






Spark 2.0的大多数代码比Spark 1.6的快5-10倍(所谓的大多数代码指的是hashjoin,filter等等,但是全局的排序在2.0版本并没有做太多的努力),如果在Spark 1.6比较耗CPU的话,在2.0上有很大的改进
其实特别大的改进指的就是数据规模特别大且特别耗CPU的情况下,性能得到了很大的提升
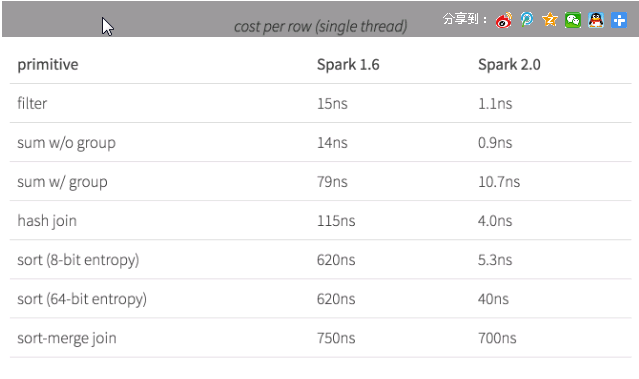
Spark 2.0采用了whole stage code generation
在Spark 2.0中,如果物理计划中有*,则都会启用 whole-stage code generation的机制,Range,Filter等等都有这个*
其实从这个名字可以看出来,是针对一个stage的,Exchange does not have whole-stage code generation because it is sending data accross the data(Shuffle)
从这里可以看出Spark 2.0的精髓所在:
Spark 1.6 一个Stage 内部之间的多个算子是通过Iterator的next next 来实现的(多个Function)
而Spark 2.0是通过一个Function 来完成的
Spark 2.0中之所以能比1.6快,是因为:
1.减少了虚函数的调用,极大地减少了CPU无用的指令的消耗(不需要通过next,next的调用)
2.数据直接放在寄存器中,至少提升了一个数量级的提升速度(例如我们写一个Spark SQL,只是翻译成了普通的循环,不需要方法调用,数据可以直接放在寄存器中)
3.现在的CPU等硬件架构对基本的条件语句,循环语句等进行了极大的优化,并且可以使用硬件加速
4.对于复杂的数据操作,采用Vectorzation的方式,列的方式读写数据(一次next就是整列的数据),也就是一行其实是原来的一列
优点:擅长CPU密集型的计算
弱点:对IO没有进行太多优化
归纳总结:1.Spark 2.0比Spark 1.6.x快,什么代码会快?适用于什么情况?
2.Spark 采用了什么策略,是因为什么会快,优点和弱点?
















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









