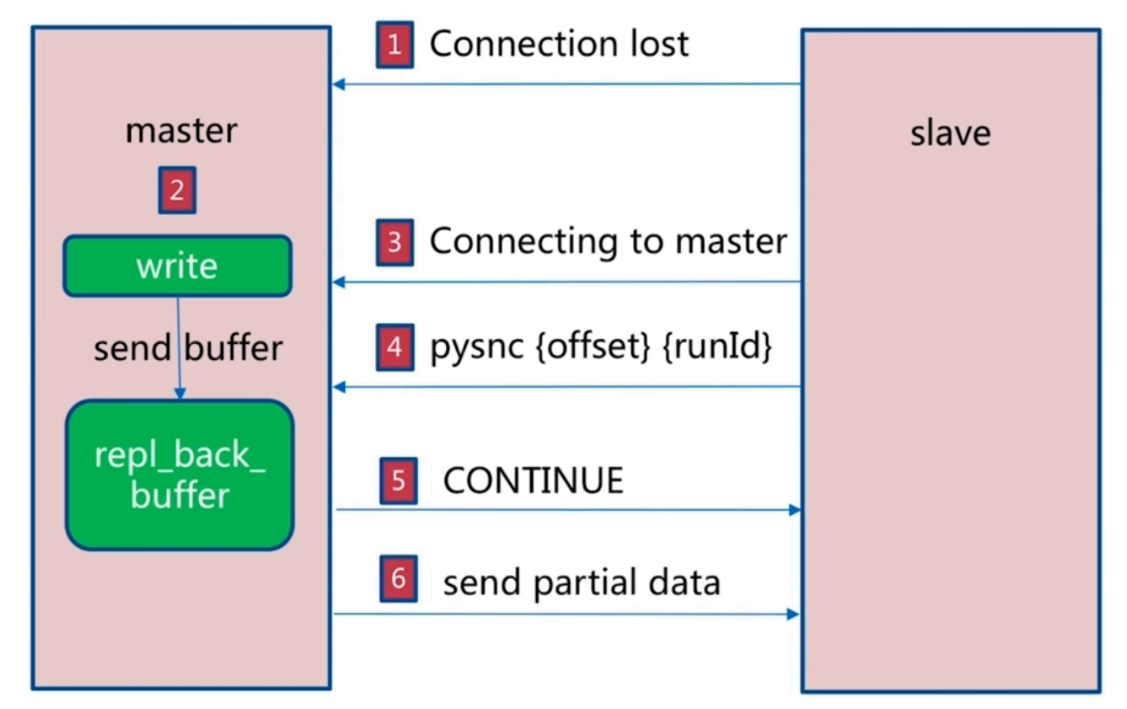
1.slave和master断开网络连接,slave尝试重新和master建立连接。
2.master将新的写数据写入一个buffer缓存中。
3.当slave和master恢复网络连接后,slave将runid和偏移量发个master,
4.master根据runid和偏移量重新将buffer数据传输给slave(master判断slave的offset是否在buffer的队列里面,如果是,那就返回continue给slave,否则需要进行全量复制)。
5.slave写数据。
主从复制的故障处理
当slave发生故障时,client端只需要将连接发送到另一个slave端即可,待slave重新启动之后会自动连接到master上。
当master发生故障时,会导致client端的写命令无效。首先需要断开master和所有slave的主从关系,拿一个slave把他设置成master,然后将所有的slave与新的master设置成主从关系,如果这个slave设置成master的数据并不完整,将会导致数据丢失。
无论是slave还是master发生故障,都需要程序员去人为的进行调解恢复,手动的不仅麻烦,而且难免会有不可预料的事故发生。所以后来才有的sentinel模式(哨兵模式)
特点
优点:1.解决单机故障的数据丢失和不可用问题。
2.实现读写分离,分散流量。
缺点(要注意的问题):
1、读写分离:
①复制数据的延迟:例如从节点发生阻塞,就会到值复制数据的延迟。
②读到过期的数据。
③从节点也有可能发生故障
2、配置不一致
①例如maxmemory不一致,容易丢失数据,或者发生诡异的情况
②数据结构优化参数(例如has-max-ziplist-entries):会出现内存不一致的情况
3、规避全量复制
①第一次全量复制:第一次不可避免,但是我们可以使用小的主节点,或者在半夜低峰的时刻做全量复制。
②节点运营的ID不匹配:例如主节点重启,runid就会变化,我们可以使用自动故障转移,例如哨兵或者集群。
③复制积压缓冲区不足:网络中断,部分复制功能无法满足,这个时候可以增大复制缓冲区配置rep_backlog_size。默认1m。
4、规避复制风暴
①单主节点复制风暴:由于主节点从起,多个从节点要复制,会产生复制风暴,解决办法是:哨兵和集群模式。
②单机器复制风暴:由于多个主节点都部署在同一个机器上面,机器宕机后需要大量的全量复制,解决办法是:主节点分配到多台机器上面或者使用一些高可用架构,讲从节点晋升为主节点。
5、master发生故障时必须要手动恢复。
sentinel(哨兵模式)
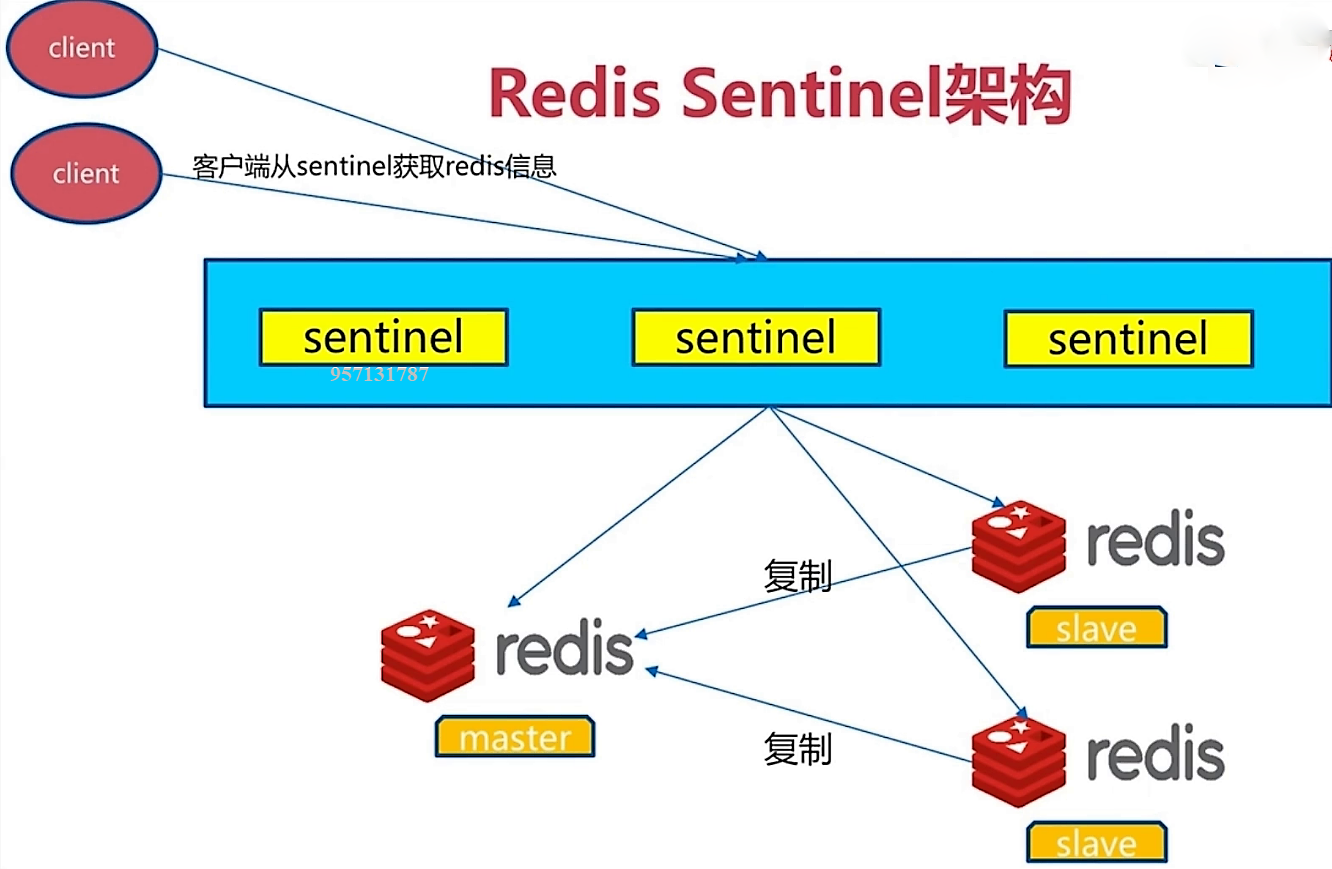
由sentinel自身主建一个集群,让sentinel本身就是一个高可用,然后将redis的主从结构全部交割sentinel管理,client连接sentinel,由sentinel负责将命令分配到client想连接的master。sentinel系统可以监视一个或者多个redis master服务,以及这些master服务的所有从服务;当某个master服务下线时,自动将该master下的某个从服务升级为master服务替代已下线的master服务继续处理请求。这样不仅能够实现主从复制读写分离,还能有效的规避master发生故障时动态实施slave到master的动态切换。
Sentinel工作方式(每个Sentinel实例都执行的定时任务)
1.每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个PING命令。
2.如果一个实例(instance)距离最后一次有效回复PING命令的时间超过 own-after-milliseconds 选项所指定的值,则这个实例会被Sentinel标记为主观下线。
3.如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4.当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线。
5.在一般情况下,每个Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave发送 INFO 命令。
6.当Master被Sentinel标记为客观下线时,Sentinel 向下线的 Master 的所有Slave发送 INFO命令的频率会从10秒一次改为每秒一次。
7.若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除。 若 Master重新向Sentinel 的PING命令返回有效回复,Master的主观下线状态就会被移除。
8.当master被认为客观下线时,所有的sentinel就会选举出一个leader进行主从切换的工作。
三个定时任务
sentinel在内部有3个定时任务
1.每10秒每个sentinel会对master和slave执行info命令,这个任务达到两个目的:
a)发现slave节点
b)确认主从关系
2.每2秒每个sentinel通过master节点的channel交换信息(pub/sub)。master节点上有一个发布订阅的频道(__sentinel__:hello)。sentinel节点通过__sentinel__:hello频道进行信息交换(对节点的"看法"和自身的信息),达成共识。
3.每1秒每个sentinel对其他sentinel和redis节点执行ping操作(相互监控),这个其实是一个心跳检测,是失败判定的依据。
主观下线:一个sentinel节点对redis节点发生ping命令在规定的时间范围内没有收到回复,或者返回一个错误,那么 Sentinel 将这个服务器标记为主观下线
客观下线:客观下线就是说只有在足够数量的(>=quorum) Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(ODOWN)。只有当master被认为客观下线时才会被故障转移。
sentinel领导者选举
一个master被判断为客观下线时,多个监视sentinel协商,选举一个领头sentinel,对该redis服务进行故障转移操作。选举领头sentinel遵循以下规则:
1)所有的sentinel都有公平被选举成领头的资格。
2)所有的sentinel都有且只有一次将某个sentinel选举成领头的机会(在一轮选举中),一旦选举某个sentinel为领头,不能更改。
3)sentinel设置领头sentinel是先到先得,一旦当前sentinel设置了领头sentinel,以后要求设置sentinel为领头请求都会被拒绝。
4)每个发现服务客观下线的sentinel,都会要求其他sentinel将自己设置成领头。
5)当一个sentinel(源sentinel)向另一个sentinel(目sentinel)发送is-master-down-by-addr ip port current_epoch runid命令的时候,runid参数不是*,而是sentinel运行id,就表示源sentinel要求目标sentinel选举其为领头。
6)源sentinel会检查目标sentinel对其要求设置成领头的回复,如果回复的leader_runid和leader_epoch为源sentinel,表示目标sentinel同意将源sentinel设置成领头。
7)如果某个sentinel被半数以上的sentinel设置成领头,那么该sentinel既为领头。
8)如果在限定时间内,没有选举出领头sentinel,暂定一段时间,再选举。
故障转移slave的选取原则
1.选择slave-priority(slave节点优先级)最高的slave节点,如果存在则选中返回,不存在则继续2 3;
2.选择slave中偏移量最大的slave节点,偏移量最大,表明他的数据最完整。不存在则继续3;
3.选择runid最小的slave节点;
扩展
sentinel只能对master进行一个故障转移,但是无法对slave节点进行一个转换,但我们client连接读写分离时,master发生故障slave被选举成为master或者slave主观下线或者master故障后恢复变成slave,面对这些情况客户端并不知情,导致读写分离会发生混乱。面对这种情况,我们可以自己定义一个连接池对slave连接进行统一的管理,当master发生故障slave被选举成为master或者slave主观下线或者master故障后恢复变成slave时,连接池的slave连接也发生相应变化。但是还是会发生连接不可用读数据失败的情况发生。
sentinel特色
优点:解决主从复制的手动问题。
缺点:对于读写分离功能并不完善,slave节点不能从容变换。
cluster集群
随着主从复制以及哨兵的一些缺陷。redis在2015年的redis3.0版本中集群cluster模式就很好的解决了这些问题。
1:能够容纳更多的访问量,并发量。
2:能用的内存更大。可以将数据分布在不同的机器中。
3:运用虚拟槽分区淡化节点的管理,只需要对虚拟槽进行数据管理就可以了。
redis cluster的具体实现细节是采用了Hash槽的概念,集群会预先分配16384个槽,并将这些槽分配给具体的服务节点,通过对Key进行CRC16(key)%16384运算得到对应的槽是哪一个,从而将读写操作转发到该槽所对应的服务节点。当有新的节点加入或者移除的时候,再来迁移这些槽以及其对应的数据。
搭建流程
启动节点
启动一个reids节点,并且将配置文件redis-config中参数cluster-enabled:yes 表明这是一个cluster模式启动。
meet
启动完之后需要将这些节点进行meet操作。所有节点的信息共享。命令cluster meet ip port ,例如:redis -cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001 这就是将7000的redis节点和7001的节点进行meet。(注意:当A节点分别和B、C节点分别进行meet时,那么B C节点就自然meet了,不用专门为B C进行meet操作)
分配槽
将16384个节点分配启动的这些已经meet完成的节点。当client对某个节点发生get取数据请求时,如果数据所有在的槽在这个节点上,那么返回该数据,如果不在这个节点对应的槽上,那么会将对应的节点和槽返回客户端。clister addslots slot[slot...] 例如:redis -cli -h 127.0.0.1 -p 7000 cluster addslots {0...5461}
设置主从关系
cluster模式也需要主从复制的关系配置,当一个主节点挂了之后也需要从节点顶上代替主节点。cluster replicate node-id,例如:redis-cli -h 127.0.0.1 -p 7003 cluster replicate ${node-id-7000}
集群扩容
准备新的节点—>将新的节点加入集群—>迁移槽和数据
集群收缩
判断是否持有槽,如果有—>迁移槽到其他节点—>通知其他节点忘记下线节点—>关闭节点
redis的访问处理方式
moverd重定向
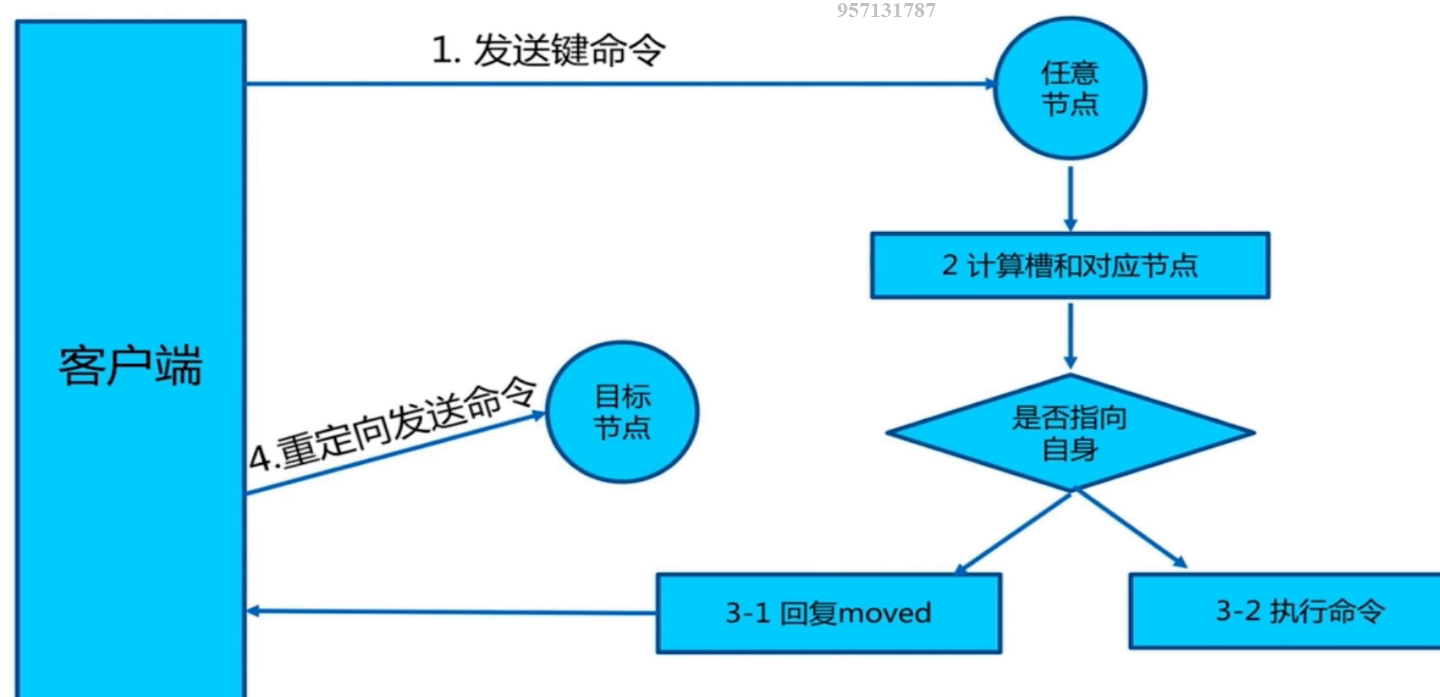
当访问某个节点读取或者操作数据时,这个节点会通过CRC16算法计算key所在的槽,如果这个key被分配到这个节点的槽上,就直接返回结果;如果不在这个节点对应的槽上,就返回一个moved异常,错误信息中有正确的节点和槽信息,client需要重定向到正确的节点槽上。
ask
当redis-cluster进行节点扩容时或者收缩时,槽的节点信息和client上记录的信息不一致,当client发送信息时,节点会返回一个ask转向异常,client需要执行ask转向异常命令,然后再发送命令道target节点。
与moved区别:
1. 两者都是客户单项重定向。
2.moved时候表明槽已经确定迁移完成,而ask表明槽还正在迁移过程中。
当redis-cluster模式节点过多的时候,我们每次读写操作都会出现大量的转发工作,大大的降低了运行的效率,所有smart客户端对这种模式的请求做了优
化: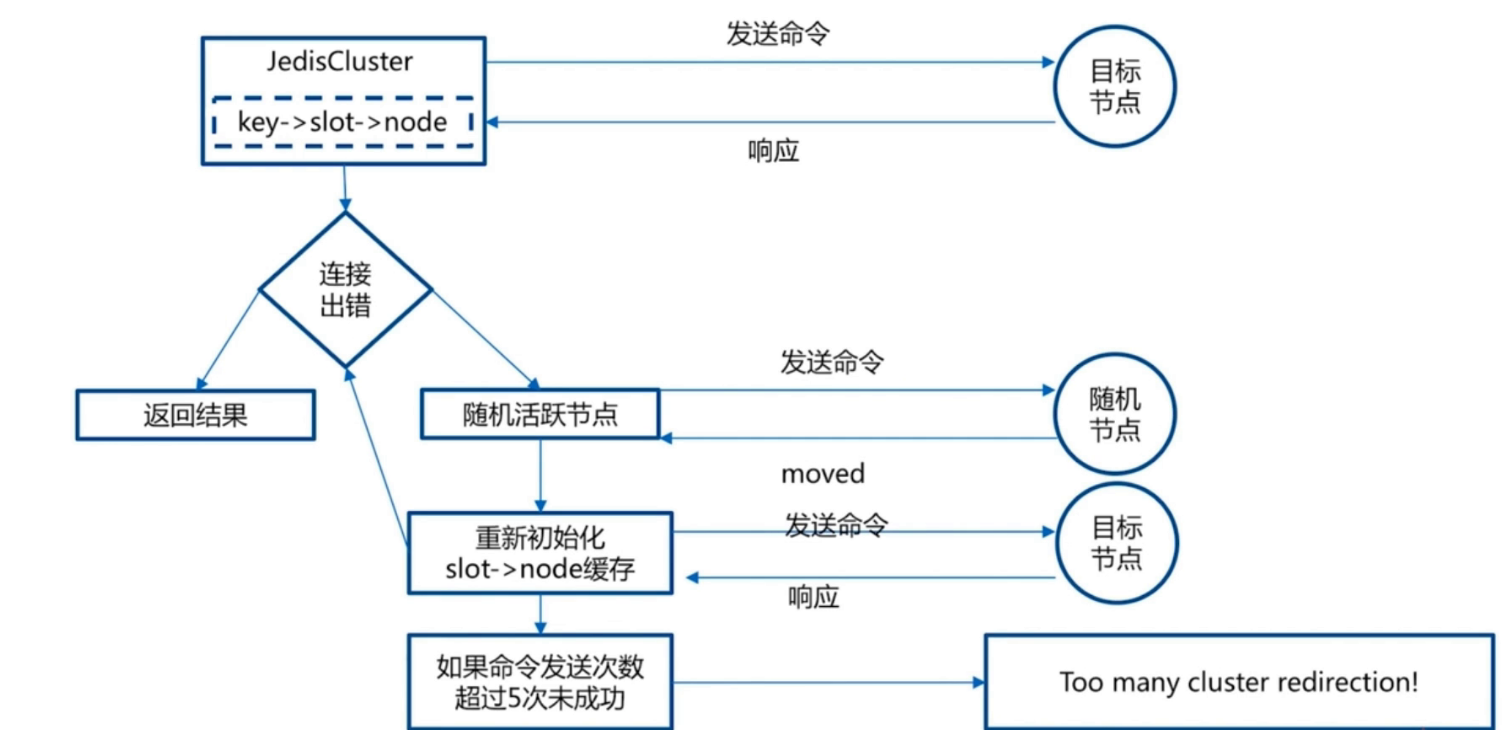
思路:将cluster slots和节点关系映射到本地缓存,并且为每个节点创建jedispool。而key和slots的关系是通过CRC16算法得到的,所以key和节点关系也能确定。java的客户端redisCluster就很好的帮我们实现了这一点,基本代码实现如下:
Set<HostAndPort> nodeList = new HashSet<HostAndPort>(); //构建一个存放节点的set集合
nodeList.add(new HostAndPort(host1,port1)); //添加节点
nodeList.add(new HostAndPort(host2,port2));
nodeList.add(new HostAndPort(host3,port3));
...
JedisCluster jedisCluster = new JedisCluster(nodeList,timeOut,poolConfig)//构建redisCluster,后面所有的操作均在redisCluster上执行
jedisCluster.set(key,value);//存值
jedisCluster.get(key);//取值
//jedisCluster很好的帮助我们做了封装,不用让我关注redisCluster中的moved和ask问题,大大的简化了我们开发的工作量。
redisCluster的mget ,mset的批量操作
redisCluste虽然支持批量操作(多个key操作),但是要求key必须在同一个槽上,这显然不符合我们的业务要求。这是我们可以对批量操作做自己的一个封装。
1.client用for循环不断地调用get方法请求key;(n个key就要请求n次网络请求)
2.jedisCluster在本地缓存了节点和slots的对应信息,我们可以用CRC16算法将所有请求key映射到slots上再映射到节点上,将同一个节点的key封装在同一个请求中,在执行pipeline请求得到结果。(n个key对应i个节点,需要i次网络请求)
3.对2进行一个优化,用多线程去执行i次网络请求。
4.hash_tag方法,将所有的key进行一次hash算法,保证所有key经过hash之后或被分到同一个槽上。
redisCluster的高可用
redis-cluster模式中,每个redis节点之间会通过ping/pong消息实现故障发现:不需要sentinel。和sentinel类似,也分为主观下线和客观下线。
主观下线:某一个节点人为另一个节点不可用。超过node-timeout时间还未恢复pong消息,则标为主观下线。
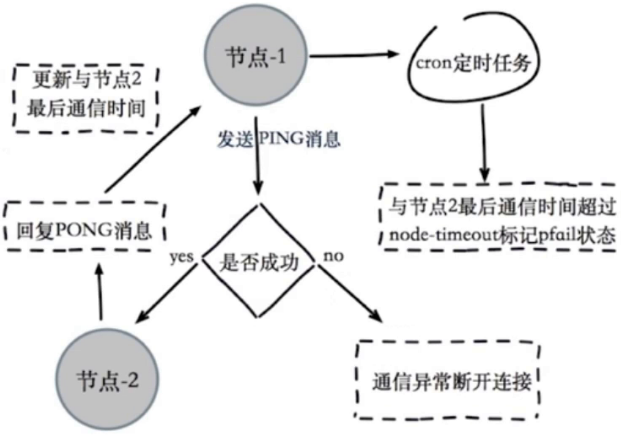
客观下线:当半数以上持有槽的主节点都标记某节点主观下线。(只有主节点有决定权),主节点内部会维护一个每个节点之间的状态表,计算表中主观下线的个数。更新某个主节点为客观下线会向集群广播下线节点的fail消息。
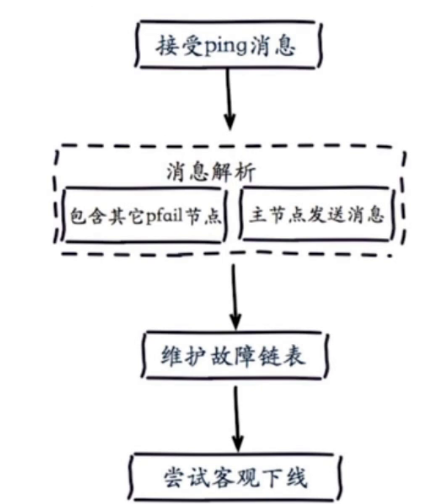
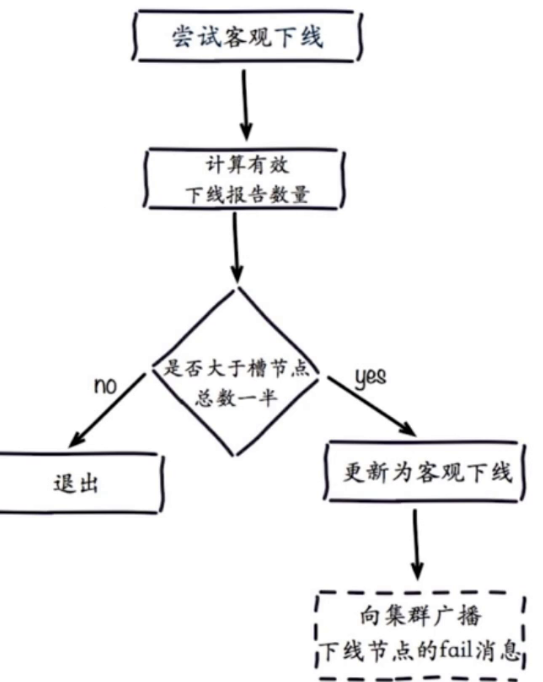
当主节点被下线时,会从该主节点中选举一个从节点来代替主节点,规则是从节点的偏移量越大时,准备选举时间越短,越优先被选举,大于N/2+1的节点投票时,该从节点就会被选举为主节点。
替换主节点:1.当前从节点取消复制变为主节点。(slaveof no one)
2.执行clusterDelSlot 撤销故障节点负责的槽,并执行clusterAddSlot把这些槽分配给自己。
3.向集群广播自己的pong消息,表明已经替换了故障从节点。
常见问题
集群完整性:cluster-require-full-coverage默认为yes,必须要所有槽可用才能保证集群可用。一般我们需要设置为no。如果设置为yes,那么在故障转移的时候将会导致整个集群都不可用。
集群带宽消耗: 每个主节点之间进行Gossip带宽消息会产生大量的带宽消耗,官方建议是1000个节点。(1.消息发送频率:节点发现与其他节点最后通信时间超过cluster-node-timeout/2时就会直接发送ping消息;2.消息数据量:slots槽数组和整个集群1/10的状态数据;3.节点部署的机器规模:集群分布的机器越多且每台机器划分的节点数越均匀,则集群内整体的可用带宽越高)
pub/sub广播局限性:publist在集群每个节点广播:加重带宽。
数据倾斜:1.节点和槽分配不均与;2.不同槽对应键值对数量差异较大;3.包含bigkey(value特别大);4.内存相关配置不一致;
读写分离:redis-cluster模式下从节点不接受任何读写请求,只作为主节点的备用节点。需要自己实现客户端。
数据迁移:官方迁移工具redis-trib.rb import不支持在线迁移,不支持断点续传,只能从单机迁移到集群,单线程影响速度。可以用第三方迁移工具:唯品会的redis-migrate-tool 豌豆荚的redis-port。
集群VS单机
集群key批量操作支持有限:例如mget、mset必须在一个slot上。命令无法跨节点使用:mget,keys,scan,flush,sinter等。
key事务和lua支持有限:操作的key必须在一个节点上。
key是数据分区最小粒度:不支持bigkey分区。
不支持多数据库:集群模式下只有一个db0。
复制只支持一层:不支持树形复制结构。
很多情况下redis-sentinel模式就能满足要求。
缓存的使用与设计
缓存的收益和成本:收益:通过缓存加速读写速度,降低后端的负载(比如业务端使用reids降低后端mysql负载等)。成本:数据不一致,缓存中和持久层的数据不一致;代码维护中多一层逻辑,比如redis;运维成本:部署redis cluster需要运维维护。
缓存更新策略:1.LRU/LFU/FIFO算法剔除:例如 maxmemory-prolicy;2.超时剔除:例如expire。3.手动控制过期时间。
缓存粒度控制:1.通用性:全量属性更好;2.占用内存空间:部分属性更好;3.代码维护:表面全量属性更好。
缓存穿透优化:当clinet请求数据库时,先到缓存中查找想要的信息,如果缓存中没有,再去数据库中查找,找到后把数据写入缓存中,再返回结果。方案1:缓存空对象,设置过期时间。(如果恶意爬虫将会短期造成大量的key)。方案2:布隆过滤器拦截。事先设置一些无效的访问信息,当这些请求过来时,直接被过滤掉。
无底洞问题优化:2010年facebook有了3000个memcache节点,再加节点的时候发现性能没有提升,反而下降了。问题:更多机器并不等于更高性能;批量接口需求优化;数据增长与水平扩展需求。优化:1.减少慢查询keys,hgetall,bigkey;2.减少网络通信次数;3.降低接入成本,例如客户端长连接、连接池。
缓存雪崩优化: 当缓存奔溃或者缓存中不存在数据有大量的请求直接请求db数据库,造成数据库瞬间卡死了崩溃。解决方案:1.设置redis集群和DB集群的高可用,如果redis出现宕机情况,可以立即由别的机器顶替上来。2.客户端降级。3.缓存预热。
热点key重建优化:目标1.减少重建缓存的次数。2.数据尽可能一致。3.减少潜在危险。解决方案,方案1:互斥锁;2.永不过期。















 3277
3277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









