






要说现在市面上最火爆的手游,莫非拥有两亿注册用户的王者荣耀了。据悉,王者荣耀的渗透率高达22.3%,这意味着每7个中国人中就有一位是王者荣耀注册用户。众所周知,手游App对推送实时性和精准性要求非常高,而王者荣耀这种日活跃千万级的应用对推送的要求就更高了,下面我们来看看王者荣耀背后的信鸽推送是怎么应对挑战,做到海量、实时和精准推送的。
2017年7月7日-8日,ArchSummit全球架构师峰会在深圳召开。ArchSummit全球架构师峰会是InfoQ中国团队推出的面向高端技术管理者、架构师的技术大会,展示新技术在行业应用中的最新实践,其中超过上百位技术专家,千名技术人共同参与,包括海外的facebook、ebay、hulu,国内的BAT、YY、京东等,群英荟萃,精彩纷呈。
腾讯移动推送(信鸽)高级工程师甘恒通在本场架构师峰会上分享了:腾讯移动推送(信鸽)百亿级实时消息推送的实战经验,解析了信鸽实时精准推送系统的演进与实践。
信鸽的挑战
应用的用户的生命周期来说分5个阶段,即用户的获取、激活、留存、传播和收入,信鸽的消息推送是触达用户,提升留存的重要途径。
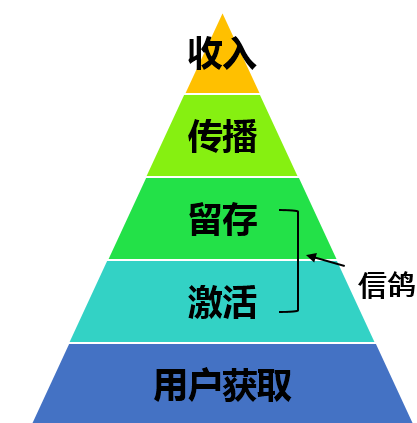
信鸽平台现已服务于数万的App开发者,日推送消息数60亿,推送支撑能力超过百亿;而精准推送是有效提高消息打开率的手段。信鸽的实践中案例数据表明,精准推送的平均CTR是全量推送的4倍!
那么,如何实现海量数据的压力下,满足实时、精准的推送要求,这里有很大的挑战。
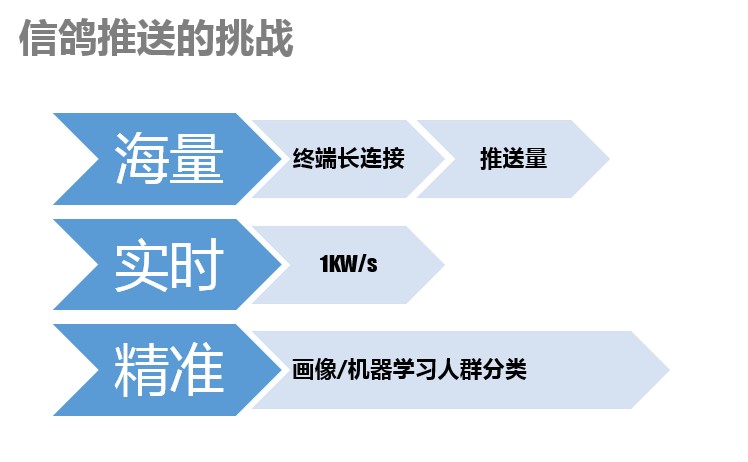
这里我们主要讨论的是对于信鸽后台的挑战,主要有这三个关键字:海量、实时和精准。
海量是指,信鸽终端并发长连接是数千万,日推送量也有百亿的量级,服务于很多大客户,如王者荣耀,日活跃数千万,其推送量可想而知。
另外一些特殊行业的App,也有特别的推送诉求。比如资讯类的应用,时效性要求非常高,需要每秒千万级的推送速度。
而另一些应用则需要在达到运营目标的前提下,希望尽量减少对用户的骚扰,即精准推送。
信鸽的应对之道
对于信鸽面临的挑战,我们做了哪些解决方案?
首先信鸽是一个免费的运营工具,成本是我们这边一个很大的需要考量的点:一方面,需要提高设备资源的利用率,可以通过一些虚拟化的方式来解决;第二方面,我们要深入挖掘单机的性能。
对于单机性能的优化,有4个方面,从下往上看是硬件、操作系统、协议栈、架构。
1、操作系统优化
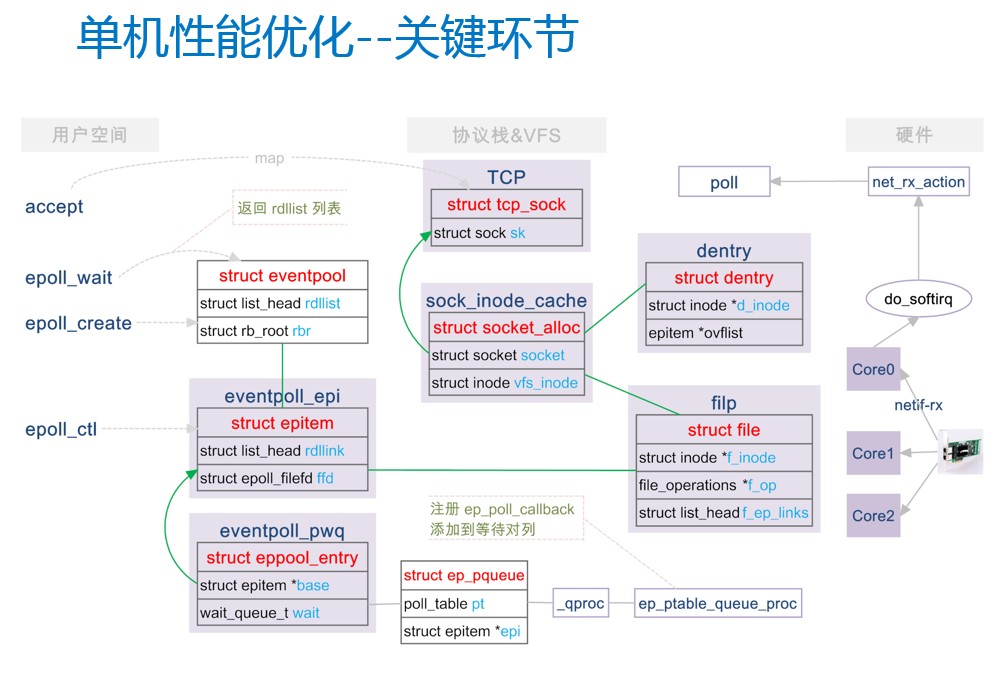
先看一下在操作系统这个层级是如何对海量并发长连接的接入进行优化的。这里主要挑战是在内存,通过slabtop命令可以看到当前系统内存分配的情况。从这一栏可以看到,当我们构建了大概200万长连接的时候,整个系统的内存基本上已经满了。对于长连接的内存使用,会消耗在这6个数据结构上。
我们深入分析这6个来自epoll模型和内核TCP协议栈的数据结构。对于epoll模型,底层实现是一个特殊的文件系统,epoll文件的内容主要是保存了一棵红黑树和就绪的被侦听文件列表rdllist,红黑树的节点是被侦听文件对象。epoll主要提供了三个API:epoll_wait、epoll_create、epoll_ctl。当我们通过epoll_ctl把一个文件加入到epoll的时候,会创建两个数据结构epitem、eppool_entry,epitem关联到被侦听的文件fd,eppool_entry保存了事件就绪时设置rdllist的回调函数ep_poll_callback。我们从另外一个链路看一下网卡的收包流程,当数据包过来的时候,网卡接收完数据会产生一个硬中断,数据通过DMA拷贝到内存。系统通过软中断守护进程,调用网卡的驱动来完成数据包的解析并最终调用poll方法。poll方法会回调设置好的ep_poll_callback,即把fd挂到rdllist中,当调用的epoll_wait时候,即可获取到就绪的fd集合。
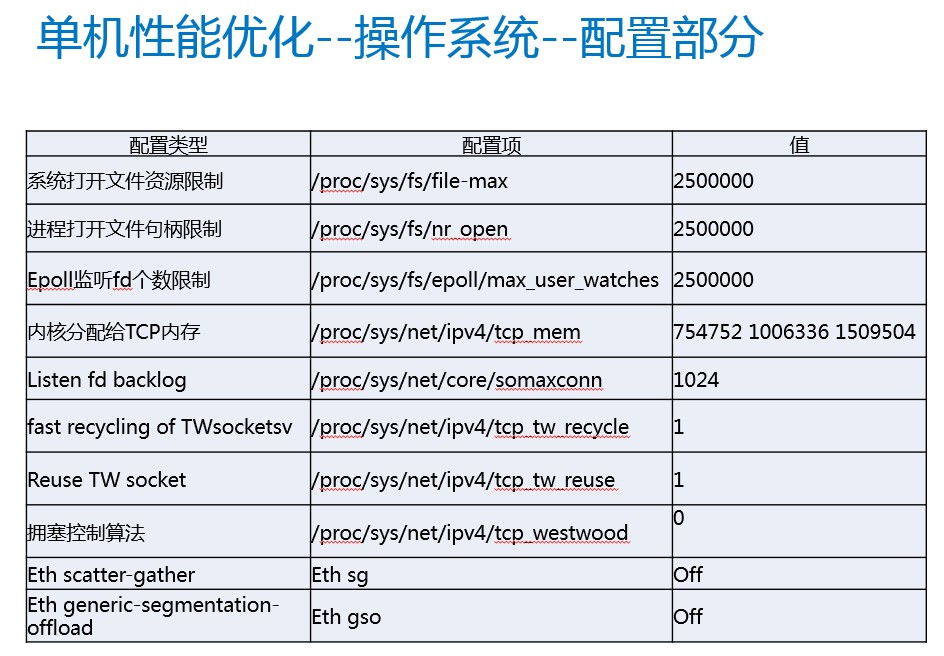
对于海量的并发连接,主要通过调整操作系统的配置来解决。信鸽使用了公司自研的tlinux 2.0,系统对于内存这一块也做了比较多的优化,具体的配置参数如下,可以看到,主要也是一些epoll的限制和TCP的内存的限制。

2、Server框架优化
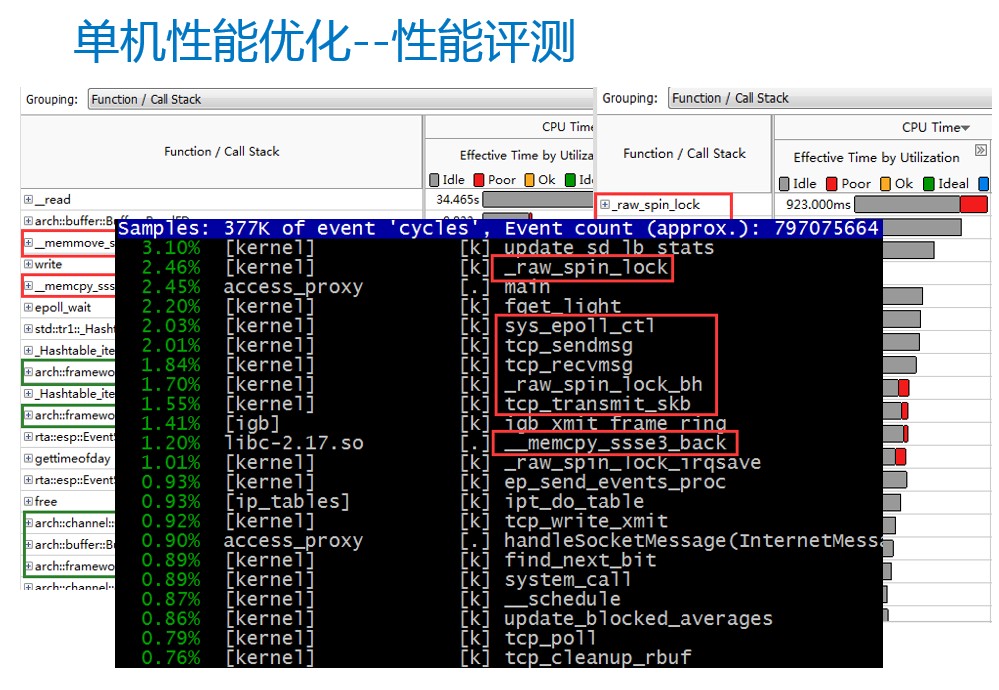
看完操作系统层级的优化,我们再来看一下另一个主要性能优化的点——server框架。信鸽对于关键的接入层server使用C++语言进行开发。好的server框架主要有两个要点,1是对底层RPC通信的良好封装,使得开发只需要关注业务逻辑代码的开发,2是高性能,框架对消息处理CPU消耗尽可能少。通过Intel® VTune™ Amplifier这个工具我们可以对server框架进行性能评测,这里列了两个框架。左边这个框架可以看到把很多CPU都浪费在消息的内存拷贝,同时对消息的处理进行了过多的封装。对于右边的框架就做得比较好,对于框架的问题就不存在了,主要是操作系统本身的消耗,还有协议栈的消耗。这部分对于有更高的要求来说,还可以进行深度优化。这是我们后台选用的框架,主要实现的要点有三个,第一是池化技术、第二是协程模型、第三是无锁框架。这里的Proxy主要用于接入网络的请求,具体的业务逻辑代码是放在Work进程里面处理。整个框架做了一个通用的抽象,将一次数据请求主要分为数据接收、数据路由、最后是具体的数据处理。数据接入进程和具体数据处理进程,通过无锁的共享内存来通信,这样就避免了很多不必要内存拷贝和消息编解码操作。
对于处理业务逻辑的工作进程,比较常见的有三种模型,第一种是进程同步模型,数据进来以后,由独立的线程进行处理,优点是代码实现比较直观,缺点是处理海量并发用户请求的时候,操作系统对多线程的切换会成为一个主要的瓶颈。第二种用得比较多的是异步事件驱动模型,由epoll进行事件的侦听,通过一些状态机来驱动业务逻辑代码的执行,优点是性能较高,缺点是当业务逻辑分支多的时候,代码非常难维护。我们这边是采用协程模型,协程和线程和类似,它跟线程不同的是,线程的切换和调度需要自己来实现,协程模型可以采用同步的思维进行代码开发,又具有异步模型的高性能,协程切换优化的点是,通过汇编的方式,直接把相关寄存器中的值保存在内存,来进行上下文的切换。
3、协议栈优化
下面我们看一下协议栈的优化。这里的协议栈主要是指linux内核TCP协议栈。linux内核的协议栈主要问题是相关Socket的方法都是系统调用,需要从用户态切换到内核态,数据从内核空间到用户空间也需要进行额外的内存拷贝操作。业界有一些开源的用户态TCP协议栈,可以解决这两个问题。使用用户态的TCP协议栈需要优化的点是相关的接口和系统自带的Socket接口命名不一致,直接使用涉及到大量代码的修改,我们怎么样做到在不修改代码的情况下用TCP协议栈呢?这里是通过Hook机制,拦截相关Socket系统调用,dlsym符号解析返回自定义的Socket方法。
4、硬件性能挖掘
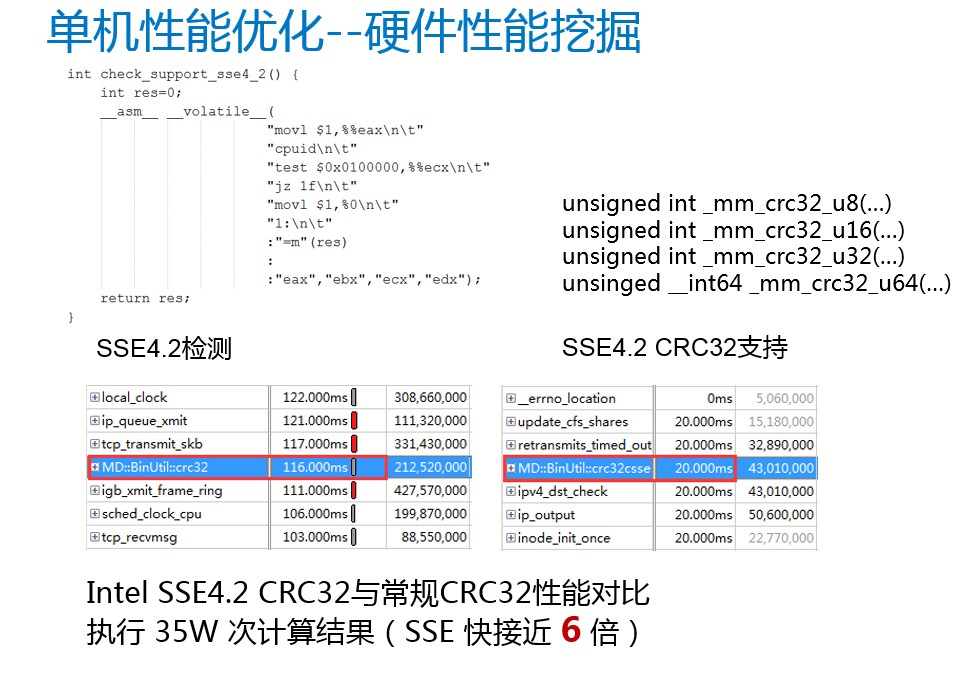
下面我们再看一下单机性能优化的最后一个点——对于硬件性能的挖掘。硬件性能的挖掘,主要是善于利用Intel CPU的指令集。可以拿我们经常使用的CRC32操作来举例。一般的CRC32实现是根据算法定义来执行字节转码操作,而Intel提供了一套SSE4.2的指令集,它里面包含CRC32的方法。我们可以看一下35W次计算两者的耗时对比,直接用Intel的指令集比一般的实现方法快6倍。
小结:性能好,推送才能顶住海量信息的压力,支撑公司内外业务核心,提供强有力的通道支持。
实时方案的构建
对海量设备进行实时推送主要的解决方案是针对推送的场景优化存储结构,同时将单个推送的RPC节点间调用转换成分布式的批量位图运算,优化Android终端长连接,接入集群分多地部署,做最近接入,和APNs的交互使用HTTP/2协议,对无效的token自动做数据清理。
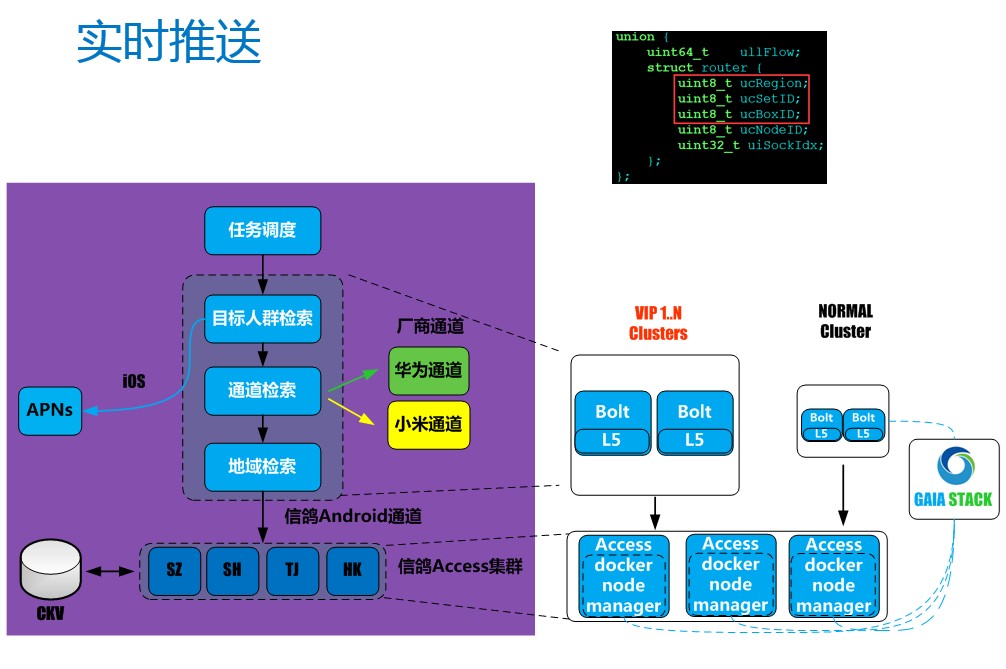
我们这里举一个具体的场景来说一下倒排索引是如何应用到实时推送中的。比如一个应用对在广东的男性用户进行一次推送,会经过一个这样通用的推送流程:一个推送的任务到达一个调度的节点,决定是否下发推送任务,如果下发,则会经过目标人群的检索,筛选出男且是广东的用户,接下来进行通道检索,信鸽这边既有自建的通道,也有厂商的通道,用户在推送的时候,他可能觉得厂商的通道更加稳定、更加高效,这个时候他可以选择对于华为设备走华为通道、小米设备就走小米通道,对于其它的设备就走信鸽自建的通道。下一步就是地域检索,信鸽这边的设备是就近接入的,我们在全国部署有这几个集群,分别是深圳集群、上海集群、天津集群和海外的HK集群。这里选择了广东的用户,所以选择深圳集群。对于一个传统的系统来说,一次推送可以这样实现,一个应用下的N个用户的推送,转换成N次RPC节点间调用,人群信息、通道信息、地域信息分别保存在Mysql或者Nosql数据库中,每个RPC调用,需要到数据库里面检查一下他是否是男的,是否是广东的用户,再看一下是不是华为的设备或者小米的设备,判定完之后要进行地域的检索,看看接入的是哪个集群。整个流程下来之后,要经过大量的数据库操作,才能完成一次推送。
但是经过倒排索引的构建之后,所有的数据都可以放到内存中。比如男性人群,可以构建一个bitmap,小米的通道也是一个bitmap,华为的通道也是一个bitmap,不同的地域分别是不同的bitmap。当一次任务下发的时候,对bitmap进行一些&操作,就可以把最终需要推送的人群下发到相应的接入机中,整个过程可以做到ms级别。对于推送下发整个流程,检索是一方面,另一方面还需要查询路由信息找到终端TCP长连接的接入机,这些路由信息包含接入机的编号、进程的编号、长连接socket fd的编号,用一个long数据类型即可保存,所有的路由信息保存在分布式的Nosql内存数据库中,整个推送流程只有接入机的路由需要进行数据库的查询,结合本地的缓存,可以做到kw/s的推送下发速度。
精准推送的构建
信鸽的推送系统主要分为三部分,第一部分是数据、第二部分是具体的系统实现、第三部分是具体的应用。
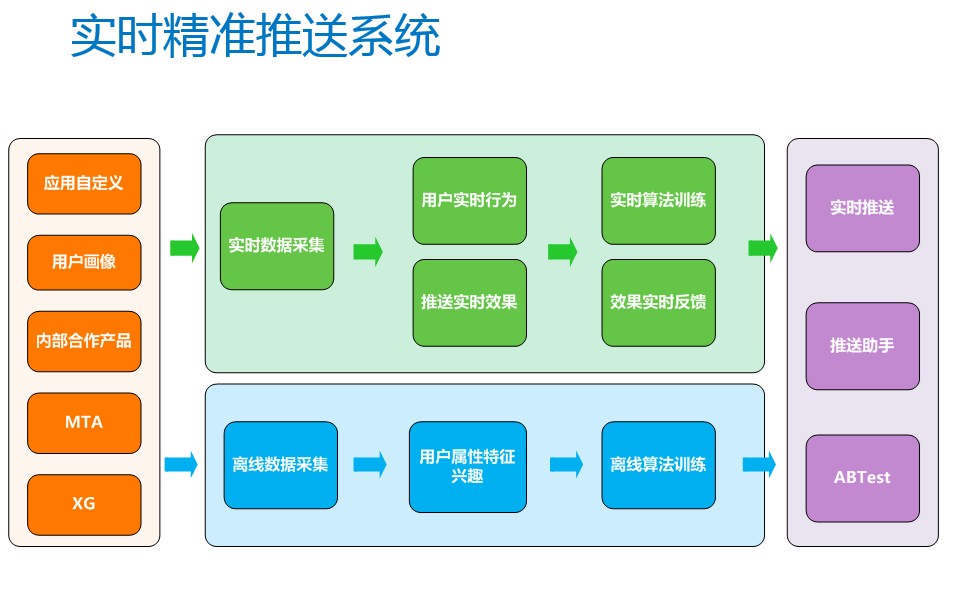
具体的应用有这三个:实时推送、推送助手、ABTest。推送助手和ABTest的作用是更好地帮助用户使用消息推送来进行产品的运营。比如推送助手,对于很多运营人员来说,可能没有相关的运营经验,对内容的管理,他可能只大概知道需要推送的目标群体,但是他对推送文案不知道如果编写会更好,这个时候我们后台会对历史的推送进行数据的收集,对文案和推送的效果进行关联性的分析,当他选择一个推送场景的时候,我们就会把一些文案的样式和关键词给到他,让他自己组织出一个更好的推送的文案。另外一个是ABTest,用户自己手里有几个文案或者目标推送人群,当他不确定的哪个更合适的时候,我们给他提供ABTest的能力,从目标推送人群中抽取部分测试用户,多个文案经过实时推送,在几分钟的时间里,把推送的效果即点击率反馈给用户,系统自动或者由用户选择一个最佳的推送文案或者是一个最佳的目标人群对剩下的用户进行推送。
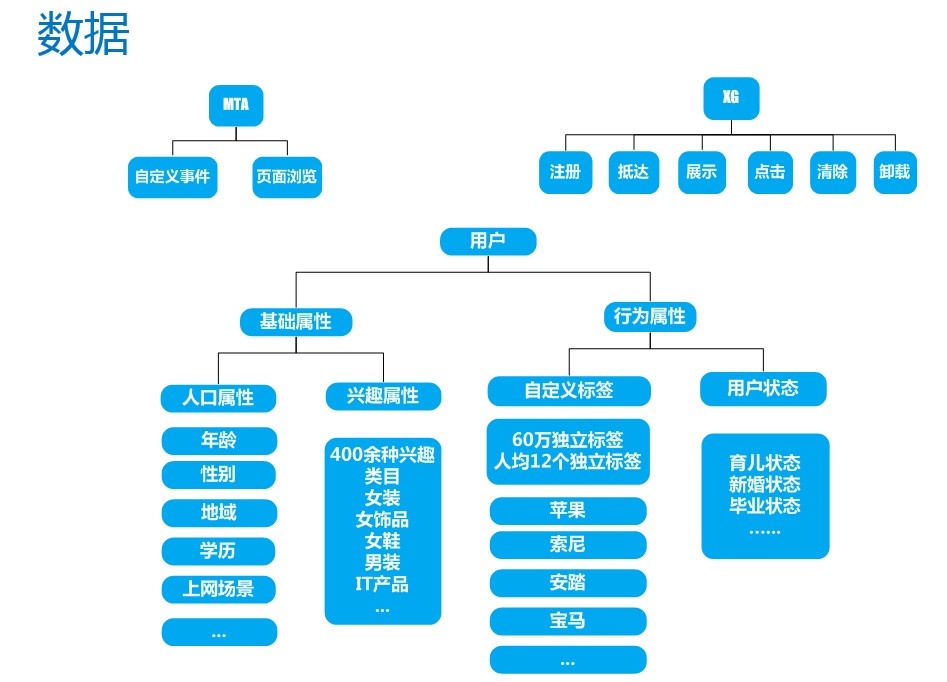
下面看一下系统的实现,主要分实时和离线。离线部分主要是用来进行人群的挖掘。对于精准推送来说,它的核心是根据应用运营的目标将消息推送给匹配的目标人群。应用的运营的目标一般有提升用户活跃度,潜在流失用户挽回,提升应用收入等,不同人群的挖掘方法可能不尽相同,但流程基本一致,一般会分为数据的准备、模型的构建、预测结果、输出。
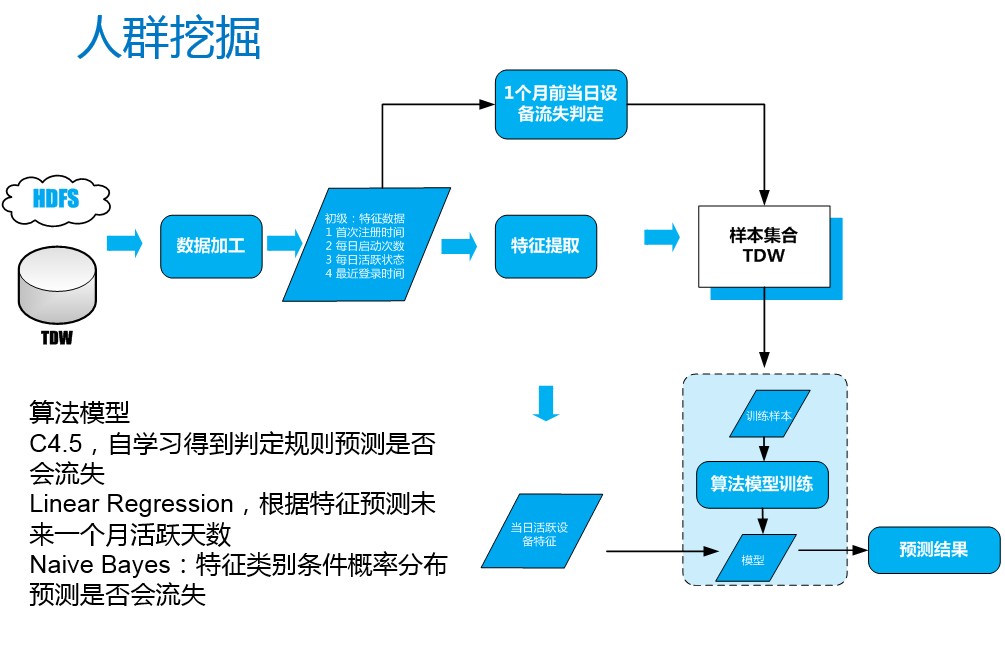
我们这里举一个实际的潜在流失用户人群挖掘的例子。我们想预测一下这个应用里面可能有哪些人是会流失的,这样应用可以针对这部分人群做一些挽留的推送。原始数据保存在HDFS或者TDW里面,经过数据加工以后,把用户可能流失的一些特征给提取出来,比如说有首次注册的时间、每日启动的次数、每日的活跃状态和最近登录的时间。特征提取后有两条路径,一是要构建一个潜在流失用户预测的模型,二是在模型的基础上进行潜在流失用户的预测。对于模型构建部分,需要结合真实的流失情况和特征,作为训练的样本,经过算法模型的训练之后,我们就得到了一个潜在流失用户预测的模型。对于每天新增的数据,我们也是经过特征提取之后,把数据输入这个模型里面,就会得到一个具体的预测结果即可能会流失的人群集合。对于算法模型,我们这边主要用了一些机器学习里面的统计学习的方法,没有用到一些现在比较火的深度学习的方法。因为我们在实际进行训练的时候发现当我们的数据样本非常大的时候,用一般的比如C4.5决策树模型,通过一些判定规则,就能够知道用户是否流失,或者是贝叶斯,通过特征类别的条件概率分布预测是否会流失,采用这些模型召回率可以达到0.76和0.89的水平,已经满足我们的应用场景,所以没有采用计算复杂度更高的深度学习的模型。
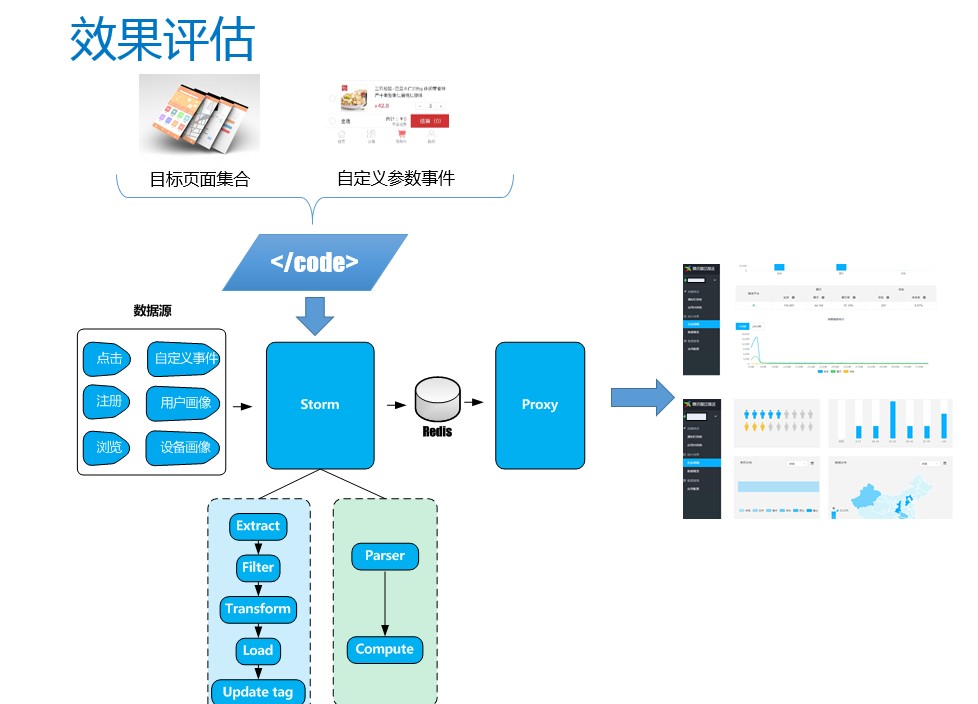
实时效果评估
信鸽最新更新的实时效果功能,为用户提供了推送效果的实时统计。面对百亿级推送的压力,实时统计也会占用很大的计算资源,那么信鸽是如何实现这一功能的呢?
一般推送的效果评估主要看CTR,但是CTR可能对于一些用户来说,不能反映他的运营目标,他可能更关注的效果是我做了一次推送,用户有没有到达我的目标页面,或者说推送了正在进行促销的通知,有没有更多人进行下单购买。这些场景可以通过在前台给用户管理推送效果跟踪配置的方式来实现。用户每次推送之前,可以指定推送效果如何评估,这里可能是一些目标页面集合的浏览pv或者自定义事件的uv,系统把它转化成一个配置文件。当他进行推送的时候,我们就会把配置文件下发到统计系统里去。当执行推送完之后,应用的用户就会产生点击、注册、浏览的行为。这些数据到进入到系统的时候,主要会做两部分的操作,第一部分是根据推送文件指定的方法进行数据的抽取、过滤、转换、加载并更新相关的倒排索引数据,当真正需要指标输出的时候,我们会有一个管理的节点,进行计算规则的下发,比如说点击的用户里面有多少是男的,检索以后进行一次bitmap的&操作,就能统计出有多少用户了。数据会实时刷新到Redis存储中,应用开发者在前台查询结果的时候,我们就会把这个结果反馈给用户。
能看到这里的都是真爱!今天的干货分享就先到这里~
本文的姊妹篇《百亿级消息推送背后的故事——来自于infoQ的前方报道》将于下周推出,敬请关注哦!
联系我们:
如果您希望试用或者体验信鸽推送,请访问信鸽官网接入试用。
如果您对该功能有疑问、或者在使用中遇到了困难,欢迎您联系信鸽官网在线客服,或者发送您的问题邮件至:dtsupport@tencent.com
商务合作或业务咨询,请联系以下邮箱:mta@tencent.com

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









