






1.原理解析:
随机选取k(预设类别数)个样本作为起始中心点,将其余样本归入相似度最高中心点所在簇(cluster),再确立当前簇中样本坐标的均值为新的中心点,一次循环迭代下去,直至所有样本所属类别不再变动. 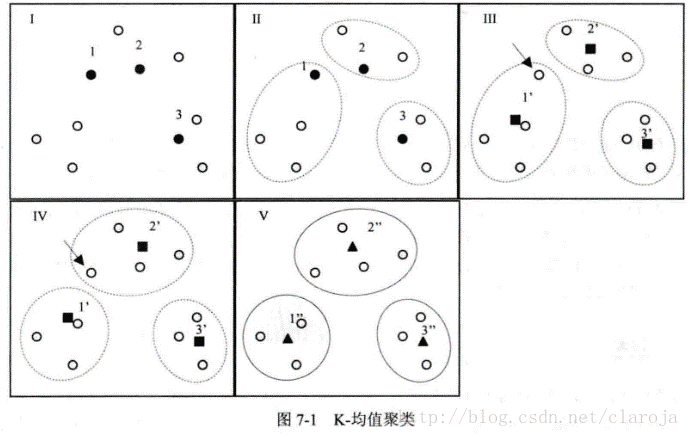
2.在R语言中的应用
在k均值聚类中我们应用到了stats包(R语言内置包)中的kmeans函数。
kmeans(x,centers,iter.max = 10,nstart = 1,algorithm = c(“Hartigan-Wong”,”Loyd”,”For-gy”,”MacQueen”))
3.以iris数据集为例进行判别分析
1)应用模型并查看模型的相应参数
fit_km=kmeans(iris[,-5],center=3)
fit_km[1:length(fit_km)] 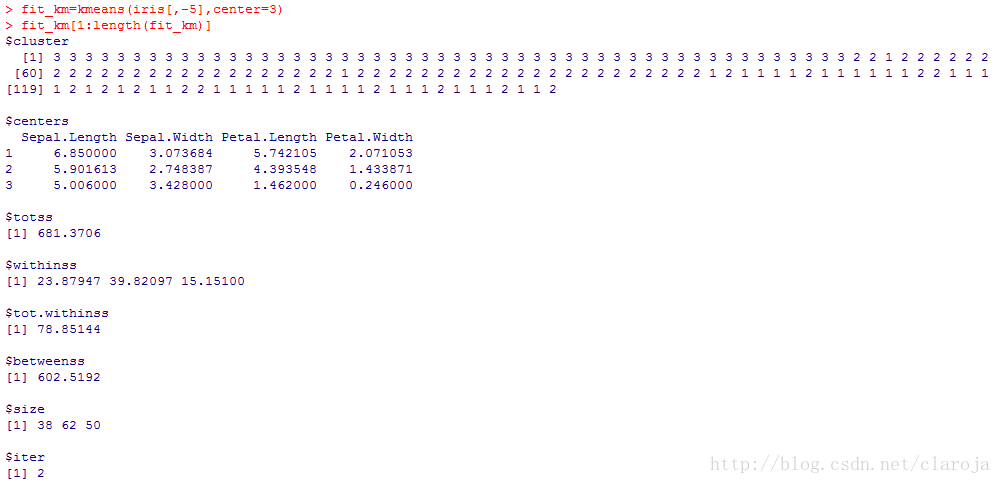
转载于:https://my.oschina.net/u/3473376/blog/895280














 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









