






java中外部锁实现就用到了自旋锁这个概念,之前看jdk的concurrent包源码的时候,对这部分实现一直是无法透彻的理解。正所谓”外行看热闹,内行看门道“。虽然代码按行看都能看懂,但是连在一起不知道是为什么这么做。只能对Doug Lea大神佩服的十体投地。这么复杂精巧的代码是怎么想出来的?
后面看了《多处理器编程的艺术》这本书时,对自旋的概念开始有了一点概念。要想了解并应用好自旋锁,不仅仅是对相关算法的了解,还需要一些些底层硬件的知识哦。不过不用担心,需要的底层硬件知识不是很多(万幸),所以在详细讲解各个自旋锁之前,需要对这些一点点的硬件知识了解一下,正好以此作为开篇。这个系列大部分内容和代码都来自于《多处理器编程的艺术》一书,算是一个读书笔记吧。
1、处理器和线程
一个多处理器是由多个硬件处理器组成。其中每一个处理器都能执行一个顺序程序。处理器提取和执行一条指令的时间叫做时钟周期,这也是我们用来衡量程序执行性能的基本时间单位。处理器可以执行线程一段时间,然后不去管这个线程有没有执行完,转而去执行另一个线程。这个切换过程就是我们熟悉的上下文切换。处理器会因为各种原因从调度中删除一个线程去执行其他的线程。在多处理器系统中,当线程从一个处理器调度中被删除后,可能重新在另一个处理器上执行。
2、互连线
互连线是cpu和内存以及cpu和cpu之间进行通信的一种媒介。有两种基本的连接模式:SMP(对称duochuli)和
NUMA(非一致性内存访问)。

在SMP系统结构中,处理器和存储器通过总线来通信。处理器和存储器都有用来负责发送和监听总线上广播信息的总线控制单元。SMP系统结构非常普遍,因为它们比较容易构建。但是对于处理器数量较多的系统来说,这种结构不利于扩展,因为最终总线会成为瓶颈。

NUMA中,一系列节点通过点对点网络连接,就像一个小的局域网。每个节点包含一个或多个处理器和一个存储器。一个节点的存储器对于其他节点来说是可以访问的。所有节点的本地存储器组成了一个所有处理器共享的全局存储器。NUMA名字叫做非一致性内存访问,意思就是处理器访问自己的本地存储要比访问其他处理器的存储要快。访问内存的速度并不是一致的。NUMA结构显然比较复杂,需要的协议也更复杂。但是对于处理器数量多的系统来说扩展性更好。
可以在SMP和NUMA之间找一个平衡。每个节点用SMP来构造,而连接节点则采用NUMA结构。当然对于我们程序员来说,我们只要知道一点:互连线是由处理器共享的有限资源。如果一个处理器占用了较多的互连线资源,其他的处理器必然会被延时执行。这一点非常重要。
3、主存
主存可以看成一个由所有处理器共享的由字组成的一个大数组。我们通过特定的地址来访问主存对应的区域。通常字长是32字节或者64字节。字长为32字节的系统主存地址是32位的,字长为64字节的系统主存地址是64位的。也就是我们通常说的32位机和64位机。处理器通过连接线给主存发送包含目的地址的信息,用来获取主存中对应目的地址的值。或者发送包含目的地址以及一个新的数据,用于向主存对应的地址中中写入新值,当新值被写入后,主存会发送确认信息。我们可以看到,处理器对主存的读取和写入都会占用互连线资源。
4、高速缓存
处理器对主存的一次访问可能会花费数百个时钟周期,如果处理器频繁的对主存进行读取操作意味着处理器将会花费大量的时间等待主存响应请求。另外,处理器访问主存会占用互连线资源,造成其他的处理器的延迟。所以高速缓存就出现了,这是一个介于处理器和主存之间的一个小容量存储器。高速缓存的读取速度比主存要快的多。当处理器要读取一个值时,首先会到高速缓存中去寻找,如果存在,处理器就不用再去访问比较慢的主存了,否则处理器必须还要到主存中去取值。我们把读取的值在高速缓存中存在这种情况叫做”cache 命中“,不存在这种情况叫做”cache缺失“。理解”cache命中“和”cache缺失“对设计高性能的自旋锁可是非常必要的哦。
5、一致性
当一个处理器读或写了被另一个处理器装入高速缓存的主存地址时,将发生共享。例如处理器A读写了主存的一个值,并装入自己的高速缓存。处理器B也在随后读取了同一个值,此时会发生共享(或者叫内存争用)。如果两个处理器共享同一个主存地址,一个处理器修改了改地址的值,另一个处理器的高速缓存中保存的值将会被作废,以确保不会读到过期值。这个问题就是缓存的一致性问题。
有一种最常用的叫做MESI的协议用于解决缓存一致性问题,下面来详细了解一下。
首先对缓存块的状态进行命名:
- modified (修改):缓存块中的数据已经被修改,需要最终写回到主存中去。其他处理器不能缓存该数据。
- exclusive(独占):缓存块中的数据只被一个处理器未被修改。其他处理器可以缓存该数据。
- shared(共享):缓存快中的数据被多个处理器共享且未被修改。其他处理器可以缓存该数据
- invalid(无效):缓存块中的数据无效。
我们用例子来解释一下MESI协议:
(1)刚开始,处理器A读取主存中的数据a并储存在高速缓存中。此时A的缓存块对应的状态是Exclusive。这个不用解释。

(2)然后处理器B也读取了相同的数据a也缓存到了自己的高速缓存中。此时A和B共享主存中的同一个数据a。所以它们的缓存块状态都是shared。
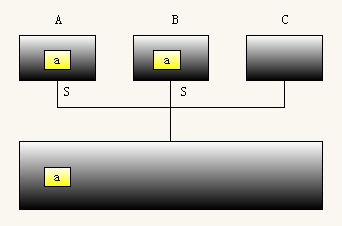
(3)接着,处理器B修改了数据a为b,但是只是修改了缓存块中的数据,并没有同步到主存中去。此时B的缓存块状态是modified,同时A的缓存块状态变为了invalid。B在修改的同时回向其他处理器广播,所以A修改了自己的缓存块状态。
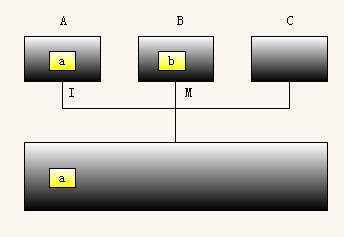
(4)如果A此时要从读取a时,会广播请求。B收到请求将修改后的值同时发送给处理器A和主存,并将A和B的缓存块状态变成和谐的shared状态。

其实这个MESI协议还是比较好理解的。
6、自旋
如果处理器不断的测试内存中的某个字,并等待另一个处理器处理它,则称该处理器正在自旋。举例来说,内存中存在一个布尔变量a,初始值为false。A处理器不断地去读取它,知道a被另一个处理器设置成true为止。我们称处理器A的行为(不断的读取a,并测试a是不是为true)叫做自旋。其实也就是名字唬人罢了。
对于没有高速缓存的SMP系统结构来说,自旋是一种非常糟糕的想法。因为,每次自旋都是处理器到主存中去读取值。每次的读取操作都会消耗总线资源(还记得上面SMP的结构图吗),会直接影响到其他处理器的推进。
对于无高速缓存的NUMA系统结构来说(NUMA也可以带高速缓存的)。如果自旋的地址位于本地存储器中,这个是可以接受的。否则也是糟糕的想法。还好目前不带高速缓存的多处理器系统结构很少见。
对于有高速缓存的SMP和NUMA系统结构来说,自旋仅消耗非常少的资源。因为处理器第一次读取肯会直接到主存中去读(cache缺失),但后面自旋过程中,只要数据没有改变,处理器都会从自己的高速缓存中去读取数据(cache命中)。这种我们称为”本地自旋“。一旦高速缓存中的数据被改变,立刻会产生一个cache缺失(缓存块状态为invalid),既然数据已经被改变,自旋也会随之停止。














 2930
2930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









