







 Go语言中的rune类型是int32的别名,用于处理UTF-8编码的字符串,特别是中文字符。在计算字符串长度和截取时,rune起到了关键作用。例如,当包含中文的字符串使用len()函数时,返回的不是字符数,而是字节数。通过将字符串转换为rune切片,可以正确计算字符数。在截取字符串时,不使用rune可能会导致乱码,而转换后可以正确截取并显示中文内容。了解rune类型对于处理多语言字符串至关重要。
Go语言中的rune类型是int32的别名,用于处理UTF-8编码的字符串,特别是中文字符。在计算字符串长度和截取时,rune起到了关键作用。例如,当包含中文的字符串使用len()函数时,返回的不是字符数,而是字节数。通过将字符串转换为rune切片,可以正确计算字符数。在截取字符串时,不使用rune可能会导致乱码,而转换后可以正确截取并显示中文内容。了解rune类型对于处理多语言字符串至关重要。
rune类型是Go语言的一种特殊数字类型,在builtin/builtin.go文件中,它的定义为:type rune = int32;官方对它的解释是:rune是类型int32的别名,在所有方面都等价于它,用来区分字符值跟整数值。由于Go语言中采用的是统一的UTF-8编码,英文字母在底层占1个字节,特殊字符和中文汉字则占用1~3个字节,在Go语言中文的计数和截取并不如其他语言(比如Python)那么容易,所以Go提供了rune类型来处理中文的计数和分割问题,以支持国际化多语言。
下面我们通过一个例子来感受一下Go中使用rune的两个场景。
- 统计带中文字符串的长度
package main
import "fmt"
func main() {
s := "阿福Chris"
fmt.Println(len(s)) //输出11
fmt.Println(len([]rune(s))) //输出7
}
从上面的例子可以看出,我们使用len函数取带有中文的字符串长度时,获得的并不是真正的字符个数,当然如果全都是英文是不存在这个问题的;在上面例子中,由于有中文,就影响到了对长度的正确衡量,此时,我们使用rune进行转换,便可以获得正确的长度。
- 截取中文字符串
package main
import "fmt"
func main() {
s := "阿福Chris"
fmt.Println(s[:2]) //输出乱码�
fmt.Println(string([]rune(s)[:2])) //输出阿福
}
从上面的例子可以看出,与长度计算一样,如果不采用rune,想取“阿福”这两个字,会从底层直接取前两个字符串,这样取出来的必然是乱码;第二个打印中,采用了rune来取前两个汉字就可以正常获得结果了(注意这里面使用了string是对汉字和编码进行了转换)。
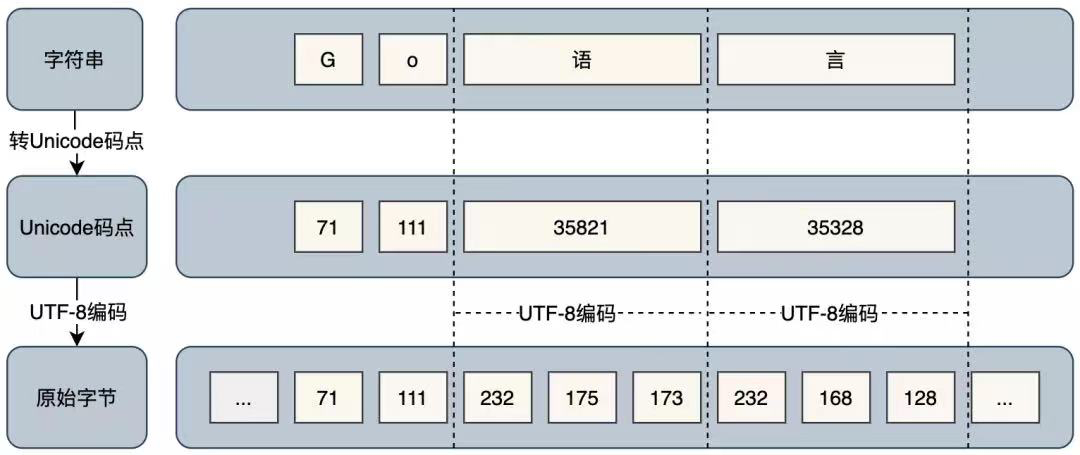
最后附上一张“字符串”、“Unicode码点”和“原始字节”的转换表,方便大家理解为什么rune类型可以更好的完成中文的处理。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











