







近日在做机器学习题目的时候发现统计对于机器学习的重要性,加上老师说以后可以从计算机转统计。于是这里决定新开一个分类,专门记录关于统计的知识。希望一来能够辅助机器学习中对于数据的认识,二来也可以为读研做准备。本系列博客参照于《赤裸裸的统计学》
一.描述统计学
1.平均数和中位数:在统计中,你其实很难用一个特征去总结某件事情。比如,如何衡量这几十年美国中产阶级的经济状况?一个答案是观察这部分人群的人均收入(平均值)的变化,但是这是有缺陷的,比如你并没有考虑通货膨胀的问题。而且,你怎么找到这部分人群也是一个问题。除外,平均值还容易收异常值的影响,就像是一群普通人和比尔盖茨坐在一个酒馆里,这时候平均收入显然就不合理了。所以我们可以尝试一下“中位数”,也就是在中间的那个数。这时我们就解决了上面那个问题,并且当数据中没有什么异常值的时候,平均值和中位数值是差不多的。所以,你可以结合中位数和平均值这两个指标来研究你的数据。
2.中位数的亲戚们:我们还有四分位数,即把数据分成四部分,第一四分位数就是底部的占25%的数据,以此类推。当然,还有十分位数等等...这类数字的好处在于:它们描述了某个具体的值与其他数据进行比较的位置。你知道了相对位置,就可以忽略一些信息了,比如考试,只要知道了排名,就不用去考虑考试的难易了。
3.“绝对数值”:“绝对”的数值本身就是有意义的。是能够被理解的,比如我在NBA一场比赛中得了50分,你不需要知道比赛的情况就可以对我的表现进行评价。而如果我告诉你,我的主队排名第九,那么这就是一个相对数据。
4.标准差:用以衡量数据相对于平均值的分散程度。比如说一队运动员和几个普通家庭,这两组假设他们体重平均数是相同的,但是我们都知道普通家庭成年人的体重肯定是高于运动员的,但是由于小孩儿的存在,平均数下来了。这时如果用标准差去衡量,就会发现普通家庭的标准差远大于运动员们,这就说明,他们的体重数据是很分散的。而标准差的重要性在于,你可以分辨某数据是正常还是异常的,比如身高,假设中国人身高1.7,你身高是1.8,这不正常吗??当然不是,你的身高是在标准差范围内的。
5.正态分布:图像就是一个钟型的图,大家都知道了。这种分布可以用来描述很多现象,比如考试分数,在中间的人肯定是最多的,两端的较少。这里给大家推荐一个知乎上对于正态分布的意义的回答。简单来说,正态分布的美在于我们通过定义可以清楚地知道,有多少数据处于平均值一个标准差范围内,多少处于两个标准差范围内...
6.百分比的重要性:当我们描述数据的变化时,通常使用百分比较好。举个例子,你爸爸在2017年赚的钱比2016年少了10万,这是不是有点可怕?但万一你爸爸是马云呢?10万只是个零头了。所以,这种时候百分比则可以带来数据显示的正确的意义。当然有时候用百分比来描述数据也可以掩盖一些事情,比如,有人说今年赚的比去年多20%,但去年他压根就没赚到什么钱,所以就算增加20%,也相当于没赚......
小结:对于各种指数,它们的优点和缺点都是将复杂的信息浓缩成了一个数据。我们可以靠这些指数做出来各种排名,但是最后我们会意识到对于排名的争论永远不会停息。不过,这些指数总体来说还是给我们提供了一个较为合理的判断依据。下面看看专家对于如何看待美国中产阶级的经济状况:“我们首先需要了解通货膨胀后的工资中位数在过去几十年的变化,并且留意一下处于第25百分位数和第75百分位数人群的工资变化,因为这两部分人通常被认为是中产阶级的高收入人群和低收入人群。另外,要注意收入和工资的不同,工资是付出劳动所得,而收入是所有收入。”
二.统计数字会撒谎
1.使用统计学来描述一个复杂现象这个过程并不是精确无误的。

这两者完全有可能同时发生。比如,有很多人的大州,比如加州,纽约等,经济正在提升;而那些相对小的州经济则正在走下坡路,虽然这些小州数量很多,但是居民却比不上大州里的人。所以说总体上,人的收入还是增加了。
2.利用“平均数”和“中位数”来撒谎:


由此我们可以再次定义“中位数”和“平均数”是用来干什么的,平均数关注数据分布,而中位数更关注数据是高于还是低于中间位置。所以,当其中一个数据出现时,你就要注意了,有可能是某些人别有用心的想用数据说服你。
3.用橙子和苹果比较的把戏
举个例子:比较中国和美国的酒店价格,你的孩子会说美国的怎么那么便宜,因为他没有考虑到汇率这个问题。而就是这种看似简单的问题,充斥在生活之后,其中最容易忽略的就是通货膨胀。今天的1美元和几十年前的一美元是不同的。经济学家甚至为这个现象冠以两个术语。名义数据(没有就通货膨胀做出调整的数字),而实际数据(对通货膨胀做出调整的数字)。一个实际的例子就是好莱坞电影的票房排名,它们总是忽略通货膨胀这个因素,偏向于让新的大片看上去比之前的更成功,甚至曾有电影用卢比去算票房,要知道人民币一块接近等于10卢比了。
而其实就算我们考虑汇率、通货膨胀这些因素,也就是用苹果比较苹果,其实也是可以欺骗人的。之前提到过用百分比来表示数据能够让我们对数据有个直观的比例的感受。但是百分比也有个缺点------会夸大其辞。比如,让数据呈现“爆炸性”增长的方式就是和一个非常低的起点进行比较。
小结:总体来说,人们因为想要看到i简单的答案,即谁是第一名,导致很多实际上考虑不够周全的排名出现,这就是统计学的陷阱。
三.相关性与相关系数
1.推荐系统是怎么实现的??
淘宝是怎么给你推荐商品的呢??其实是基于“相关性”这个东西。它推荐给你的东西和你之前买过的类似,并且这些东西还是很多和你兴趣差不多的人推荐过的,这就是相关性的体现。相关性反映了两个现象之间相互关联的程度,再举个例子,在夏天温度的高低就和冰淇淋的销量是相关的。但是呢,凡事都不是那么简单的。有时也会出现和相关性违背的现象,比如有些个子矮的人就是比个子高的人重一些。如果对美国人的身高体重做随机抽样,我们可能会得到下面这个散点图:
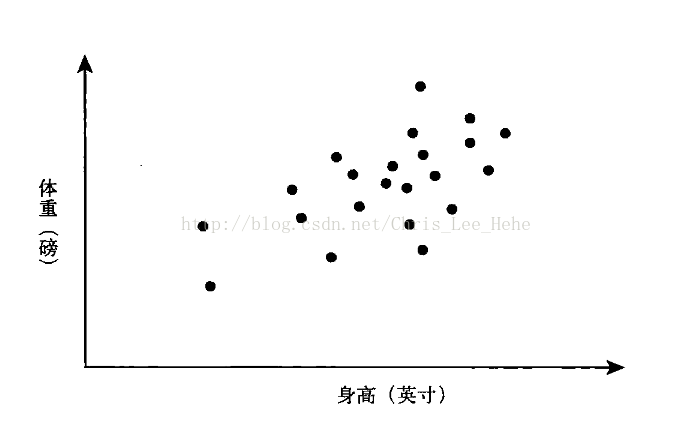
如果我们再绘制一副关于锻炼(每周运动时长)和体重的散点图,我们可能就会看到一个相反的趋势,即运动量越大体重越轻。不管怎么样,用散点图来统计真是太糟糕了。还好,相关性作为一个统计工具的魅力就在于将两个变量的关联精炼成一个描述性数据----“相关系数”。
2.相关系数
相关系数有两个优势。第一体现在数学表达上,相关系数是一个值为-1到1的常数,1表示完全相关,-1表示完全不相关。越接近1或-1,关联性就越强,如果为0,就表示没什么关系。第二个优势在于:相关系数不受变量单位的限制,身高和体重的单位不同是不影响我们去求它们相关性的。
这就是相关系数能够做的一件神奇的事。把大量无序,单位不统一的复杂数据加工成一个优雅的描述性数据。
3.实现过程?

这里要注意一点是,相关关系不等于因果关系。两个变量呈正相关或者负相关并不代表其中一个是由另外一个变量的变化引起的。举个例子,有统计数据发现家里电视机的数量和学生的高中成绩是正相关的,但是这并不说明为了让孩子成绩提高就多去买点电视;真实意义其实是家境较好的孩子往往成绩较好,而家境好的家庭电视机数量是较多的。
四.概率与期望值
to be continued...














 3989
3989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









