






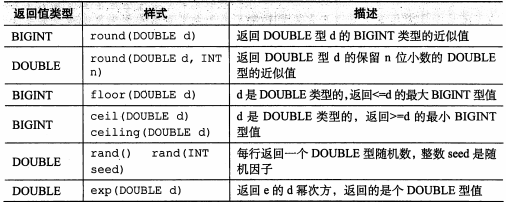
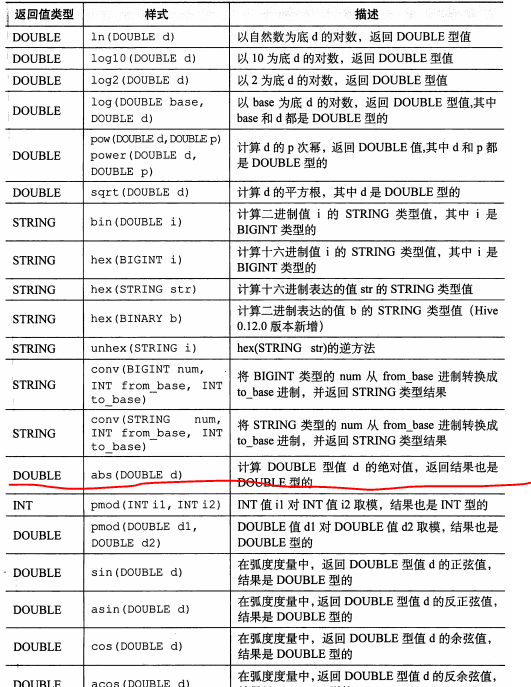
一、数学函数
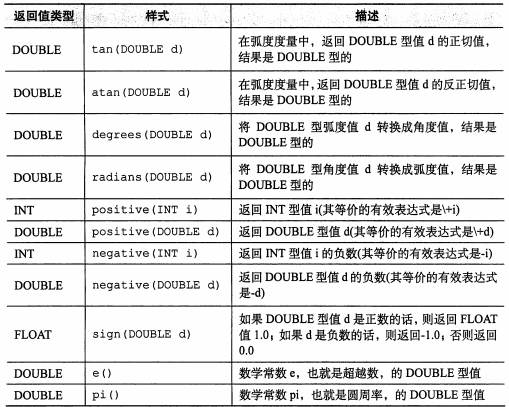
二、聚合函数
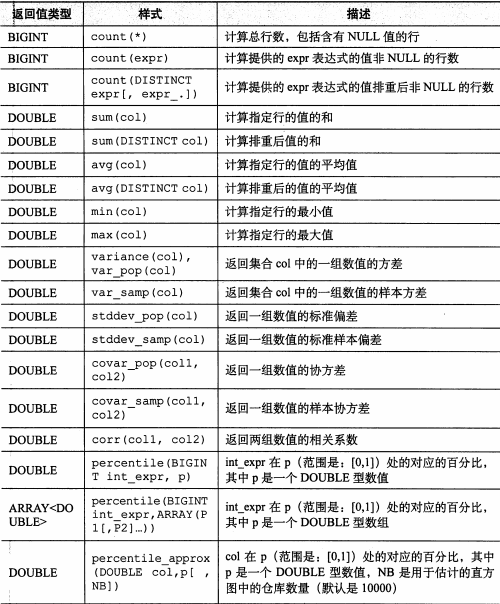
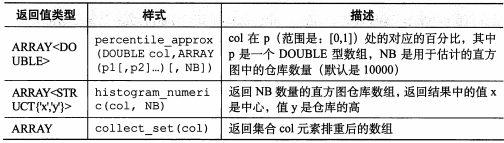
三、其他内置函数
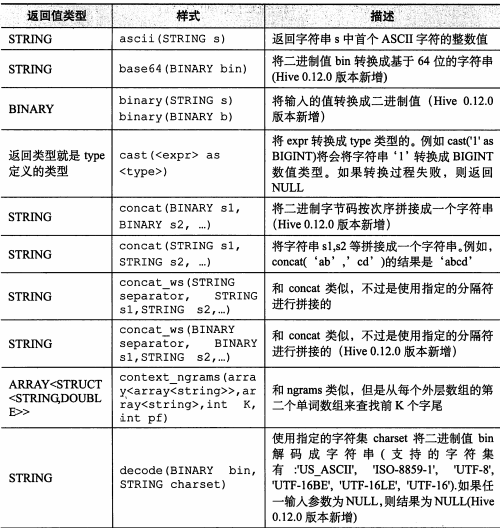
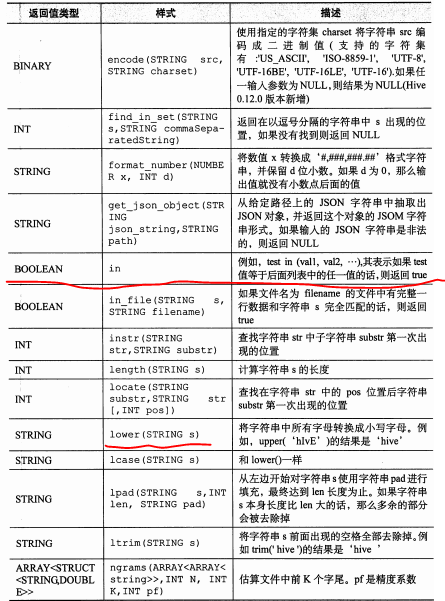
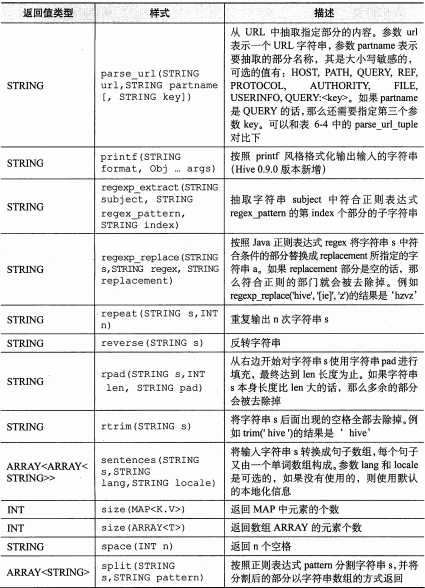
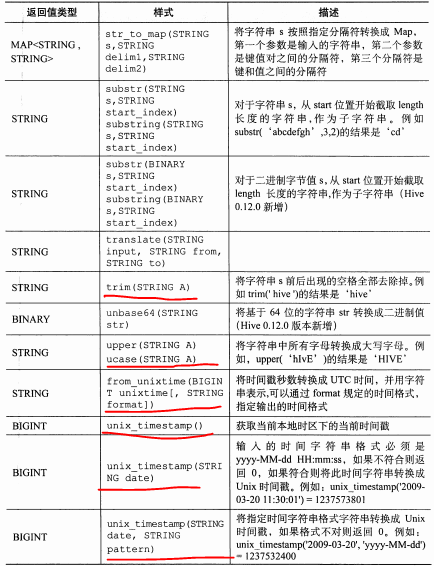
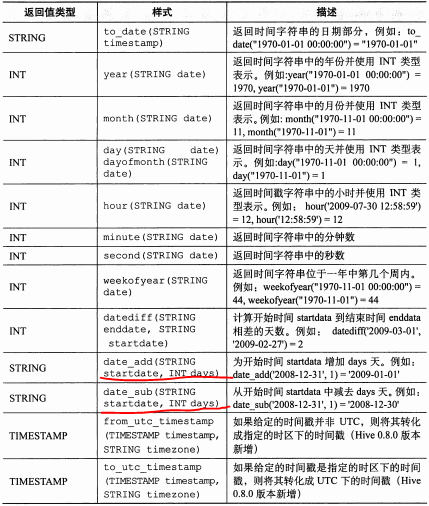
hive分析函数
union 和 union all
union 操作符用于合并两个或多个 SELECT 语句的结果集(追加到后面)。
如果允许重复的值,请使用 UNION ALL。
举例:
下面的例子中使用的原始表:
Employees_China:
E_ID E_Name
01 Zhang, Hua
02 Wang, Wei
03 Carter, Thomas
04 Yang, Ming
Employees_USA:
E_ID E_Name
01 Adams, John
02 Bush, George
03 Carter, Thomas
04 Gates, Bill
-- 使用 UNION 命令
SELECT E_Name FROM Employees_China union
SELECT E_Name FROM Employees_USA
-- 结果
Zhang, Hua
Wang, Wei
Carter, Thomas
Yang, Ming
Adams, John
Bush, George
Gates, Bill
-- 使用 union all 命令
SELECT E_Name FROM Employees_China union
SELECT E_Name FROM Employees_USA
-- 结果
Zhang, Hua
Wang, Wei
Carter, Thomas
Yang, Ming
Adams, John
Bush, George
Carter, Thomas
Gates, Bill
left join
LEFT JOIN 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行。
-- "Persons" 表:
Id_P LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
-- "Orders" 表:
Id_O OrderNo Id_P
1 77895 3
2 44678 3
3 22456 1
4 24562 1
5 34764 65
-- 语句
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
LEFT JOIN Orders
ON Persons.Id_P=Orders.Id_P
ORDER BY Persons.LastName
-- 结果集:
LastName FirstName OrderNo
Adams John 22456
Adams John 24562
Carter Thomas 77895
Carter Thomas 44678
Bush George
-- LEFT JOIN 关键字会从左表 (Persons) 那里返回所有的行,即使在右表 (Orders) 中没有匹配的行。right join
RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name1) 中没有匹配的行。
full join
只要其中某个表存在匹配,FULL JOIN 关键字就会返回行。
DISTINCT
DISTINCT 用于返回唯一不同的值。
-- "Orders"表:
Company OrderNumber
IBM 3532
W3School 2356
Apple 4698
W3School 6953
-- 语句
SELECT DISTINCT Company FROM Orders
-- 结果:
Company
IBM
W3School
Appleinsert
insert overwrite 会覆盖已经存在的数据,我们假设要插入的数据和已经存在的N条数据一样,那么插入后只会保留一条数据;
insert into 只是简单的copy插入,不做重复性校验,如果插入前有N条数据和要插入的数据一样,那么插入后会有N+1条数据;
GROUPING SETS
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,GROUPING__ID
FROM lxw1234 GROUP BY month,day GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
-- 等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM lxw1234 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM lxw1234 GROUP BY day
CUBE
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM lxw1234
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
-- 等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM lxw1234
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM lxw1234 GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM lxw1234 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM lxw1234 GROUP BY month,day
CUME_DIST
–CUME_DIST 小于等于当前值的行数/分组内总行数
–比如,统计小于等于当前薪水的人数,所占总人数的比例
select * from lxw1234;
d1 user1 1000
d1 user2 2000
d1 user3 3000
d2 user4 4000
d2 user5 5000
-- 语句
SELECT
dept,
userid,
sal,
CUME_DIST() OVER(ORDER BY sal) AS rn1,
CUME_DIST() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM lxw1234;
dept userid sal rn1 rn2
-------------------------------------------
d1 user1 1000 0.2 0.3333333333333333
d1 user2 2000 0.4 0.6666666666666666
d1 user3 3000 0.6 1.0
d2 user4 4000 0.8 0.5
d2 user5 5000 1.0 1.0
-- rn1: 没有partition,所有数据均为1组,总行数为5,
-- 第一行:小于等于1000的行数为1,因此,1/5=0.2
-- 第三行:小于等于3000的行数为3,因此,3/5=0.6
-- rn2: 按照部门分组,dpet=d1的行数为3,
-- 第二行:小于等于2000的行数为2,因此,2/3=0.6666666666666666
COUNT
| COUNT(column) | 返回某列的行数(不包括 NULL 值) |
| COUNT(*) | 返回被选行数 |
GROUP BY
-- "Orders" 表:
O_Id OrderDate OrderPrice Customer
1 2008/12/29 1000 Bush
2 2008/11/23 1600 Carter
3 2008/10/05 700 Bush
4 2008/09/28 300 Bush
5 2008/08/06 2000 Adams
6 2008/07/21 100 Carter
-- 我们想要使用 GROUP BY 语句对客户进行组合。
-- SQL 语句:
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
-- 结果:
Bush 2000
Carter 1700
Adams 2000UCASE()
UCASE 函数把字段的值转换为大写。
SELECT UCASE(column_name) FROM table_name
LCASE()
LCASE 函数把字段的值转换为小写。
SELECT LCASE(column_name) FROM table_name
MID() 函数
MID 函数用于从文本字段中提取字符。
-- 语法
SELECT MID(column_name,start[,length]) FROM table_name
-- 参数 描述
-- column_name 必需。要提取字符的字段。
-- start 必需。规定开始位置(起始值是 1)。
-- length 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
-- "Persons" 表:
Id LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
-- 我们希望从 "City" 列中提取前 3 个字符。
-- SQL 语句:
SELECT MID(City,1,3) as SmallCity FROM Persons
-- 结果:
SmallCity
Lon
New
Bei
LEN() 函数
LEN 函数返回文本字段中值的长度。
-- 语法
SELECT LEN(column_name) FROM table_name
-- "Persons" 表:
Id LastName FirstName Address City
1 Adams John Oxford Street London
2 Bush George Fifth Avenue New York
3 Carter Thomas Changan Street Beijing
-- 我们希望取得 "City" 列中值的长度。
-- SQL 语句:
SELECT LEN(City) as LengthOfCity FROM Persons
-- 结果:
LengthOfCity
6
8
7ROUND() 函数
ROUND 函数用于把数值字段舍入为指定的小数位数。
-- 语法
SELECT ROUND(column_name,decimals) FROM table_name
-- 参数 描述
-- column_name 必需。要舍入的字段。
-- decimals 必需。规定要返回的小数位数。
-- "Products" 表:
Prod_Id ProductName Unit UnitPrice
1 gold 1000 g 32.35
2 silver 1000 g 11.56
3 copper 1000 g 6.85
-- 我们希望把名称和价格舍入为最接近的整数。
-- SQL 语句:
SELECT ProductName, ROUND(UnitPrice,0) as UnitPrice FROM Products
--结果:
ProductName UnitPrice
gold 32
silver 12
copper 7














 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









