






Outline:
-
Data Ming概念、用处及分析
-
数据归一化、处理及计算
-
关联规则、建立及实现
-
聚类算法
-
分类算法
一、 Data Mining
(一) 动机
(1) 数据的指数级增长
(2) 数据的收集和可用性
(3) 数据库种类的多样性
(4) 大量的数据需被收集和存储
(5) 提取和使用数据背后隐藏的信息,存在巨大的竞争压力
(6) 需要更强的数据分析技术和研究方向上的资助
(7) 知识方面的匮乏
(8) 大量数据集的自动分析
(二) 概念
(1) 在大量的数据库中发现有用、能够理解的模式
(2) 交叉性学科
(3) 大规模、高维度的数据
(4) 数据的复杂度较高
(5) 应用程序的更新和复杂
(三) 特征、用途
(1) 大量的数据集
(2) 从历史数据中,自动搜索感兴趣的模式
(3) 快速、大规模
(4) 易于更新、易于实践
(5) 有相应的决策支持
(四) 模式类型
Associated rules(关联规则 )
Detect sets of attributes or items that frequently co-occur in many database records and rules among them.
Classification(分类)
Build a model of classes on training dataset, and then, assign a new record to one of several predefined classes.
Presentation:Decision Tree
Clustering(聚类)
Partition the dataset into groups such that elements in a group hae lower inter-group similarity and higher intra-group similarity.
(将数据集划分成组,使得组中的元素具有较低的组间相似性和较高的组内相似性。)
Sequence mining(序列挖掘)
Give a set of sequences, find the complete set of frequent subsequences.
(给出一组序列,找到一组完整的频繁子序列。)
Anomaly detection(异常检测)
Give a set of n objects, and k, the number of expected anomolies, find the top k objects that are considerably dissimilar or inconsistent with the remaining data.
(给出一组n个对象,并且k(预期的不规则数)找到与剩余数据非常不一致或不一致的前k个对象。)
Community Analysis(社区分析)
Media mining(媒体挖掘)
Recommender Systems(推荐系统)
Recommend products that would be interesting to
Individuals.
Build a function, f : U X I à R, for user set U and item set I.
(五) 数据类型
Database-oriented data sets and applications
Relational Database关系数据库
Structured data(结构性数据)
表结构属性
查询访问,SQL
Data Warehouse
(面向主题,集成,清理的数据集合,用于支持管理层的决策过程)
Transactional Database

Advanced database applications
Data stream
Spatial data
Text databa
Multi-media data
Time-series
Bio-medical data
Network traffic dat
Knowledge Discovery(KDD) Process(Core)
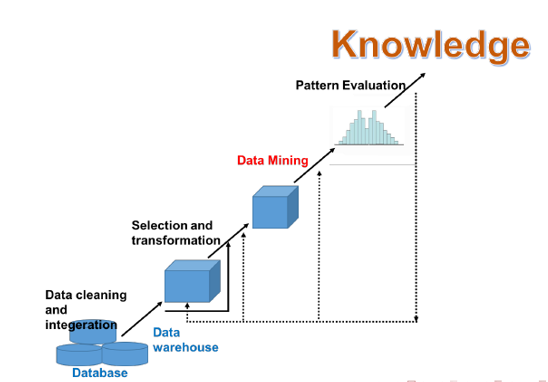
KDD过程的关键步骤:
(1) 应用领域的学习
相应的先验知识和应用的目的
(2) 构造目标数据资源
(3) 数据清洗和预处理
(4) 数据降维和变换
(5) 选择挖掘算法搜寻感兴趣的模式
(6) 获取知识的用途
Interesting Patterns’Metrics:
A pattern is interesting if it is easily understood by humans,valid on new or test data with some degree of certainty,potentially useful,novel,or validates some hypothesis that a user seeks to confirm.
(如果一个模式很容易被人理解,那么这个模式很有意思,它对新的或测试数据有一定的确定性,潜在的有用性,新颖性,或者验证用户想要确认的一些假设。)
<1>数据挖掘的研究问题
a. 挖掘方法
(i) 从不同的数据类型挖掘不同类型的数据
(ii) 高效性和可扩展性
(iii) 并行、分布式、鲁棒式的挖掘方法
(iv) 模式评估
(v) 处理噪声点和不完整的数据
(vi) 背景知识的合并
b. 用户交互
(i) 数据挖掘查询语言
(ii) 数据挖掘结果的表示和可视化
c. 应用和社会影响
(i) 特定领域的数据挖掘
(ii) 保护数据的安全性、完整性和隐私性
<2>在数据挖掘研究上面临的挑战
a. 开发数据挖掘的统一理论
b. 扩展高维数据和高速数据流
c. 挖掘序列数据和时间序列数据
d. 从复杂数据中挖掘复杂数据
e. 网络设置中的数据挖掘
f. 分布式数据挖掘和挖掘多智能体数据
g. 生物和环境的数据挖掘
h. 数据挖掘过程相关问题
i. 安全、隐私和数据完整性
j. 处理非静态、不平衡和成本敏感的数据















 1743
1743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









