






1.HashMap概述:
HashMap是基于哈希表的Map接口的非同步实现,此实现提供所有可选的映射操作,并允许进行null键和null值存储。
2.HashMap的数据结构:
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。如下图:
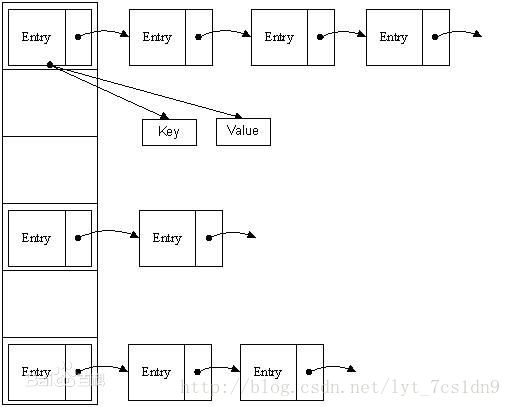
从上图可以看出,HashMap底层就是一个数组结构,数组中的每一项又是一个链表。Entry就是数组中的元素,每个Map.Entry其实就是一个key-value对,它持有一个指向下一个元素的引用,当新建一个HashMap的时候,就会初始化一个数组。
3.存储
查阅源码:
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
从源代码分析:我们往HashMap中put元素的时候,先根据key的hashCode通过hash算法重新计
算hash值(int hash = hash(key.hashCode());),再通过和数组(int i = indexFor(hash,
table.length))计算获取这个元素在数组中的位置(即下标),如果数组在该位置已经存放
有其他元素了,那么在这个位置的元素将以链表的形式存放(新加入的放在链头,最先加入的
放在链尾)( addEntry(hash, key, value, i);),如果数组该位置上没有元素,就直接将
该元素放在此数组中的该位置。
4.详述hash()
此算法加入了高位计算,防止低位不变,高位变化时,造成的hash冲突。
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}5.详述indexFor(int h, int length)
static int indexFor(int h, int length) {
return h & (length-1);
}这个方法非常巧妙,它通过 h & (table.length -1) 来得到该对象的保存位,而HashMap底层数组的长度总是 2 的 n 次方,这是HashMap在速度上的优化。
6.为什么是2的n次方
假设数组长度分别为15和16,优化后的hash码分别为8和9,那么&运算后的结果如下:
h & (table.length-1) hash table.length-1 结果
8 & (15-1): 0100 1110 0100
9 & (15-1): 0101 1110 0100
8 & (16-1): 0100 1111 0100
9 & (16-1): 0101 1111 0101从上面的例子中可以看出:当它们和15-1(1110)“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到数组中的同一个位置上形成链表,那么查询的时候就需要遍历这个链 表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hash值会与15-1(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大。
7.简述存储和读取:
HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,
也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
8.HashMap的resize(rehash)
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过160.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold = length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
由此可知:如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
JDK1.8做的修改:
从结构实现来讲,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现。
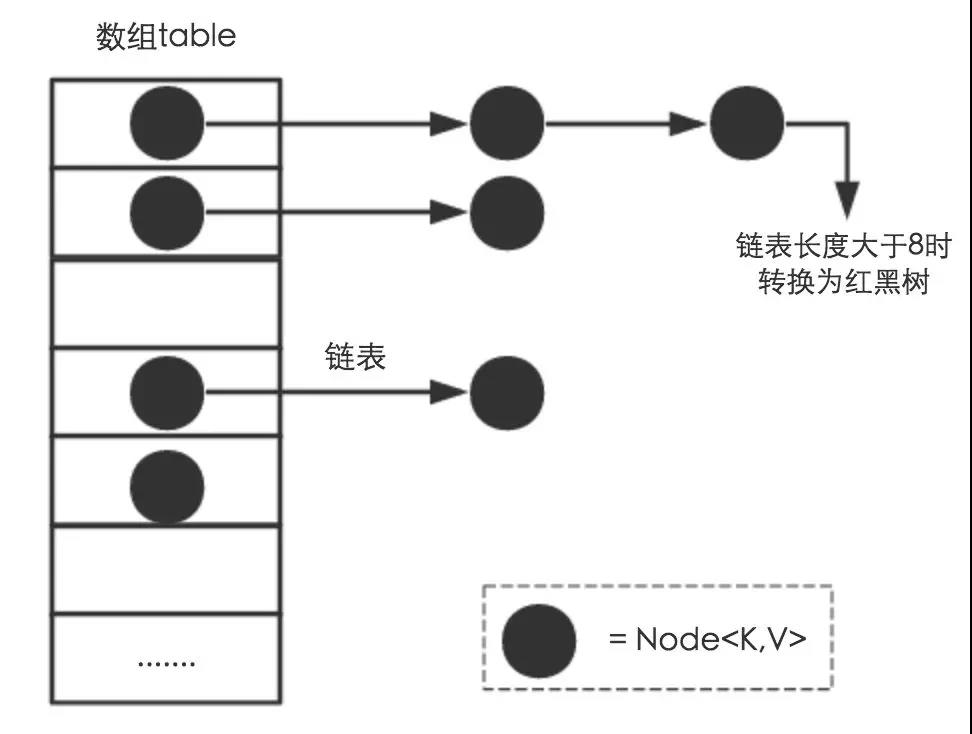
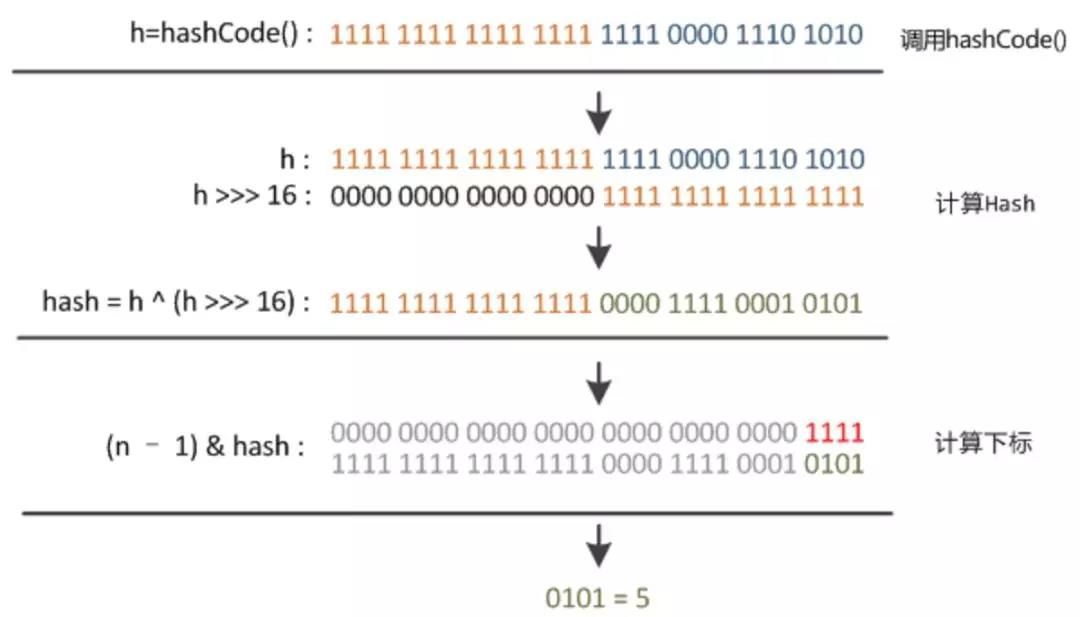
在JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
小结:
(1) 扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
(2) HashMap是线程不安全的,不要在并发的环境中同时操作HashMap,建议使用ConcurrentHashMap。
有能力的话可以看一下处理HashMap的线程安全知识。















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









