






- elasticsearch环境搭建
系统为centos 6.5
使用的版本号为 elasticsearch-5.6.4,下载并解压 ,
启动项目 sh {路径}/elasticsearch-5.6.4/bin/elasticsearch
打开 http://localhost:9200/ 在浏览器中看到
{
"name" : "JQHHw3L",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "bgApOt6jQQefCdZp5eZu-A",
"version" : {
"number" : "5.6.4",
"build_hash" : "8bbedf5",
"build_date" : "2017-10-31T18:55:38.105Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
说明已经启动成功了。
- HEAD 插件安装
目前 elastic 5.X以上版本 head 好像不支持 plugin installl,只能通过node 来安装
需要先安装nodejs和npm
yum install nodejs
yum install npm下载 elastichead 并解压并安装
安装 npm install
启动 npm run start
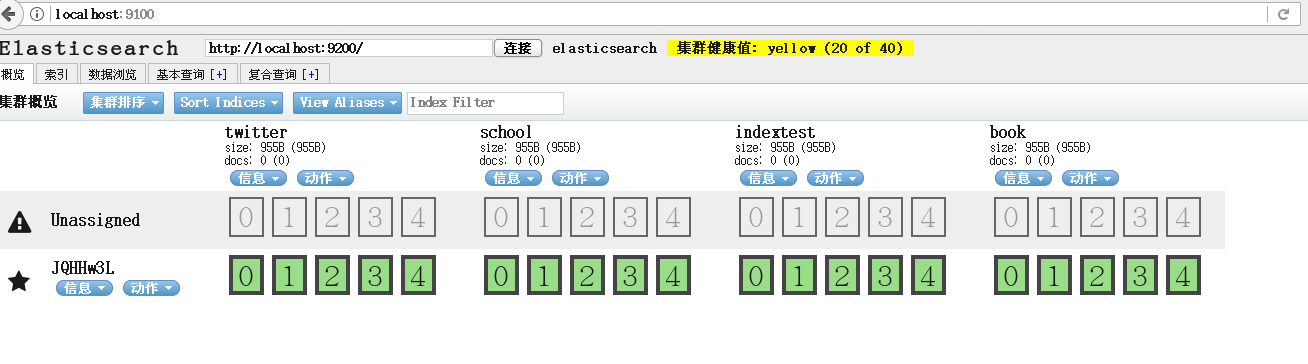
打开http://localhost:9100/ 看到以下图片表示成功(第一次打开不会显示图中的index)
- 新建Spring Boot 的项目
这里使用的是1.4.3 版本。引入elasticsearch的依赖(版本号一定要和安装到elasticsearch版本一致)。
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <elasticsearch.version>5.6.4</elasticsearch.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>${elasticsearch.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>
添加elasticsearch的 config配置
@Configuration public class ElasticsearchConfig { @Value("${elasticsearch.cluster.name}") private String clusterName; @Value("${elasticsearch.host}") private String host; @Bean public TransportClient transportClient() throws UnknownHostException { // 设置集群名称 Settings settings = Settings.builder().put("cluster.name", clusterName) .build(); TransportClient transportClient = new PreBuiltTransportClient(settings); String[] nodes = host.split(","); for (String node : nodes) { if (node.length() > 0) { String[] hostPort = node.split(":"); transportClient.addTransportAddress( new InetSocketTransportAddress( InetAddress.getByName(hostPort[0]), Integer.parseInt(hostPort[1]))); } } return transportClient; } }
在配置文件中application.properties 加入 以下配置, elasticsearch 的默认name 是 elasticsearch,
也可以自定义设置。
server.port=8080 elasticsearch.cluster.name=elasticsearch elasticsearch.host=127.0.0.1:9300
下面是service 和 test (为了方便测试,一些数据直接写在service内了)
package per.wxp.elasticsearchDemo.Service; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.elasticsearch.action.ActionFuture; import org.elasticsearch.action.admin.indices.analyze.AnalyzeRequest; import org.elasticsearch.action.admin.indices.analyze.AnalyzeResponse; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse; import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest; import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsResponse; import org.elasticsearch.action.bulk.BulkProcessor; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkRequestBuilder; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.get.MultiGetItemResponse; import org.elasticsearch.action.get.MultiGetResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.search.SearchType; import org.elasticsearch.action.update.UpdateRequest; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.transport.TransportClient; import org.elasticsearch.common.settings.Settings; import org.elasticsearch.common.unit.ByteSizeUnit; import org.elasticsearch.common.unit.ByteSizeValue; import org.elasticsearch.common.unit.Fuzziness; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.index.query.*; import org.elasticsearch.index.reindex.BulkByScrollResponse; import org.elasticsearch.index.reindex.DeleteByQueryAction; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder; import org.elasticsearch.search.sort.FieldSortBuilder; import org.elasticsearch.search.sort.SortOrder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import per.wxp.elasticsearchDemo.entity.IndexInfo; import javax.annotation.PostConstruct; import java.io.IOException; import java.io.StringReader; import java.text.SimpleDateFormat; import java.util.*; import java.util.concurrent.ExecutionException; @Service public class ElasticSearchService { @Autowired private TransportClient client; private BulkProcessor bulkProcessor; @PostConstruct public void init() { this.bulkProcessor = BulkProcessor.builder(client,new BulkProcessor.Listener(){ @Override public void beforeBulk(long l, BulkRequest bulkRequest) { } @Override public void afterBulk(long l, BulkRequest bulkRequest, BulkResponse bulkResponse) { } @Override public void afterBulk(long l, BulkRequest bulkRequest, Throwable throwable) { } } ) .setBulkActions(100) .setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)) .setFlushInterval(TimeValue.timeValueSeconds(5)) .setConcurrentRequests(2).build(); } /* --------------------------基本类型操作 index type mapping document -------------------------- */ /** * 新建 index 默认值配置 * @param indexName */ public void createIndex(String indexName) { CreateIndexResponse indexResponse = client.admin().indices().prepareCreate(indexName).get(); System.out.println("索引名字=" + indexResponse.index() + "---" + indexResponse.isShardsAcked()); } /** * 新建 index 、 type 、mapping */ public void createIndexWithType(String indexName, String typeName) throws IOException { XContentBuilder mapping = XContentFactory.jsonBuilder() .startObject() .startObject("properties") //设置之定义字段 .startObject("author") .field("type", "string") //设置数据类型 .endObject() .startObject("title") .field("type", "string") .endObject() .startObject("content") .field("type", "string") .endObject() .startObject("price") .field("type", "string") .endObject() .startObject("view") .field("type", "string") .endObject() .startObject("tag") .field("type", "string") .endObject() .startObject("date") .field("type", "date") //设置Date类型 .field("format", "yyyy-MM-dd HH:mm:ss") //设置Date的格式 .endObject() .endObject() .endObject(); client.admin().indices().prepareCreate(indexName) .addMapping(typeName, mapping) .get(); } /** * 在存在的index内新建 type * The PUT mapping API also allows to add a new type to an existing index: */ public void createTypeWithMapping(String indexName, String typeName) throws IOException { XContentBuilder mapping = XContentFactory.jsonBuilder() .startObject() .startObject("properties") //设置之定义字段 .startObject("author") .field("type", "string") //设置数据类型 .endObject() .startObject("title") .field("type", "string") .endObject() .startObject("content") .field("type", "string") .endObject() .startObject("view") .field("type", "string") .endObject() .startObject("tag") .field("type", "string") .endObject() .startObject("date") .field("type", "date") //设置Date类型 .field("format", "yyyy-MM-dd HH:mm:ss") //设置Date的格式 .endObject() .endObject() .endObject(); client.admin().indices().preparePutMapping(indexName) .setType(typeName) .setSource(mapping) .get(); } /** * index 索引是否存在 */ public boolean inExistsRequest(String indexName) { IndicesExistsRequest inExistsRequest = new IndicesExistsRequest(indexName); IndicesExistsResponse inExistsResponse = client .admin() .indices() .exists(inExistsRequest) .actionGet(); System.out.println("是否存在:" + inExistsResponse.isExists()); return inExistsResponse.isExists(); } /** * 删除 索引 */ public boolean deleteIndex(String indexName) { IndicesExistsRequest inExistsRequest = new IndicesExistsRequest(indexName); IndicesExistsResponse inExistsResponse = client .admin() .indices() .exists(inExistsRequest) .actionGet(); DeleteIndexResponse dResponse = null; if (inExistsResponse.isExists()) { dResponse = client.admin().indices().prepareDelete(indexName).execute().actionGet(); } System.out.println("是否删除成功:" + dResponse.isAcknowledged()); return dResponse.isAcknowledged(); } /* ------------------------insert Document------------------------------------------------------- */ /** * 插入 Document */ public void insertDocument( String indexName, String typeName,String id,XContentBuilder source) throws IOException { IndexResponse response = client.prepareIndex(indexName, typeName, id).setSource(source).get(); System.out.println(response.status()); System.out.println(response.getId()); } /* ------------------------update Document------------------------------------------------------- */ public void updateDocumentById(String indexName,String typeName,String id,XContentBuilder source) { UpdateResponse response = client .prepareUpdate(indexName, typeName, id) .setDoc(source) .get(); } public void upsertDocument(String indexName,String typeName,String id,XContentBuilder source) throws IOException, InterruptedException, ExecutionException { IndexRequest indexRequest = new IndexRequest(indexName, typeName, id) .source(source); UpdateRequest updateRequest = new UpdateRequest(indexName, typeName, id) .doc(source) .upsert(indexRequest); client.update(updateRequest).get(); } /* ----------------------------del Document------------------------------------------------------- */ /** * 通过 id 删除 document */ public void deleteById(IndexInfo info) { DeleteResponse response = client.prepareDelete(info.getIndexName(), info.getTypeName(), info.getId()) .get(); System.out.println(response.toString()); System.out.println("状态" + response.status()); } /** * 查询条件 删除 document * */ public void deleteByQuery() { BulkByScrollResponse response = DeleteByQueryAction.INSTANCE.newRequestBuilder(client) .filter(QueryBuilders.matchQuery("gender", "male")) .source("persons") //index name .get(); //number of deleted documents long deleted = response.getDeleted(); System.out.println(response.getStatus()); } /* ----------------------------view Document------------------------------------------------------- */ /** * 根据 id 查看 Document */ public Map<String, Object> getDocumentById(IndexInfo info) { if (info.getId().isEmpty()) { return null; } GetResponse response = client.prepareGet(info.getIndexName(),info.getTypeName(), info.getId()) .setOperationThreaded(false) // 线程安全 .get(); if (!response.isExists()) { System.out.println("查询为空"); return null; } return response.getSource(); } /** * 查询 index 下所有数据 */ public void getAllDocumentByIndex(String indexName) { QueryBuilder queryBuilders=QueryBuilders.matchAllQuery(); SearchResponse response=client.prepareSearch(indexName).setQuery(queryBuilders).get(); printlnResouce(response); } /** * 查询 type 下所有数据 */ public void getAllDocumentByType(String indexName,String type) { SearchResponse response=client.prepareSearch(indexName).setTypes(type).get(); printlnResouce(response); } /** * bool 组合 条件查询 * @param indexName * @param type */ public void queryDocument(String indexName,String type) { BoolQueryBuilder query=QueryBuilders.boolQuery(); query.must(QueryBuilders.matchQuery("title","spark机器学习")); query.must(QueryBuilders.matchQuery("author","Nick Pentreath")); SearchResponse response=client.prepareSearch(indexName).setTypes(type).setQuery(query).get(); printlnResouce(response); } /** * 查询方法 * @param indexName * @param type * @param queryBuilder */ public void QueryBuilderFuction(String indexName,String type,QueryBuilder queryBuilder){ SearchResponse response = client.prepareSearch(indexName).setTypes(type).setQuery(queryBuilder).get(); System.out.println(response.getHits().totalHits); printlnResouce(response); } // Span First public void spanFirstQuery(String indexName){ QueryBuilder queryBuilder =QueryBuilders.spanFirstQuery( QueryBuilders.spanTermQuery("title", "spark"), // Query 10000 // Max查询范围的结束位置 ); SearchResponse response = client.prepareSearch(indexName).setQuery(queryBuilder).get(); System.out.println(response.getHits().totalHits); printlnResouce(response); } /* * 查询遍历抽取 * @param queryBuilder */ private void searchFunction(QueryBuilder queryBuilder) { SearchResponse response = client.prepareSearch("twitter") .setSearchType(SearchType.DFS_QUERY_THEN_FETCH) .setScroll(new TimeValue(60000)) .setQuery(queryBuilder) .setSize(100).execute().actionGet(); printlnResouce(response); } /** *------------------------------- bulk 批量执行-------------------------------- */ /** * 批量插入 * @param list * @throws IOException */ public void insertBulk(List<IndexRequest> list) throws IOException { BulkRequestBuilder bulk=client.prepareBulk(); for (int i = 0; i <list.size(); i++) { bulk.add(list.get(i)); } BulkResponse bulkResponse=bulk.get(); System.out.println(bulkResponse.hasFailures()); } /** * Bulk 处理器 * @param list * @throws IOException */ public void insertBulkByBulk(List<IndexRequest> list) throws IOException { for (int i = 0; i <list.size(); i++) { this.bulkProcessor.add(list.get(i)); } } /** * 遍历方法 */ private void printlnResouce(SearchResponse response){ System.out.println("total="+response.getHits().totalHits); Map<String,Object> map=new HashMap<String,Object>(); for(SearchHit searchHit:response.getHits()){ System.out.println(searchHit.toString()); map=searchHit.getSourceAsMap(); for (Map.Entry<String, Object> entry : map.entrySet()) { System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } } } }
Test
package per.wxp.elasticsearchDemo; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.junit4.SpringRunner; import per.wxp.elasticsearchDemo.Service.ElasticSearchService; import per.wxp.elasticsearchDemo.entity.IndexInfo; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.*; @RunWith(SpringRunner.class) @SpringBootTest public class ElasticsearchDemoApplicationTests { @Autowired private ElasticSearchService elasticSearchService; /* 基本类型操作 index type mapping document ---------------------------------------------------------------------------------------------------- */ @Test public void createIndex() { elasticSearchService.createIndex("book"); } @Test public void createTypeWithMapping() throws IOException{ elasticSearchService.createTypeWithMapping("book","English"); } @Test public void deleteIndex() throws IOException { elasticSearchService.deleteIndex("book"); } /* ------------------------insert Document----------------------- */ /** * 单个添加 * @throws IOException */ @Test public void insertDocument() throws IOException { XContentBuilder source = XContentFactory.jsonBuilder() .startObject() .field("author", "Nick Pentreath") .field("date", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())) .field("title", "spark机器学习") .field("content", "Mechine Learning with spark") .field("view", "Mechine Learning with spark") .field("tag", "Mechine Learning with spark") .endObject(); elasticSearchService.insertDocument("book","English","51",source); } /** * 批量添加 document * @throws IOException */ @Test public void insertBulk() throws IOException { elasticSearchService.insertBulkByBulk(GenerateSource()); } /** * 通过 BulkProcessor 批量添加 document * @throws IOException */ @Test public void insertBulkByBulk() throws IOException { elasticSearchService.insertBulkByBulk(GenerateSource()); } /* --------------------------------del Document 删除文档--------------------------------------------- */ @Test public void deleteById( ) { IndexInfo info=new IndexInfo(); info.setId("14"); info.setIndexName("book"); info.setTypeName("English"); elasticSearchService.deleteById(info); } /* --------------------------------view Document 查看文档--------------------------------------------- */ @Test public void getDocumentById( ) { IndexInfo info=new IndexInfo(); info.setId("2"); info.setIndexName("book"); info.setTypeName("English"); Map<String, Object> map= elasticSearchService.getDocumentById(info); if(map!=null){ for (Map.Entry<String, Object> entry : map.entrySet()) { System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue()); } }else{ System.out.println("查询结果为null"); } } /** * term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇 */ @Test public void termQueryTest(){ QueryBuilder queryBuilder1 = QueryBuilders.termQuery("title","spark机器学习-修改内容"); elasticSearchService.QueryBuilderFuction("book","English",queryBuilder1); } /** * 使用match,elasticsearch会根据你给定的字段提供合适的分析器, 分词以后按分词结果去查 */ public void matchQueryTest(){ QueryBuilder queryBuilder1 = QueryBuilders.matchQuery("title","学习"); elasticSearchService.QueryBuilderFuction("book","English",queryBuilder1); } /** * 组合条件查询 * filter 过滤查询 * must * mustNot * should */ public void boolQueryTest(){ QueryBuilder queryBuilder1 = QueryBuilders.boolQuery() .must(QueryBuilders.termQuery("author", "eeee")) .must(QueryBuilders.termQuery("title", "JAVA思想")) .mustNot(QueryBuilders.termQuery("content", "C++")) //添加不得出现在匹配文档中的查询。 .should(QueryBuilders.termQuery("id", "1"))//添加应该与返回的文档匹配的子句。 对于具有no的布尔查询,子句必须一个或多个SHOULD子句且必须与文档匹配,用于布尔值查询匹配。 不允许null值。 .filter(QueryBuilders.termQuery("view", "Update-Mechine"));//添加一个查询,必须出现在匹配的文档中,但会不贡献得分。 不允许null值。 elasticSearchService.QueryBuilderFuction("book","English",queryBuilder1); } /* --------------------------------update --------------------------------------------- */ @Test public void updateDocumentById() throws IOException { XContentBuilder source = XContentFactory.jsonBuilder() .startObject() .field("author", "Nick Pentreath") .field("date", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())) .field("title", "spark机器学习-修改内容") .field("content", "Update-Mechine Learning with spark") .field("view", "Update-Mechine Learning with spark") .field("tag", "Update-Mechine Learning with spark") .endObject(); elasticSearchService.updateDocumentById("book","English","1",source); } /* --------------------------------辅助方法--------------------------------------------- */ private List<IndexRequest> GenerateSource() throws IOException { XContentBuilder source =null; IndexRequest indexRequest =null; String[] strings={"学习"+"spark学习","spark机器学习","spark数据分析"}; List<IndexRequest> list=new ArrayList<IndexRequest>(); Random random=new Random(); for (int i = 55; i < 150; i++) { source = XContentFactory.jsonBuilder() .startObject() .field("author", "Nick Pentreath"+String.valueOf(i)) .field("date", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())) .field("title", strings[random.nextInt(3)]+String.valueOf(i)) .field("content", "Mechine Learning with spark"+String.valueOf(i)) .field("view", "Mechine Learning with spark"+String.valueOf(i)) .field("tag", "Mechine Learning with spark"+String.valueOf(i)) .endObject(); indexRequest=new IndexRequest("book", "English", String.valueOf(i)) .source(source); list.add(indexRequest); } return list; } }
在项目中,对于实时性要求很高的数据,添加或更新数据时可采用BulkProcessor批处理。
其中,es还提供了很多其他的查询方式,比如嵌套,统计,加权因子等















 3342
3342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









