







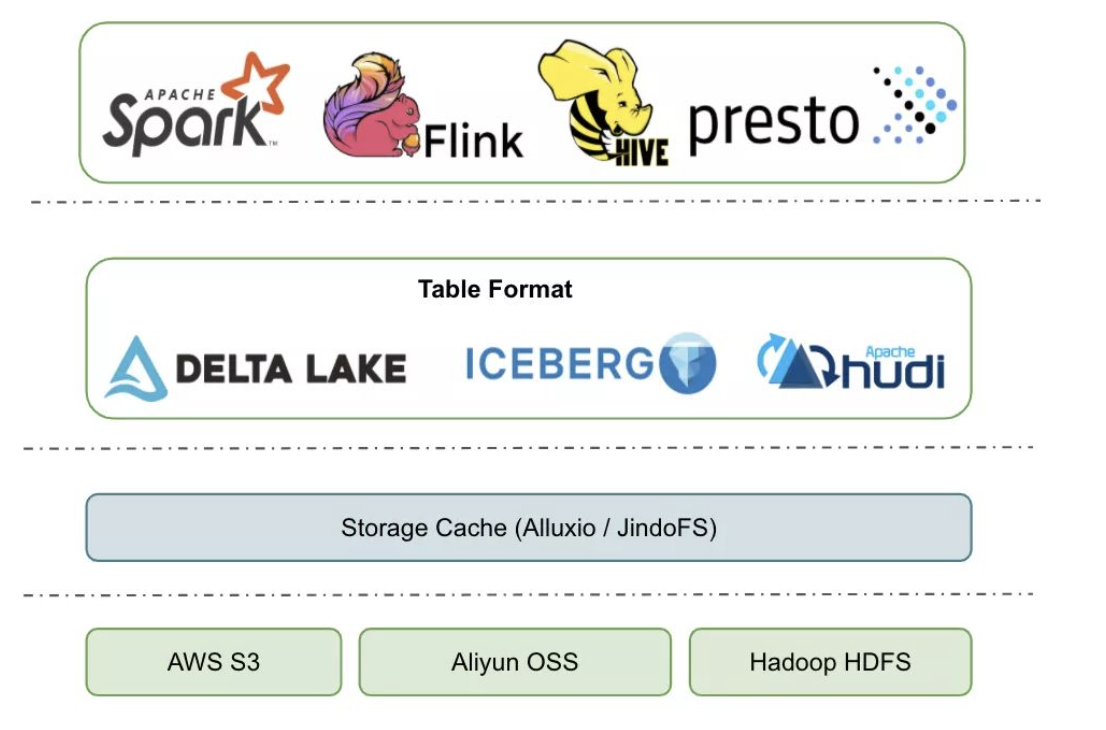
昨天介绍了Apache Hudi,今天我们来看一下Apache Iceberg,不得不说,在数据湖这一块,竞争也是很激烈啊。下面放一张数据糊在数据栈中的位置图,可以明显的看到Hudi和Iceberg处于贴身肉搏的位置:
Apache Iceberg是由 Netflix 开发并开源的、用于庞大分析数据集的开放表格式。 Iceberg在Presto和Spark中添加了使用高性能格式的表(Hudi也支持Presto和Spark集成),该格式的工作方式类似于SQL表。
官方的定义,iceberg是一种表格式(table format)。我们可以简单理解为它是基于计算层(flink、spark)和存储层(orc、parquet)的一个中间层,我们可以把它定义成一种“数据组织格式”,Iceberg将其称之为“表格式”也是表达类似的含义。
它与底层的存储格式(比如ORC、Parquet之类的列式存储格式)最大的区别是,它并不定义数据存储方式,而是定义了数据、元数据的组织方式,向上提供统一的“表”的语义。它构建在数据存储格式之上,其底层的数据存储仍然使用Parquet、ORC等进行存储。在hive建立一个iceberg格式的表。用flink或者spark写入iceberg,然后再通过其他方式来读取这个表,比如spark、flink、presto等。
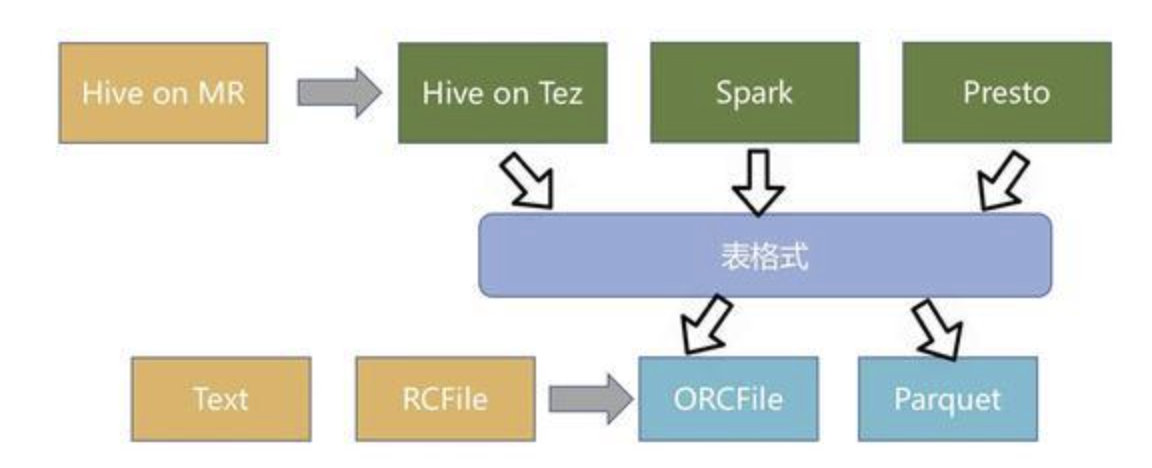
Iceberg的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。
Iceberg 优势
- 增量读取处理能力:Iceberg支持通过流式方式读取增量数据,支持Structured Streaming以及Flink table Source;
- 支持事务(ACID),上游数据写入即可见,不影响当前数据处理任务,简化ETL;提供upsert和merge into能力,可以极大地缩小数据入库延迟;
- 可扩展的元数据,快照隔离以及对于文件列表的所有修改都是原子操作;
- 同时支持流批处理、支持多种存储格式和灵活的文件组织:提供了基于流式的增量计算模型和基于批处理的全量表计算模型。批处理和流任务可以使用相同的存储模型,数据不再孤立;Iceberg支持隐藏分区和分区进化,方便业务进行数据分区策略更新。支持Parquet、Avro以及ORC等存储格式。
- 支持多种计算引擎,优秀的内核抽象使之不绑定特定的计算引擎,目前Iceberg支持的计算引擎有Spark、Flink、Presto以及Hive。
- 目前相比于 Hudi、Delta Lake,Iceberg 在国内的关注度较少,这主要是由于其主要开发团队在技术推广和运营上面的工作偏少,而且 Iceberg 的开发者多为海外开发者,但是现在已经有越来越多的大公司加入到了 Iceberg 的贡献中,包括 Netflix、Apple、Adobe、Expedia 等国外大厂,也包括腾讯、阿里、网易等国内公司。
















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











