






一、HashMap存取效率高原因
1、Hash
也叫散列、哈希。
主要用于信息安全领域中的算法,把长度不同的信息转化为杂乱的128位的编码,找到一种数据内容与地址之间的映射关系。
注意:不同的输入可能会散列成相同的输出
我们最熟悉的Object类中就提供了hashcode的方法。
public native int hashCode();
2、数据结构
Java集合的实现底层大都是基本数据结构的又一层封装。
数组:寻址容易,插入和删除困难
链表正好相反。
HashMap正好将二者互补了一下,推出了链表+数组的组合方式,也叫链表散列、“拉链法”。
结构示意图:
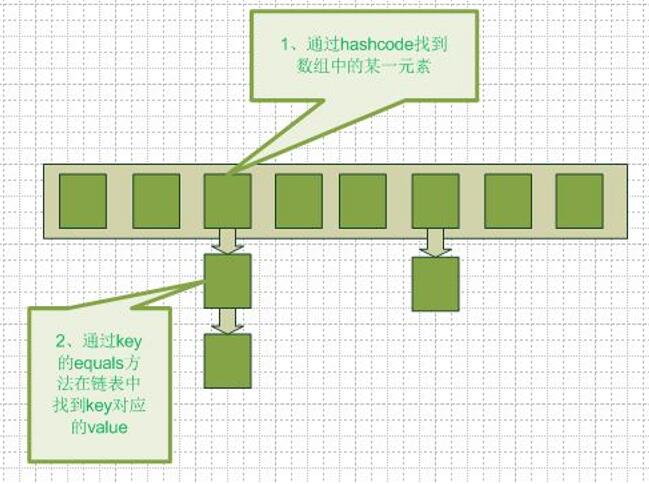
放入元素时,根据key值通过hashcode找到对应数组的位置,放入横向数组的某个格子中。因为前面说到hashcode值不能保证唯一,如果之后hashcode值对应的数组位置中已经有值,就放到相连的链表中。
查找元素也是按这个过程来进行。
代码实现:
注意:每个Node中都持有下一个节点的引用。 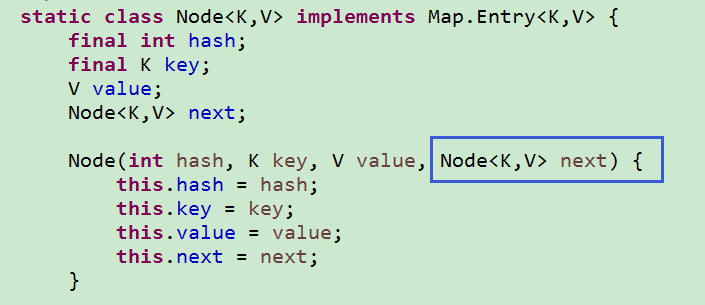
3、算法优化
由上面的数据结构介绍,可以看出,在查找的时候,尽量避免查找链表能够大大提高存取效率。
目标:元素尽可能均匀分布,这样查找的时候不必查找链表,效率很高。
思路一:
取模运算,实现是可以实现,但取模运算消耗大、效率不高。
思路二:
首先,&运算比取模运算效率高。
hashmap采用的是下面这种与运算。

大同小异,都是为了减少碰撞,避免hash到同一个位置,使元素分布更均匀。在实现的基础上,考虑性能问题。
二、Java中ArrayList和LinkedList区别
ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
上代码:
static final int N=50000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return System.currentTimeMillis()-start;
}
static long readList(List list){
long start=System.currentTimeMillis();
for(int i=0,j=list.size();i<j;i++){
}
return System.currentTimeMillis()-start;
}
static List addList(List list){
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return list;
}
public static void main(String[] args) {
System.out.println("ArrayList添加"+N+"条耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList添加"+N+"条耗时:"+timeList(new LinkedList()));
List list1=addList(new ArrayList<>());
List list2=addList(new LinkedList<>());
System.out.println("ArrayList查找"+N+"条耗时:"+readList(list1));
System.out.println("LinkedList查找"+N+"条耗时:"+timeList(list2));
}当我们在集合中装5万条数据,测试运行结果如下:
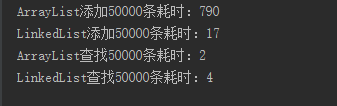
显然我们可以看出ArrayList更适合读取数据,linkedList更多的时候添加或删除数据。
ArrayList内部是使用可増长数组实现的,所以是用get和set方法是花费常数时间的,但是如果插入元素和删除元素,除非插入和删除的位置都在表末尾,否则代码开销会很大,因为里面需要数组的移动。
LinkedList是使用双链表实现的,所以get会非常消耗资源,除非位置离头部很近。但是插入和删除元素花费常数时间。
三、关于JAVA实现链表的基本功能
链表结构,通常包含表头,节点1,节点2...节点n,其中节点又包含了数据内容和下个节点的地址。和数组结构(应该叫做顺序表吧大概......)不一样,链表并不用占据连续的内存,它们的区别就不多说了,相信大家都知道。
说说怎么实现吧,既然要用引用的方式来代替指针,那么就需要一个特别的类结构:需要同名的成员保存下一个节点的信息。
public class Node {
private String data;
private Node nextNode;
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public Node getNextNode() {
return nextNode;
}
public void setNextNode(Node nextNode) {
this.nextNode = nextNode;
}
}该怎么使用呢?让我们来初始化一个链表吧!
private Node InitNode() {
// 当前节点
Node curNode = new Node();
// 构建头结点
Node head = new Node();
head.setData("head");
head.setNextNode(null);
// 当前节点位于头结点
curNode = head;
// 新增第一个节点
Node n1 = new Node();
// 获取到当前节点,使得的下一个节点设置为n1
curNode.setNextNode(n1);
n1.setData("node1");
n1.setNextNode(null);
// 当前节点位于第一个节点
curNode = n1;
// 第二个节点
Node n2 = new Node();
curNode.setNextNode(n2);
n2.setData("node2");
n2.setNextNode(null);
curNode = n2;
// 第三个节点
Node n3 = new Node();
curNode.setNextNode(n3);
n3.setData("node3");
n3.setNextNode(new Node());
curNode = n3;
// 第四个节点
Node n4 = new Node();
curNode.setNextNode(n4);
n4.setData("node4");
n4.setNextNode(new Node());
curNode = n4;
return head;
}注意curNode的变动,使得当前节点总落在最后一个节点上,下次插入时就不需要知道前面一个节点的名字了,通过curNode就可以直接插入了。
到底成功了没有,我们来遍历一下。
LinkMain m = new LinkMain();
Node testNode = m.InitNode();
Node iter = testNode.getNextNode();
while (null != iter) {
if (null != iter.getData()) {
System.out.println(iter.getData());
}
iter = iter.getNextNode();
}输出结果如下: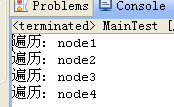 ,
,
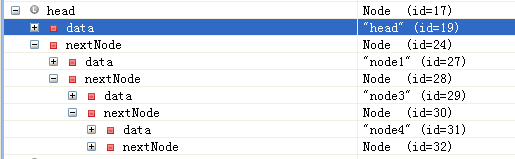
其中testNode是这样的:
----------------------------分割线---------------------------------------
OK,搞定了初始化和遍历,让我们来试试插入一个节点吧,需求是在某个链表中,第N个位置插入一个节点temp:
新增原理:对于temp节点来说
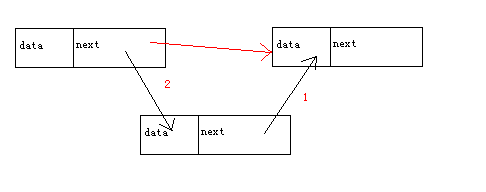
红色代表的是之前连接,黑色的是之后应该做的。
private Node addNode(Node head, int n, Node temp) {
int i = 0;
while (null != head) {
if (i == n) {
temp.setNextNode(head.getNextNode());
head.setNextNode(temp);
return head;
} else {
head = head.getNextNode();
i++;
}
}
return head;
}新增后再遍历一下
// 新增一个节点
Node temp = new Node();
temp.setData("tempNode");
temp.setNextNode(null);
Node n3 = m.addNode(testNode, 2, temp);
iter = testNode.getNextNode();
while (null != iter) {
if (null != iter.getData()) {
System.out.println(iter.getData());
}
iter = iter.getNextNode();
}那么效果如何呢?
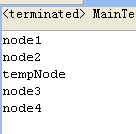
其中testNode的内容应该是
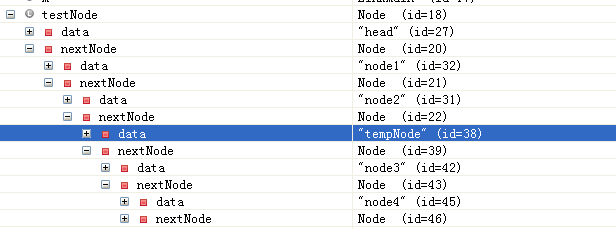
OK,结果正确。
----------------------------分割线---------------------------------------
链表的删除节点功能
一开始还搞不定删除,后来画图分析了下,终于解决,放上代码。
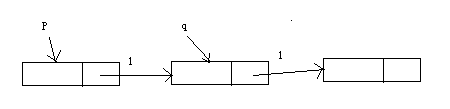
难点是设置P,Q两点的指向。其中q是p的下个节点。
应该先找到需要删除的位置。

原理很简单,就是要绕过q来连接p和后后(q后面的节点)节点。
删除前:

删除后:















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









