






深度学习的威力在于其能够逐层地学习原始数据的多种表达方式。每一层都以前一层的表达特征为基础,抽取出更加抽象,更加适合复杂的特征,然后做一些分类等任务。
堆叠自编码器(Stacked Autoencoder,SAE)实际上就是做这样的事情,如前面的自编码器,稀疏自编码器和降噪自编码器都是单个自编码器,它们通过虚构一个 x -> h -> x 的三层网络,能过学习出一种特征变化 h = f(wx+b) 。实际上,当训练结束后,输出层已经没有什么意义了,我们一般将其去掉,即将自编码器表示为:

之前之所以将自编码器模型表示为3层的神经网络,那是因为训练的需要,我们将原始数据作为假想的目标输出,以此构建监督误差来训练整个网络。等训练结束后,输出层就可以去掉了,因为我们只关心的是从 x 到 h 的变换。
接下来的思路就很自然了,我们已经得到特征表达 h ,那么我们可不可以将 h 再作为原始信息,训练一个新的自编码器,得到新的特征表达呢?当软可以,而且这就是所谓的堆叠自编码器(Stacked Autoencoder,SAE)。Stacked 就是逐层堆叠的意思,这个跟“栈”有点像。当把多个自编码器 Stack 起来之后,这个系统看起来就像这样:

这样就把自编码器改成了深度结构了,即 learning multiple levels of representation and abstraction (Hinton, Bengio, LeCun, 2015)。需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行的。比如说我们要训练一个 n -> m -> k 结构的网络,实际上我们是先训练网络 n -> m -> n ,得到 n -> m 的变换,然后再训练 m -> k -> m 网络,得到 m -> k 的变换。最终堆叠成 SAE ,即为 n -> m -> k 的结果,整个过程就像一层层往上面盖房子,这就是大名鼎鼎的 layer-wise unsuperwised pre-training (逐层非监督预训练)。
接下来我们来看一个具体的例子,假设你想要训练一个包含两个隐藏层的堆叠自编码器,用来训练 MNIST 手写数字分类。
首先,你需要用原始输入 x(k) 训练第一个稀疏自编码器中,它能够学习得到原始输入的一阶特征表示 h(1)(k),如下图所示:
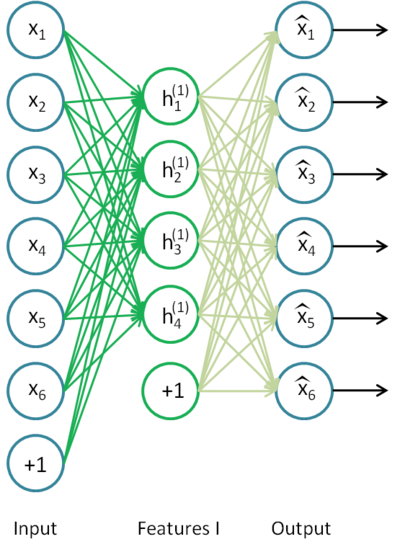
接着,你需要把原始数据输入到上述训练好的稀疏自编码器中,对于每一个输入 x(k) ,都可以得到它对应的一阶特征表示 h(1)(k) 。然后你再用这些一阶特征作为另一个稀疏自编码器的输入,使用它们来学习二阶特征 h(2)(k) ,如下图:
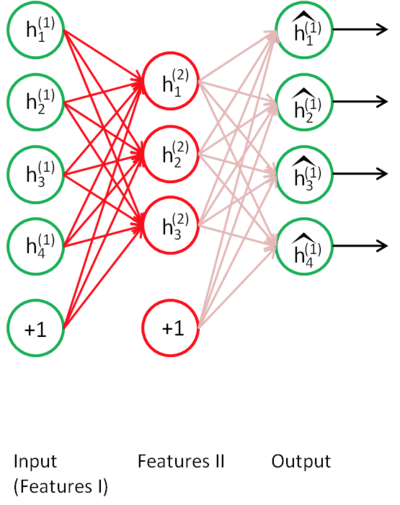
同样,再把一阶特征输入到刚训练好的第二层稀疏自编码器中,得到每个 h(1)(k) 对应的二阶特征激活值 h(2)(k) 。接下来,你可以把这些二阶特征作为 softmax 分类器的输入,训练得到一个能将二阶特征映射到数字标签的模型。如下图:
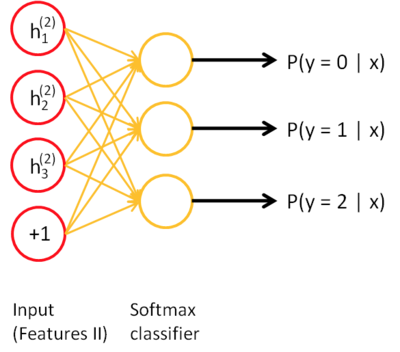
最终,你可以将这三层结合起来构建一个包含两个隐藏层和一个最终 softmax 分类器层的堆叠自编码网络,这个网络能够如你所愿地对 MNIST 数据集进行分类。最终模型如下图:
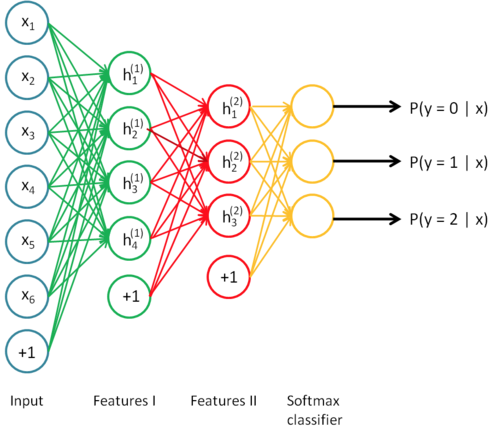
实验代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import input_data
N_INPUT = 28*28
N_HIDDEN_1 = 1000
N_OUTPUT_1 = N_INPUT
N_HIDDEN_2 = 1500
N_OUTPUT_2 = N_HIDDEN_1
N_OUTPUT = 10
BATCH_SIZE = 16 0
EPOCHES = 10
RHO = .1
BETA = tf.constant(3.0)
LAMBDA = tf.constant(.0001)
w_model_one_init = np.sqrt(6. / (N_INPUT + N_HIDDEN_1))
model_one_weights = {
"hidden": tf.Variable(tf.random_uniform([N_INPUT, N_HIDDEN_1], minval = -w_model_one_init, maxval = w_model_one_init)),
"out": tf.Variable(tf.random_uniform([N_HIDDEN_1, N_OUTPUT_1], minval = -w_model_one_init, maxval = w_model_one_init))
}
model_one_bias = {
"hidden": tf.Variable(tf.random_uniform([N_HIDDEN_1], minval = -w_model_one_init, maxval = w_model_one_init)),
"out": tf.Variable(tf.random_uniform([N_OUTPUT_1], minval = -w_model_one_init, maxval = w_model_one_init))
}
w_model_two_init = np.sqrt(6. / (N_HIDDEN_1 + N_HIDDEN_2))
model_two_weights = {
"hidden": tf.Variable(tf.random_uniform([N_HIDDEN_1, N_HIDDEN_2], minval = -w_model_two_init, maxval = w_model_two_init)),
"out": tf.Variable(tf.random_uniform([N_HIDDEN_2, N_OUTPUT_2], minval = -w_model_two_init, maxval = w_model_two_init))
}
model_two_bias = {
"hidden": tf.Variable(tf.random_uniform([N_HIDDEN_2], minval = -w_model_two_init, maxval = w_model_two_init)),
"out": tf.Variable(tf.random_uniform([N_OUTPUT_2], minval = -w_model_two_init, maxval = w_model_two_init))
}
w_model_init = np.sqrt(6. / (N_HIDDEN_2 + N_OUTPUT))
model_weights = {
"out": tf.Variable(tf.random_uniform([N_HIDDEN_2, N_OUTPUT], minval = -w_model_init, maxval = w_model_init))
}
model_bias = {
"out": tf.Variable(tf.random_uniform([N_OUTPUT], minval = -w_model_init, maxval = w_model_init))
}
model_one_X = tf.placeholder("float", [None, N_INPUT])
model_two_X = tf.placeholder("float", [None, N_HIDDEN_1])
Y = tf.placeholder("float", [None, N_OUTPUT])
def model_one(X):
hidden = tf.sigmoid(tf.add(tf.matmul(X, model_one_weights["hidden"]), model_one_bias["hidden"]))
out = tf.sigmoid(tf.add(tf.matmul(hidden, model_one_weights["out"]), model_one_bias["out"]))
return [hidden, out]
def model_two(X):
hidden = tf.sigmoid(tf.add(tf.matmul(X, model_two_weights["hidden"]), model_two_bias["hidden"]))
out = tf.sigmoid(tf.add(tf.matmul(hidden, model_two_weights["out"]), model_two_bias["out"]))
return [hidden, out]
def model(X):
hidden_1 = tf.sigmoid(tf.add(tf.matmul(X, model_one_weights["hidden"]), model_one_bias["hidden"]))
hidden_2 = tf.sigmoid(tf.add(tf.matmul(hidden_1, model_two_weights["hidden"]), model_two_bias["hidden"]))
out = tf.add(tf.matmul(hidden_2, model_weights["out"]), model_bias["out"])
return out
def KLD(p, q):
invrho = tf.sub(tf.constant(1.), p)
invrhohat = tf.sub(tf.constant(1.), q)
addrho = tf.add(tf.mul(p, tf.log(tf.div(p, q))), tf.mul(invrho, tf.log(tf.div(invrho, invrhohat))))
return tf.reduce_sum(addrho)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
# model one
model_one_hidden, model_one_out = model_one(model_one_X)
# loss
model_one_cost_J = tf.reduce_sum(tf.pow(tf.sub(model_one_out, model_one_X), 2))
# cost sparse
model_one_rho_hat = tf.div(tf.reduce_sum(model_one_hidden), N_HIDDEN_1)
model_one_cost_sparse = tf.mul(BETA, KLD(RHO, model_one_rho_hat))
# cost reg
model_one_cost_reg = tf.mul(LAMBDA, tf.add(tf.nn.l2_loss(model_one_weights["hidden"]), tf.nn.l2_loss(model_one_weights["out"])))
# cost function
model_one_cost = tf.add(tf.add(model_one_cost_J, model_one_cost_reg), model_one_cost_sparse)
train_op_1 = tf.train.AdamOptimizer().minimize(model_one_cost)
# =======================================================================================
# model two
model_two_hidden, model_two_out = model_two(model_two_X)
# loss
model_two_cost_J = tf.reduce_sum(tf.pow(tf.sub(model_two_out, model_two_X), 2))
# cost sparse
model_two_rho_hat = tf.div(tf.reduce_sum(model_two_hidden), N_HIDDEN_2)
model_two_cost_sparse = tf.mul(BETA, KLD(RHO, model_two_rho_hat))
# cost reg
model_two_cost_reg = tf.mul(LAMBDA, tf.add(tf.nn.l2_loss(model_two_weights["hidden"]), tf.nn.l2_loss(model_two_weights["out"])))
# cost function
model_two_cost = tf.add(tf.add(model_two_cost_J, model_two_cost_reg), model_two_cost_sparse)
train_op_2 = tf.train.AdamOptimizer().minimize(model_two_cost)
# =======================================================================================
# final model
model_out = model(model_one_X)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(model_out, Y))
train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
predict_op = tf.argmax(model_out, 1)
# =======================================================================================
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
for i in xrange(EPOCHES):
for start, end in zip(range(0, len(trX), BATCH_SIZE), range(BATCH_SIZE, len(trX), BATCH_SIZE)):
input_ = trX[start:end]
sess.run(train_op_1, feed_dict = {model_one_X: input_})
print 'finish model one ...'
for i in xrange(EPOCHES):
for start, end in zip(range(0, len(trX), BATCH_SIZE), range(BATCH_SIZE, len(trX), BATCH_SIZE)):
input_ = trX[start:end]
input_ = sess.run(tf.sigmoid(tf.add(tf.matmul(input_, model_one_weights["hidden"]), model_one_bias["hidden"])))
sess.run(train_op_2, feed_dict = {model_two_X: input_})
print 'finish model two ...'
for i in xrange(EPOCHES):
for start, end in zip(range(0, len(trX), BATCH_SIZE), range(BATCH_SIZE, len(trX), BATCH_SIZE)):
input_ = trX[start:end]
sess.run(train_op, feed_dict = {model_one_X: input_, Y: trY[start:end]})
print i, np.mean(np.argmax(teY, axis = 1) == sess.run(predict_op, feed_dict = {model_one_X: teX, Y: teY}))
print 'finish model ...'
print np.mean(np.argmax(teY, axis = 1) == sess.run(predict_op, feed_dict = {model_one_X: teX, Y: teY}))Reference:















 5449
5449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









