






1.距离判别原理分析
根据待判定样本与已知类别样本之间的距离远近做出判断.根据已知类别样本信息建立距离判别函数式,再将各待判定样本的属性数据逐一代入式中计算,得到距离值,再根据此将样本判入距离值最小的类别的样本簇.
K最近邻算法则是距离判别法中使用最为广泛的,他的思路是如果 一个样本在特征空间中的K个最相似/最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别.
图中3个实心表示样本点,其周围分布着若干分别用圆形,三角形,正方形空心点表示出的三种已知类别的样本点.现在我们取K=5,即圈出与待分类样本点最相近的5个样本点,然后查看他们的类别.这5个点中属于哪个类别的样本多,该未知样本就属于哪个类别.易得未知样本(从左到右)依次属于圆形,三角形,正方形.
K最近邻方法进行判别时,由于其主要依靠周围有限邻近样本的信息,而不是靠判别类域的方法来确定所属类别,因此对于类域的交叉或重叠较多的待份样本集来说,该方法较其他方法更为合适. 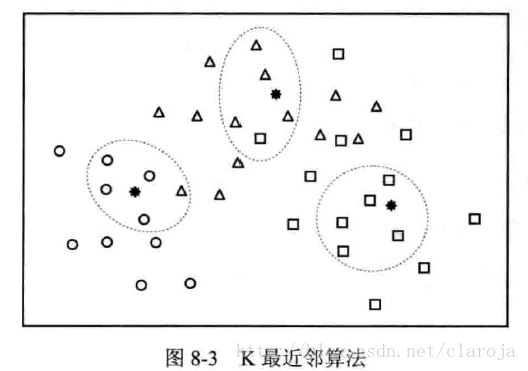
2.在R语言中的应用
在K最近邻(K-Nearest Neighbor,KNN)算法中我们主要用到了class包里面的 knn(train,test,cl,k=1,1=0,prob=FALSE,use.all=TRUE)函数。
而在有权重的k最近邻(Weighted K-NearestNeighbor,KKNN)我们主要用到了kknn包里的 kknn(formula=formula(train),train,test,na.action=na.omit(),k=7,distance=2,kernel=”optimal”,ykernel=NU
R语言分类算法之距离判别(Distance Discrimination)
最新推荐文章于 2023-05-04 16:02:38 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5240
5240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









