






这一章主要介绍,分布式事务的雏形-spring事务在多库下的处理。这个算是比较难得并且很容易在开发过程中遇到各种坑。介绍之前先讲一下问题的缘由,前一阵,一个朋友说他在做一个业务,需要先从A库捞取一些数据,然后再B库里面根据对A库数据的处理来决定是否插入一条数据,在测试的时候测了回滚的情况,但是死活回滚不成功,后来在架构师的帮助下解决了。解决方法是从新配置一个事务管理器,这个东西引起了我的注意,因为我觉得如果在开事务的时候先切数据源应该不会这么麻烦,带着这个问题来探讨。
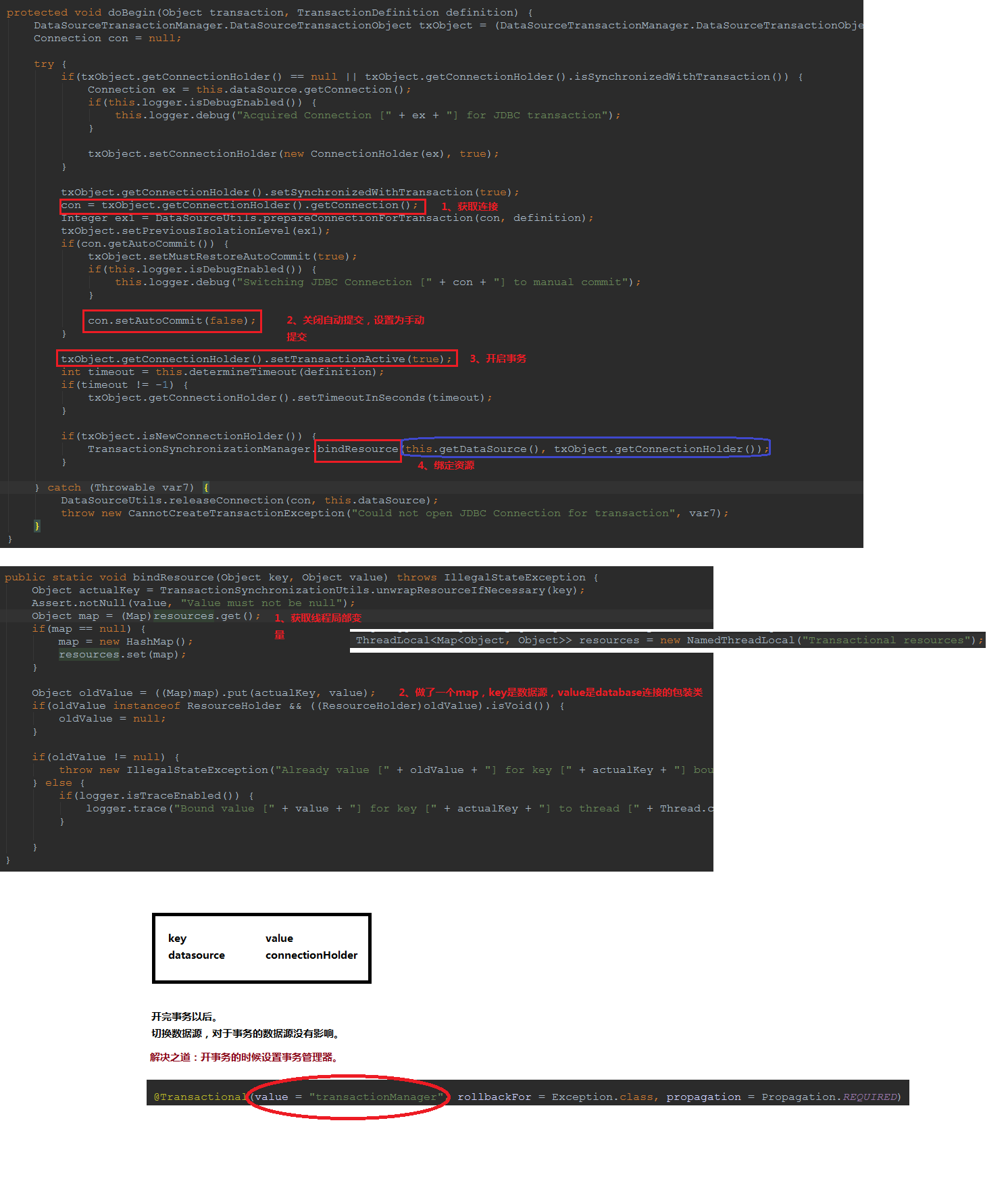
要清楚地看到问题,就必须看一下spring怎么保证从事务中获取的链接是同一个。核心其实就是一个线程局部变量,然后放了一个map,map的key : datasource,value:connection包装类,至于这么做的原因:spring保证多个数据源依然可以在事务中准确获取链接。
那回到那个问题,切数据源为什么回滚无效?假设不在@transactional(value="xxx")配置事务管理器,那么事务管理器一开始会用的默认数据源。类似下图。那么此时在取链接的时候,会看下当前是否存在事务,不存在直接提交,如果存在,那么会拿到datasource,从map中取链接,但是很遗憾,此时的数据源已经不是事务管理器中的那个数据源了,所以取不到。如果配置了事务管理器,那么一切就好办了。
bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <!-- 数据源 dataSource在applicationContext-dao.xml中配置了 --> <property name="dataSource" ref="dataSource"/> </bean>
带着这个问题,假设场景变一下,有A库和B库,在A,B库同时插入数据,有一个出现异常就会滚,怎么解决?解决方案看似很多,但是都和事务管理器有关。在探讨这个问题的时候也让我一直存在疑惑的到底是用mybatis的接口好还是原生dao好,在解决分布式事务问题,最好用编程式事务+原生dao,不然好多错根本跟踪不到,直接上代码。
public class CommonSqlsession { private SqlSession sqlSession; @Resource(name = "sqlSessionFactory") public final void setSqlSessionFactory(SqlSessionFactory sqlSessionFactory) { this.sqlSession = new SqlSessionTemplate(sqlSessionFactory); } public final SqlSession getSqlSession() { return this.sqlSession; } }
@Repository public class UserDaoImpl extends CommonSqlsession implements UserDao { public int insert(User user) throws Exception { return getSqlSession().insert("com.elin4it.ssm.mapper.mybatis.UserMapper.insert", user); } }
@Repository("seoFundDao") public class SeoFundDaoImpl extends CommonSqlsession1 implements SeoFundDao { public int insert(TbFundSeoRecord seoRecord) throws Exception { return getSqlSession().insert("com.elin4it.ssm.mapper.test.TbFundSeoRecordMapper.insert", seoRecord); } }
@Resource private DataSourceTransactionManager transactionManager; @Resource private DataSourceTransactionManager transactionManager1;
/**
* @param record
* @param user
* @return
*/
public int insertFacade1(TbFundSeoRecord record, User user) {
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = transactionManager.getTransaction(def);
TransactionStatus status1 = transactionManager1.getTransaction(def);
try {
int count1 = userDao.insert(user);
// int i = 1 / 0;
int count2 = seoFundDao.insert(record);
if (count1 > 0 && count2 > 0) {
transactionManager.commit(status);
transactionManager1.commit(status1);
} else {
throw new Exception("有一个未提交成功 count1=" + count1 + ",count2=" + count2);
}
} catch (Exception e) {
e.printStackTrace();
/**
* spring提交事务按照stack排序,先入后出
*/
transactionManager1.rollback(status1);
transactionManager.rollback(status);
}
return 0;
}
总的思路是这样的,两个事务管理器,然后从不同数据源取session,这样spring在处理事务的时候会建立一个map在ThreadLocal中,然后设置两个key,分别为ds1 : con1,ds2:con2,但是这真的是可以实现分布式事务吗?
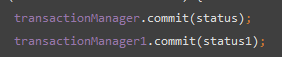

通过上面两个图,可以发现,如果在commit或者rollback的时候出问题,假设第一个事务提交成功,第二个事务提交的时候宕机了,那么就会导致第一个库中数据落地,第二个库没有数据。虽然commit很快,但是依然没法100%保证分布式事务提交。所以真的在工作中要操作多库的提交一致性还是借助JTA这种分布式框架利用2PC来解决吧或者通过业务分类,保证一致性提交的表都在一个库中。















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









