






ADDM(Automatic Database Diagnostic Monitor)-自动诊断监视工具
ASH(Active Session History)-活动会话历史-mmnl
AWR(Automatic Workload Repository)-自动负载信息库-mmon
STA(SQL Tuning Advisor)-SQL优化建议工具
AMM(Automatic Memory Management)-自动内存管理-mman
ASM(Automatic Storage Management)-自动存储管理
ASSM(Automatic Segment Space Management)-自动段空间管理
MSSM(Manualy Segment Space Management)-手动段空间管理
FSFO(Fast-Start Failover)-快速故障转换
ORACLE认证:oca-ocp-ocm初级认证-专家认证-大师认证
Oracle使用C语言写的
Oracle 对于数据的访问 也尽量都在内存中完成,而不是直接修改硬盘上的数据,内存内容在合适的时候再同步到磁盘,Oracle利用内存来克服磁盘 IO的束缚,在内存中进行活动越多,系统性能越好,反之,在磁盘上进行的操作越多,系统性能越差
Oracle数据库服务器中可以安装多个数据库,一个数据库需要占用非常大的内存空间,因此一般一个服务器只安装一个数据库。每一个数据库可以有很多用户,不同的用户拥有自己的数据库对象(比如:数据库表),一个用户如果访问其他用户的数据库对象,必须由对方用户授予一定的权限。不同的用户创建的表,只能被当前用户访问。因此在Oracle开发中,不同的应用程序只需使用不同的用户访问即可
OracleOraDb10g_home1iSQL*Plus,该服务提供了用浏览器对数据库中数据操作的方式。该服务启动后,就可以使用浏览器进行远程登录并进行数据库操作
http://10.211.55.5:5560/isqlplus/
OracleDBConsole+服务名,Oracle10g中的一个新服务。在Oracle9i之前,Oracle官方提供了一个基于图形界面的企业管理器(EM),从Oracle10g开始,Oracle提供了一个基于B/S的企业管理器 https://10.211.55.5:5500/em/
启动或停止服务:emctl start dbconsole
查看em状态:emctl status dbconsole
Oracle在SQL*Plus中的命令以分号(;)结尾,代表命令完毕并执行,系统同时会把该命令保存在缓存中,缓存中只保存最近执行过的命令,如果重新执行缓存中的命令,直接使用左斜杠符号(/)。如果命令不以分号结尾,该命令只是写入缓存保存起来,但并不执行
oracle每有一个事务,首先会产生一条日志,日志里面包含了能够还原这个事务的最少信息,这些日志会暂存在内存中,再由一个叫LGWR的进程将日志缓冲区的日志写到硬盘上的日志文件上,这些日志文件一般在50兆左右,一般为3组。等一个日志文件写满了50兆的内容,它会断开,LGWR继续往下一个日志文件中写日志;这3个日志文件轮流写入(覆盖写入)
重做日志文件归档就是将一个写满了日志的文件复制一份到一个指定的文件夹中,可以将这些历史日志文件都copy(归档)一份,而不会在轮循中被覆盖,起到保护数据的功能
SYSMAN是Oracle数据库中用于EM管理的用户
DBSNMP是Oracle数据库中用于智能代理(Intelligent Agent)的用户,用来监控和管理数据库相关性能,如果停止该用户,则无法提取相关的数据信息
Oracle SQL语句由如下命令组成:
数据定义语言(DDL),包括CREATE、ALTER、DROP等
数据操纵语言(DML),包括INSERT、UPDATE、DELETE、SELECT … FOR UPDATE等
数据查询语言(DQL),包括基本查询语句、Order By子句、Group By子句等
事务控制语言(TCL),包括COMMIT、SAVEPOINT、ROLLBACK
数据控制语言(DCL),GRANT、REVOKE
只要配置了ORACLE_SID环境变量,sqlplus在空实例下就能启动成功
AL32UTF8字符集中一个中文字符占3个字节,字符集ZHS16GBK一个中文字符占2个字节
NLS_CHARACTERSET是数据库字符集,NLS_NCHAR_CHARACTERSET是国家字符集
ORACLE中有两大类字符型数据,VARCHAR2是按照数据库字符集来存储数据。而NVARCHAR2是按照国家字符集存储数据的。同样,CHAR和NCHAR也一样,一是数据库字符符,一是国家字符集
字符集不同,二进制码的组合就不同
改变sql执行计划:
1、sql改变执行执行计划的方式之一:对表执行ddl操作,一旦执行了ddl,库缓存中所有sql文本中包含了该表的shared cursor都会被标记为invalid,shared cursor存储的解析树和执行计划都不能被重用
2、DBMS_SHARED_POOL.PURGE删除shared cursor
select返回记录的顺序(没有order by)
1、如果走的是全表扫描,则按rowid从小到大排序返回记录,因为此时按rowid返回的速度最快
2、如果走的是索引扫描,则按dbms_rowid.rowid_block_number(ROWID),rowid从小到大返回记录,索引扫描在oracle内部表现为索引叶节点的扫描,索引叶节点通常已经排序并且叶节点之间存在指针,便于扫描,由于此时select按索引扫描表,因此返回的记录就按“索引序”排列
db_block_size=8k时,单个数据文件最大为32G,由于Oracle的Rowid中使用22位来代表Block号,这22位最多只能代表2^22-1(4194303)个数据块,所以最大为(2^22-1)*8k,smallfile tablespace最多有1,023个datafiles
为了扩展数据文件的大小,Oracle10g中引入了大文件表空间,在大文件表空间下,Oracle使用32位来代表Block号,也就是说,大文件表空间下每个文件最多可以容纳4G个Block,那么也就是说当Block_size为8k时,数据文件可以达到32T,容量是smallfile tablespace的1024倍
相对文件编码(relative_fno)和绝对文件编号(file_id):相对文件id是指相对于表空间,在表空间唯一,绝对文件是指相当于全局数据库而言的,全局唯一,Relative_fno是一个循环周期,以1024为一个循环,当file_id依次递增到1024整数倍之后,file_id会继续增加,而relative_fno会形成一个内部循环
一个连接可能产生多个sessions,一个sessions可能产生多个processes,同样,一个processes可能对应多个sessions;Oracle的sessions和processes的数量关系大概是:sessions=1.1 * processes + 5
查看当前session的id
select * from v$mystat;
select userenv('sid') from dual;
V$SESSION和V$PROCESS的关系
1、每次打开一个新链接,则V$SESSION和V$PROCESS都各自增加一条记录,OS process也增加一条
2、V$PROCESS和OS process基本是一一对应的关系,通过SPID交互
Oracle11g的amm内存管理模式就是使用/dev/shm,所以有时候修改MEMORY_TARGET或者MEMORY_MAX_TARGET会出现ORA-00845的错误
DBID:DBID是DataBase IDentifier的缩写,意思是数据库的唯一标识符,DBID在数据文件头和控制文件都是存在的,可以用于标示数据文件的归属
对于不同数据库来说,DBID应当不同,而db_name则可能是相同的,但是DBID是可变的,在进行数据库Clone等操作时,DBID可以被重置
RMAN恢复时,若没有使用恢复目录(catalog),知道被恢复的数据库的DBID可以简化操作,例如要恢复一个已经丢失了控制文件的数据库的控制文件
在执行DDL语句之前,如果执行了DML语句,也会被一并提交,并且不可回滚
Oracle每次请求数据时,都是以块为单位,即Oracle每次请求的数据是块的整数倍,如果Oracle请求的数据量不到一块,Oracle也会读取整个块,所以块是Oracle读写数据的最小单位或者最基本的单位
索引的创建大体上分为两个阶段:第一,全表扫描过程 第二,排序创建索引过程
##查看账户被锁的ip
cat /u01/app/oracle/diag/tnslsnr/func/listener/trace/listener.log
数据字典和性能视图
1、数据字典包括数据字典基表和数据字典视图,数据字典的信息是从数据文件中取得,因为数据字典基表不能直接访问,所以要建立数据字典视图来访问基表
2、数据字典视图有三种,DBA_,ALL_,USER_,数据字典是静态视图,数据存放在表文件中,关闭数据库实例后,数据不会被清空,数据库open状态下才可以查询
3、v$开头的是动态性能视图,数据从SGA内存或controlfile中读取,是Oracle实例启动时创建的,动态变化,一旦实例被关闭,里面的数据就会被清空,重启实例后重新设置,数据库nomount状态下可以查询与SGA相关的信息,mount时可以查询与controlfile相关的信息,v$其实是v_$的同义词
4、gv$开头的性能视图一般是rac查询中用的,rc开头的recovery catalog,rman恢复目录中使用的
查看ora错误的详细信息
!oerr ora 1093
oracle可以通过SID和service_name对外提供服务,oracle默认创建的是动态监听,tns配置中使用SID和SERVICE_NAME(listener.ora中的GLOBAL_DBNAME)都可以连接,lsnrctl status显示下的Service就是Sevice_name,封装了ORACLE SID和ORACLE INSTANCE,是对外提供服务的接口
只要有init就能启动到nomount,有controlfile就能启动到mount,不验证controlfile文件里面的内容,open时通过controfile的内容验证datafile
*****************************************************************************************************************
oracle实用工具
dbca:database configure assistan--创建数据库
netca:net configure assistant--网络服务配置,配置监听(服务端),创建网络服务名(客户端)
netmgr:配置你创建的监听服务
netca主要用来配置监听和配置NET服务名,以便远程连接数据库。netmgr主要是配置创建的监听服务,因为创建完监听,还要为监听配置,监听创建的数据库实例
*****************************************************************************************************************
导入工具:spool,utl_file,sqlldr
*****************************************************************************************************************
在Oracle中default是一个值,而SQL Server中default是一个约束,因此Oracle的default设置可以在建表的时候创建
在Oracle代码中,“/”执行缓存区中的语句,由于缓冲区中只存储一条刚刚保存过语句,由于每条语句没有用分号结尾,只是保存在缓冲区,因此每条语句后面都有单独一行“/”
insert在遇到存在默认值的列时,可以使用default值代替
Distinct关键字,它的作用是取消重复的记录, 要实现这个目的,数据库必须要先对记录进行排序,然后才能够去除重复的记录内容,会引起数据库的隐形排序
拼SQL时,chr(13)表示回车(另起一行),chr(10)表示换行
windows中换行由2个字符组成-回车+换行(chr(13)+chr(10)),linux只需chr(10)
换行符:windows-\r\n,linux-\n
TRUNCATE和DELETE都能把表中的数据全部删除,区别是:
1. TRUNCATE是DDL命令,删除的数据不能恢复;DELETE命令是DML命令,删除后的数据可以通过日志文件恢复
2. 如果一个表中数据记录很多,TRUNCATE相对DELETE速度快
BWTWEEN操作所指定的范围也包括边界
v$开头的是系统视图,V$是基于V_$视图建立的公共同义词,v_$视图是基于v$视图来建立的,而v$视图则是基于X$表建立的
escape用法:'%30\%%' escape '\' :包含“30%”的字符串,“\”指转义字符,“\%”在字符串中表示一个字符“%”
INTERSECT(交集),返回两个查询共有的记录
MINUS(补集),返回第一个查询检索出的记录减去第二个查询检索出的记录之后剩余的记录
(+):Oracle专用的联接符,在条件中出现在左边指右外联接,出现在右边指左外联接
动态性能视图用于记录当前例程的活动信息,v$开头
常用的角色:connect,resource,dba
只给sp查看的权限:grant debug on scott.msp_syncemp to test;
any和all的例子:
SELECT ENAME,JOB,SAL FROM EMP WHERE SAL<ANY (SELECT SAL FROM EMP WHERE JOB='SALESMAN')
SELECT ENAME,JOB,SAL FROM EMP WHERE SAL<all(SELECT SAL FROM EMP WHERE JOB='SALESMAN')
<any:比子查询结果中任意的值都小,也就是比子查询结果中最大值还小,>any表示比子查询结果中最小的还大
>ALL:比子查询结果中所有值还要大,也就是比子查询结果中最大值还要大,<ALL表示比最小值还要小
伪列:
Oracle的表使用过程中,实际表中还有一些附加的列,称为伪列。伪列就像表中的列一样,但是在表中并不存储。伪列只能查询,不能进行增删改操作,两个伪列:ROWID和ROWNUM
ROWNUM与ROWID不同,ROWID是插入记录时生成,ROWNUM是查询数据时生成。ROWID标识的是行的物理地址。ROWNUM标识的是查询结果中的行的次序
ROWID
表中的每一行在数据文件中都有一个物理地址,ROWID伪列返回的就是该行的物理地址。使用ROWID可以快速的定位表中的某一行。ROWID值可以唯一的标识表中的一行。由于ROWID返回的是该行的物理地址,因此使用ROWID可以显示行是如何存储的
eg:
select rowid,dname from scott.emp where rowid='AAAMgxAAEAAAAAQAAA'
ROWNUM
ROWNUM为结果集中每一行标识一个行号,第一行返回1,第二行返回2,以此类推。通过ROWNUM伪列可以限制查询结果集中返回的行数
eg:
select rownum,t.* from scott.emp t where rownum=3
--如果查询条件中ROWNUM大于某一正整数,则不返还任何结果
select rowNUM,t.* from scott.dept t
WHERE ROWNUM>2
--只返回1条
select rowNUM,t.* from scott.dept t
WHERE ROWNUM>=1 and rownum<2
创建基于已存在列的列
DTDATE as (TRUNC(created_time))
清除列的默认值
ALTER TABLE MB.TB_OPERATOR MODIFY PASSWORD_ERROR_COUNT DEFAULT NULL;
timestamp转换为date
SELECT create_time,create_time+0 FROM fnc.tb_trade
oracle的一些简单查询-数据字典
--查询所有系统权限
select * from system_privilege_map;
--查询所有角色
select * from dba_roles
select * from session_privs;
--查询角色包含的系统权限
select * from dba_sys_privs where grantee='DBA'
select * from role_sys_privs where role='DBA' --结果集同上,需以sysdba登录
--查询角色包含的对象权限
select * from dba_tab_privs
--查询帐号具有的角色权限
select * from dba_role_privs where grantee='SCOTT'
--索引有关
select * from dba_indexes
select * from user_indexes
select * from dba_ind_columns
select * from user_ind_columns
--存储过程和函数的查看
SELECT * FROM USER_SOURCE
WHERE NAME='GET_EMP_NAME'
--对象状态查看
SELECT * FROM USER_objects
--查看对象间的依赖性
SELECT * FROM USER_DEPENDENCIES
oracle创建表时创建约束:
create table customer(
emailid unique,
sex default 'man' check(sex in('man','woman')),
id char(1) reference t(id),
customerid primary key
)
oracle分页的三种方式
1、rownum
2、rowid
3、分析函数row_number
查看sid(server_name)
1、linux或者unix下执行
echo $ORACLE_SID
2、 select instance_name from v$instance;
oracle更新新特性:可以组更新
update SCOTT.emp set (job,mgr,hiredate,sal)=(select job,mgr,hiredate,sal from SCOTT.emp where ename='SMITH')
where ename='ALLEN'
oracle函数:
create or replace function test2(userid number)
return varchar2
as /is
v_name varchar2(20);
begin
select username into v_name
from userinfo where user_id=userid;
return v_name;
end;
事务操作:
事务是保持数据一致性
设置保存点 savepoint t1
撤回到保存点 rollback to t1
撤销全部事务 rollback
只读事务:
只允许select操作,读取不到别的进程的dml操作
set transaction read only
修改表:
--修改表名
rename emp to emp1
rename tablebak.td_mb_info1 to td_mb_info //to后的新表明不能加schema,否则报错
--修改字段名
alter table emp1 rename column empno to empno_new
--添加一个字段
alter table student add (classid number(2));
--修改一个字段的长度
alter table student modify (xm varchar2(30));
alter table scott.youtest modify id not null
--修改字段的类型或名字
alter table student modify (xm char(30));
--删除一个字段
alter table student drop column sal;
--批量删除一个表的字段
alter table p2p.tb_invest_stage drop (CITY_WL,LOGIN_ACCOUNT_WL,MEMBER_TERMINAL_WL,ORIGIN_AMOUNT,STEP_AMOUNT,INVEST_UPPER_LIMIT);
根据结果集创建表
create table temp_emp as
select * from scott.emp where 1=2 --只复制表结构
--修改日期的默认格式(临时修改,数据库重启后仍为默认;如要修改需要修改注册表)
alter session set nls_date_format ='yyyy-mm-dd';
##### 定义变量,赋值变量
declare
v_name varchar2(50);
v_job varchar2(50);
v_sal varchar2(50);
begin
select t.ename, t.job, t.sal
into v_name, v_job, v_sal
from scott.emp t
where t.empno=7369;
dbms_output.put_line(v_name || ',' || v_job || ',' || v_sal);
end;
##### 自定义记录类型
declare
type order_info is record(
v_name varchar2(50),
v_job varchar2(50),
v_sal varchar2(50));
v_tmp_record order_info;
begin
select t.ename, t.job, t.sal
into v_tmp_record
from scott.emp t
where t.empno=7369;
dbms_output.put_line(v_tmp_record.v_name || '-' || v_tmp_record.v_job || '-' || v_tmp_record.v_sal);
end;
##### user返回当前登录的用户
select vsize(user),user from dual;
Merge into语法:
MERGE INTO [your table-name] [rename your table here]
USING ( [write your query here] )[rename your query-sql and using just like a table]
ON ([conditional expression here] AND [...]...)
WHEN MATHED THEN [here you can execute some update sql or something else ]
WHEN NOT MATHED THEN [execute something else here ! ]
merge into products p using (select * from newproducts) np on (p.product_id = np.product_id) --on后面的条件要加括号
when matched then
update set p.product_name = np.product_name where np.product_name like 'OL%'
when not matched then
insert values(np.product_id, np.product_name, np.category) where np.product_name like 'OL%'
枚举一年中的周数及包含的具体范围:
SELECT LEVEL 周次,
(Trunc(SYSDATE,'yyyy')-To_Char(Trunc(SYSDATE,'yyyy'),'d')+2)+(LEVEL-1)*7 当周第一天,
(Trunc(SYSDATE,'yyyy')+(8-To_Char(Trunc(SYSDATE,'yyyy'),'d')))+(LEVEL-1)*7 当周最后一天
FROM dual
CONNECT BY LEVEL<=53
update的用法
update scott.emp t
set depname=(select dname from scott.dept t1 where t.deptno=t1.deptno )
where exists(select * from scott.dept t1 where t.deptno=t1.deptno )
表示对于t中所有行满足t.deptno=t1.deptno的进行更新,不满足条件的也更新,不过找不到对应的值,只能赋空值,如果t.deptno不允许为空会报插入空值错误
只有加上where exists(select * from scott.dept t1 where t.deptno=t1.deptno )条件,才能将t.deptno=t1.deptno的那些在t中的数据保存
sqlserver中只更新匹配的行数,不匹配的行数不更新
oracle中update没有from子句,也不能使用表连接关键字
另类用法:
update (
SELECT t.DEPNAME,t1.Dname ,empno
FROM SCOTT.EMP t,SCOTT.DEPT t1 WHERE t.DEPTNO=t1.DEPTNO
)
SET DEPNAME=DNAME
Note:
可以当作跟新视图
能避免对B表或其索引的2次扫描,但前提是 A(customer_id) b(customer_id)必需是unique index或primary key
隐式游标常用四个属性:
sql%rowcount:是oracle的内部游标,返回是之前的sql语句影响的数据行数,自定义游标用法:cursor%rowcount
sql%found:sql被执行成功后受影响的行数是否大于等于1,通常适用insert、update、delete、select into
sql%notfound:sql被执行成功后受影响的行数为0
sql%isopen:游标是否处于open状态,隐式游标永远为false
未提交的数据存在哪
未提交之前,旧值是放在UNDO,新值是在db buffer cache中
提交后写入REDO,但是并不会同步到datafile,只有checkpoint后才写入datafile
比方说做一条update语句,oracle会把这条语句读入到dbbuffer(其实是先查询dbbuffer里面是否存在,接着做一系列的词法语法分析,生成执行计划等等很多事情),读入后开始更新数据,首先会加锁,为了保持commit之前的读一致性,会将block读入回滚段。用户修改,修改时oracle会将数据依次写入redolog,databuffer,scn此时分别由dbwr和lgwr记录(对回滚段的更改也会记录redolog),dbwr首先是触发lgwr,将更改的数据信息记录redolog。然后就将脏数据写入磁盘
查看会话的sid
select sid from v$mystat where rownum<2
##当前session登录用户
select user from dual;
NO_DATA_FOUND和%NOTFOUND的区别
1)SELECT . . . INTO 语句触发 NO_DATA_FOUND;
2)当一个显式光标的 where 子句未找到时触发 %NOTFOUND;
3)当UPDATE或DELETE 语句的where 子句未找到时触发 SQL%NOTFOUND;
4)在光标的提取(Fetch)循环中要用 %NOTFOUND 或%FOUND 来确定循环的退出条件,不要用NO_DATA_FOUND
查看系统全局名
select * from global_name
创建长度为4个字符的表
create table test_ly(a varchar2(4 char))
查询数据库名及其id
select * from v$database
查询数据库参数
show parameter db;
查询数据库的实例名
select instance_name from v$instance;
数据库域名
数据库安装结束后,如果要知道正在运行额数据库是否有域名以及数据库域名名称可以用
select value from v$parameter where name='db_domain' ;
show parameter domain;
数据库服务名
如果数据库有域名,则数据库服务名就是全局数据库名,如果该数据库没有定义域名,则数据库服务名与数据库名相同
show parameter service_name
查看字符集相关参数
select * from v$nls_parameters;
ORALCE解析对象的顺序
会按如下的顺序进行验证,首先是看看当前用户是否拥有这个对象;其次这个对象名是否是当前用户拥有的一个同义词;最后,判断公用同义词的情况。所以,在实际应用中,要尽量利用方案同义词,少用公用同义词
sqlerrm和sqlcode函数
sqlcode返回pl/sql执行内部异常代码
sqlerrm返回指定错误代码的错误信息 语法:SQLERRM [(error_number)]
Note:
sqlcode和sqlerrm是不能直接在sql语句中使用,必须先将其赋给变量后,才能在sql语句中使用
eg:
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE(SQLCODE||'---'||SQLERRM);
NULL和''的关系
对char和varchar2字段来说,''就是null;但对于where 条件后的'' 不是null,对于缺省值,也是一样
null和''长度都是空
ALTER SYSTEM中参数SCOPE
Oracle有个叫做spfile的文件,就是动态参数文件,里面设置了Oracle 的各种参数,所谓的动态,就是可以在不关闭数据库的情况下,更改数据库参数,记录在spfile里面
更改参数的时候,有4种scope选项,scope就是范围
*scope=spfile 仅更改spfile里面的记载,不更改内存,也就是不立即生效,而是等下次数据库启动生效,有一些参数只允许用这种方法更改(动态参数和静态参数都可以,是静态参数唯一可以使用的方式)
*scope=memory 仅仅更改内存,不改spfile,也就是下次启动就失效了,只适用于动态参数,静态参数则不允许
*scope=both 内存和spfile都更改
*不指定scope参数,等同于scope=both,只适用于动态参数
instance和database
ORACLE实例 = 后台进程 + 进程所使用的内存(SGA)
数据库是永久的,是一个文件的集合,数据库 = 重做文件 + 控制文件 + 数据文件 + 临时文件
ORACLE实例和数据库之间的关系
实例可以在没有数据文件的情况下单独启动 startup nomount , 通常没什么意义
一个实例在其生存期内只能装载(alter database mount)和打开(alter database open)一个数据库
一个数据库可被许多实例同时装载和打开(即RAC)
1、db_name对应一个数据库(oracle database)的唯一表示,对于单个数据库这样是足够的,但是随着多个数据库构成的分布式数据库的普及,这种命名方法给数据库的管理造成一定的负担,因为各个数据库的名字可能一样,造成管理上的混乱,为了解决这种情况,引入了Db_domain参数,这样在数据库的标识是由Db_name和Db_domain两个参数共同决定的,避免了因为数据库重名而造成管理上的混乱
2、db_domain 定义一个数据库所在的域,该域的命名同互联网的“域”没有任何关系,只是数据库管理员为了更好的管理分布式数据库而设计的
3、GLOBAL_DBNAME对一个数据库的唯一标识,oracle建议用此种方法命令数据库。该值是在创建数据库是决定的,缺省值为Db_name. Db_domain。在以后对参数文件中Db_name与Db_domain参数的任何修改不影响Global_name的值,如果要修改Global_name,只能用ALTER DATABASE RENAME GLOBAL_NAME TO <db_name.db_domain>命令进行修改,然后修改相应参数
4、Instance_name数据库实例名,用于和操作系统之间的联系,用于对外部连接时使用,在操作系统中要取得与数据库之间的交互,必须使用数据库实例名。例如,要和某一个数据库server连接,就必须知道其数据库实例名,只知道数据库名是没有用的,与数据库名不同,在数据安装或创建数据库之后, db_name与instance_name的联系:数据库名和实例名是一对一的关系,但如果在oracle并行服务器架构(即oracle实时应用集群)中,数据库名和实例名是一对多的关系(一个数据库对应多个实例,同一时间内用户只一个实例相联系,当某一实例出现故障,其它实例自动服务,以保证数据库安全运行)
instance_name参数是ORACLE数据库的参数,此参数可以在参数文件中查询到,而ORACLE_SID参数则是操作系统环境变量,用于和操作系统的交互,在数据库安装好后,oracle_sid被用于定义数据库参数文件的名称
5、service_name
该参数是oracle8i新引进的,在8i以前,用SID来表示标识数据库的一个实例,但是在Oracle的并行环境中,一个数据库对应多个实例,这样就需要多个网络服务名,设置繁琐。为了方便并行环境中的设置,引进了Service_name参数,该参数对应一个数据库,而不是一个实例,而且该参数有许多其它的好处。该参数的缺省值为Db_name. Db_domain,即等于Global_name,一个数据库可以对应多个Service_name,以便实现更灵活的配置。该参数与SID没有直接关系,即不必Service name 必须与SID一样
∆存储过程中Authid Current_User的作用
Authid Current_User是调用者权限
oracle有2种执行的权限:定义者权限和调用者权限,默认都是定义者权限,声明Authid Current_User后就是调用者权限
定义者权限的现象是,如果在APPS下创建的procedure,其他user只要有EXECUTE权限,都是以apps的名义来执行,因为APPS是procedure的定义者,APPS能做什么,那这个procedure就能做什么
调用者权限的现象是,如果在APPS下创建的procedure,其他user有权限执行这个procedure,这个procedure所做的内容都是以当前user的名义来做的(以执行过程的用户的权限来处理涉及的对象权限),如果某个table,只有APPS才有权限修改,那这个procedure在apps下面才执行成功,其他user下是不成功的
--给表增加注释
COMMENT ON TABLE "DM"."DEPT" IS '部门表;
--给列增加注释
COMMENT ON COLUMN "DM"."DEPT"."DEPTNO" IS '部门编号;
dump出来的文件在user_dump_dest参数设定的目录内,以_ora_.trc为格式的名字。其中spid指当前sid所对应的操作系统的进程号,可以通过以下语句获得
select p.spid from v$session s,v$process p where s.paddr=p.addr and s.sid in (select userenv( 'sid') from dual);
生成两个日期间的所有日期
Select Rownum, to_date('2015-01-01','yyyy-mm-dd')+Rownum-1
from dual
connect by
rownum< to_date('2015-02-01','yyyy-mm-dd' )-to_date('2015-01-01', 'yyyy-mm-dd') +2;
SELECT ROWNUM FROM dual CONNECT BY ROWNUM< 3;
1.涉及到数据库文件(包括什么datafile、redolog等等)的时候用alter database
2.涉及到数据库参数调整(其实就是和具体的文件没什么关系)的时候用alter system
查看alert日志
cd /u01/app/oracle/diag/rdbms/dw/dw/trace
ls -alcr | grep alert (c时间排序、r倒序)
数据库是什么?数据库是一个逻辑上的概念,简单的说就是相互关联的一会数据。而对应到实际的物理概念上,就是磁盘上的一个或者一堆文件,里边包含着数据。但是光有数据不行,数据库有很多功能,比如可以接受用户连接,给用户提供数据,这样就需要有“程序”。所以说关闭状态的数据库,就是磁盘上的程序文件,加上数据文件。
想要使用数据库,就要把它打开,让上边说的“程序”运行起来。实例就是指计算机内存中处于运行状态的数据库程序,以及为这些程序分配的一些内存空间。实例是位于内存中的,只在数据库处于运行状态时才存在。实例负责实现给用户提供网络连接、读写数据文件等等各种功能。
不同的数据库产品有些不同,Oracle中一个实例只能连接一个逻辑上的“数据库”,甚至是不同机器上运行着的不同实例同时连接一个数据库(RAC)。SQL Server和My SQL中的“实例”则比较独立,可以随时打开或者关闭某一个数据库。
oracle在运行过程中,所有对数据的修改都是在内存中进行的,Oracle每要修改一个记录必须先把记录所在的数据块加载到内存中,然后在内存中进行修改,提交时修改的数据块不会立即写回磁盘,基于性能的考虑,采用“延迟写”的算法定期批量的将数据块写回磁盘,因此oracle运行时,内存的数据总比磁盘数据新,当数据库正常关闭时(shutdown immediate,shutdown normal,shutdown transactional),Oracle会把SGA的内容全部写回磁盘后才关闭DB,这时内存和磁盘的数据才完全同步,数据不会丢失,如果DB异常关闭(shutdown abort或者断电),内存数据来不及同步到磁盘,这时就产生了数据不一致,再次打开DB时,需要进行数据恢复
Oracle的Redo机制保证了DB恢复的可行性,修改数据块之前,代表本次修改操作的Redo记录先被保存下来(Write Ahead Logging),然后才真正修改数据,处理commit语句时,Oracle会在Log Buffer生成一条COMMIT记录,为了保证事物的持久化,所有Redo记录和这条commit都要被写到磁盘的联机日志文件,但是数据不必写回磁盘,如果联机日志空间不够,会触发日志切换,旧日志的检查点必须完成才能被覆盖,如果是归档模式,日志必须先完成归档才能被覆盖
日志中带有SCN,Oracle按照SCN对日志排序,就可得到历史操作,Oracle也是根据SCN来判断数据文件是否需要恢复
每个数据文件的文件头会记录启动SCN,控制文件会记录每个数据文件的终止SCN,这两个SCN用来确认数据文件是否需要恢复
--查看启动SCN
SELECT checkpoint_change# FROM v$datafile_header;
--查看终止scn
SELECT NAME,checkpoint_change#,last_change#
from v$datafile;
Note:
v$datafile_header中的checkpoint_change#为启动SCN,和v$datafile中的checkpoint_change#数值一样
DB正常运行时,每个数据文件的终止SCN被设置为无穷大(null),其他的SCN应该完全一样,除了新建的tablespace
如果DB正常关闭,关闭之前DB会执行一个检查点动作,每个数据文件的终止SCN被设置成启动SCN,如果DB异常关闭,终止SCN来不及设置启动SCN,仍然是null
DB再次启动时,会比较这些SCN是否一致,不一致要进行恢复
RAC、Data Guard、Stream是Oracle高可用体系中的三驾马车,每个工具既可以独立应用,也可以相互配合,这3个工具都能提供HA功能,但各自的侧重点不同,适用的场景也不尽相同
RAC能把多台计算机组织在一起,让多个实例同时对外服务是RAC的主要特点,强项在于解决单点故障和负载均衡,常用语24*7的核心系统,但数据只有一份,数据本身是没有冗余的
Data Guard是通过冗余数据来提供数据保护,Data Guard通过日志同步机制保证冗余数据和主数据之间的同步,同步可以是实时、延时,同步、异步多种形式,Data Guard常用于异地容灾,虽然可以在Standby上执行只读查询,分散Primary的性能压力,但Data Guard不是性能解决方案
Stram是以Oracle Advanced Quene为基础实现的数据同步,提供了多个级别的灵活配置,并且Oracle提供了丰富的API等开发支持,Stream更适合在应用层面的数据分享
删除数据库实例
数据库必须处于MOUNT状态,设置为RESTRICTED SESSION
执行DROP DATABASE命令后,Oracle自动删除控制文件,数据文件和在线重做日志文件,如果使用了SPFILE,SPFILE文件也会删除。不会删除归档文件和备份文件,audit文件,adump文件,trace文件
alter database close;
alter system enable restricted session;
drop database;
或
startup restrict mount;
startup mount exclusive restrict;
drop database;
手工删除实例相关的配置:
1、删除$ORACLE_BASE/admin/$ORACLE_SID所有目录
2、删除$ORACLE_HOME/dbs下和SID相关的文件和参数文件,包括hc_*.dat,init.ora,lk*,orapw*
3、删除/etc/oratab中和实例相关的部分
4、可以在$ORACLE_HOME中执行find . -name sid*,删除所有和实例相关的文件
Oracle 对于数据的访问 也尽量都在内存中完成,而不是直接修改硬盘上的数据
表空间自包含(self-contained)
自包含:一般自包含,完全自包含
一般自包含是指当前表空间集中的对象不依赖表空间集之外的对象,如果还同时满足表空间集之外的对象也不依赖于表空间中的对象,也就是各个表空间完全独立,叫做完全自包含
自包含的表空间,可以保证进行表空间迁移,如果表空间以外的依赖表空间内的对象在表空间迁移时会丢失
完全自包含,可以保证完全的进行表空间迁移而不丢失对象
反过来,如果表空间的对象依赖表空间以外的对象,那么就不满足自包含的条件
表空间依赖关系
*tbs1 — tbs2 表空间tbs1和tbs2互不依赖,两者完全独立,tbs1和tbs2都完全自包含
*tbs1 —> tbs2,表空间tbs1依赖tbs2,tbs1自包含,tbs2不是
*tbs1 <— tbs2,表空间tbs1不依赖tbs2,但tbs2依赖tbs1,tbs1不是,tbs2自包含
*tbs1 <—> tbs2,表空间tbs1和tbs2相互依赖,都不自包含
比如有一个table在表空间A里,其上的一个index在表空间B里。
那么对于表空间A,其中的对象不依赖表空间外的对象,所以是个自包含,但是表空间以外的index却依赖表空间内的对象,不是一个完全自包含。在迁移表空间可以完全表空间,但是index在表空间迁移会丢失,反过来,对于表空间B,表空间里的对象INDEX是依赖表空间A里的TABLE对象的,所以不满足自包含条件,表空间迁移也就会出现问题
##检查一般自包含
exec dbms_tts.transport_set_check('au',TRUE);
SELECT * FROM transport_set_violations;
##检查完全自包含
EXECUTE dbms_tts.transport_set_check('AU',TRUE, TRUE);
SELECT * FROM transport_set_violations;
.trc与.trm文件
.trc文件称为Sql Trace Collection file,它是系统的跟踪文件(trace),当系统启动时或运行过程中出现错误时,系统会自动记录跟踪文件到指定的目录,以便于检查,这些文件需定期维护删除
.trm file全称是trace map file,称为跟踪元数据文件,.trm文件中的元数据描述了存储在.trc文件中的跟踪记录,.trm文件是伴随着.trc文件产生,一个.trm对应一个.trc文件,.trm文件包含.trc文件的结构化信息
从11g开始,所有的跟踪文件都位于 ADR_HOME/trace目录下, 跟踪元数据允许一些工具,例如:ADRCI,去提交处理跟踪信息。
通过删除.trm文件,对于使用 ADRCI工具来提交处理跟踪信息,将使得.trc变得不可用
Oracle中Schema和User的关系是一一对应的,也就是说一个Schema只对应一个User,一个User对应一个Schema,Oracle中,schema是与拥有此schema的user同名的
不同的schema之间没有直接的关系,不同的schema之间的表可以同名,也可以互相引用(但必须有权限),在没有别的schema的操作权限下,每个用户只能操作它自己的schema下的所有的表,不同的schema下的同名的表,可以存入不同的数据(即schema用户自己的数据)
user即Oracle中的用户,和所有系统的中用户概念类似,用户所持有的是系统的权限及资源;而schema是对象的集合,它包含了表、视图、函数、包等
--改变当前session的schema:
ALTER SESSION SET CURRENT_SCHEMA = sys
之后就可以直接使用sys这个schema中的表,不用写成sys.table_name
--根据表名查询所有者:
select owner,table_name from all_tables where table_name = Upper('product')
select owner,table_name from all_tables where table_name = Upper('product_detail’)
Select …forupdate语句是经常使用手工加锁语句。通常情况下,select语句不会对数据加锁,妨碍影响其他的DML和DDL操作。同时,在多版本一致读机制的支持下,select语句也不会被其他类型语句所阻碍
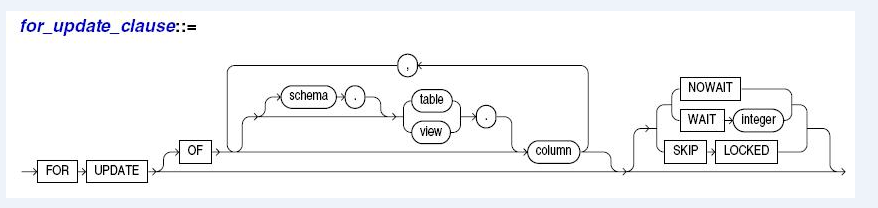
for update子句分为两个部分:加锁范围子句和加锁行为子句
1、加锁范围子句
在select for update之后,使用of子句选择对select的特定数据表进行加锁操作,不使用of子句默认表示在select所有的数据加锁
2、加锁行为子句
•Nowait子句
当进行for update的操作时,与普通select存在很大不同,一般select不需要考虑数据是否被锁定,最多根据多版本一致读的特性读取之前的版本,加入for update之后,Oracle就要求启动一个新事务,尝试对数据进行加锁,如果当前已经被加锁,默认的行为是block wait,使用nowait子句的作用就是避免进行等待,当发现请求加锁资源被锁定未释放的时候,直接报错返回
•wait n子句
是默认的for update行为,一旦发现对应资源被锁定,就等待blocking,直到资源被释放或者强制终止命令
没有n则是无限等待直接资源释放,n表示当出现blocking等待的时候最多等待多长时间,单位是秒级别
•Skip locked参数
在对数据行进行加锁操作时,如果发现数据行被锁定,就跳过处理,这样for update就只针对未加锁的数据行进行处理加锁
eg:
select * from TB_CUSTOMER for update of name;
select * from TB_CUSTOMER for update wait 5;
select * from TB_CUSTOMER for update skip locked;
Database Object Naming Rules
http://docs.oracle.com/cd/E11882_01/server.112/e41084/sql_elements008.htm#SQLRF51129
1.Every database object has a name. In a SQL statement, you represent(描绘) the name of an object with a quoted identifier or a nonquoted identifier.
•A quoted identifier begins and ends with double quotation marks ("). If you name a schema object using a quoted identifier, then you must use the double quotation marks whenever you refer to that object.创建表等对象时,如果加双引号,则数据字典里记录的便是引号里的大小写,而不是默认的大写,一般不加引号,因为会默认转换成大写到数据字典里查找对象
•A nonquoted identifier is not surrounded by any punctuation.
2.You can use either quoted or nonquoted identifiers to name any database object. However, database names, global database names, and database link names are always case insensitive and are stored as uppercase. If you specify such names as quoted identifiers, then the quotation marks are silently ignored.
Note:
Oracle does not recommend using quoted identifiers for database object names. These quoted identifiers are accepted by SQL*Plus, but they may not be valid when using other tools that manage database objects.
The following list of rules applies to both quoted and nonquoted identifiers unless otherwise indicated:
1.Names must be from 1 to 30 bytes long with these exceptions:
•Names of databases are limited to 8 bytes.
•Names of database links can be as long as 128 bytes.
If an identifier includes multiple parts separated by periods, then each attribute can be up to 30 bytes long. Each period separator, as well as any surrounding double quotation marks, counts as one byte. For example, suppose you identify a column like this:
"schema"."table"."column"
The schema name can be 30 bytes, the table name can be 30 bytes, and the column name can be 30 bytes. Each of the quotation marks and periods is a single-byte character, so the total length of the identifier in this example can be up to 98 bytes.
/*查看创建tablespace的默认类型*/
SELECT * FROM DATABASE_PROPERTIES WHERE PROPERTY_NAME='DEFAULT_TBS_TYPE';
/*修改默认类型*/
ALTER DATABASE SET DEFAULT smallfile TABLESPACE;
ALTER DATABASE DEFAULT TABLESPACE USERS;
##查看ora的具体报错信息
oerr ora 16651
Oracle加黑白名单
vim sqlnet.ora
NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
tcp.validnode_checking = YES
TCP.EXCLUDED_NODES=(192.168.56.110)修改sqlnet.ora后,重新启动listener服务















 2710
2710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









