






一、什么是事务
它提供一种“要么什么都不做,要么做全部”(All or Nothing)的机制。
1. 事务ACID
事务具有的ACID特性:
- 原子性(Atomicity):
不可分割的意思,事务的原子性的含义是,一个事务的所有操作被捆绑/包装成一个整体,所有操作要么全部执行,要么都不执行,不会看到中间状态。
回滚实际上是一个比较抽象的概念,大多数DB在实现事务时,事务操作是在数据快照上进行的,并不修改实际数据,先预演一遍所有要执行的操作,如果出错则不会被提交,所以很自然的支持回滚。而在其它支持简单事务的DBMS中,不会在快照上更新,而是直接操作实际数据。 - 一致性(Consistence):
事务的原子性确保不会破坏数据的一致性,如果事务成功提交,事务内的操作按照事先编排的方式执行,结果的数据状态具有一致性。如果事务任何一个中间步骤出错,整个事务回滚并将数据恢复到原来的状态,数据状态仍然具有一致性。所以,事务只会将数据状态从一个一致性状态转换到另一个一致性状态; - 隔离性(Isolation):
从事务外部来看,事务的一致性实现了数据在两个一致性状态之间的转换,但是从事务内部来看,组成事务的各个操作是按照一定的逻辑顺序执行的,所以数据具有位于两个一致性状态的“中间状态”。但是这种中间状态被隔离于事务内部,对于事务外部不可见,是隔离的。即一个事务在提交之前,它对数据的操作对事务外部不可见; - 持久性(Durability):即事务一旦提交,对数据的更改是永久性的。
事务的一致性决定了一个系统设计和实现的复杂度。事务可以按不同程度分为:
● 强一致性:读操作可以立即读到提交的更新操作;
● 弱一致性:提交的更新操作,不一定立即会被读操作读到,会存在一个不一致窗口;
● 最终一致性:弱一致性的特例,最终所有的事务都会读到之前事务提交的最新值;
● 单调一致性:如果一个进程已经读到一个值,那么后续不会读到更早的值;
● 会话一致性:在客户端和服务端交互的会话中,读操作可以读到该会话中更新操作后的最新值;
2. 事务的隔离级别
事务隔离级别越严格,并发副作用越小,但代价也越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与并发是矛盾的。
隔离性描述的是并发事务之间互相影响的程度,这其实非常重要。事务隔离级别从低到高有:
● 读未提交(Read Uncommitted):最低的隔离级别,事务会读到其他事务未提交的数据;
● 读已提交(Read Committed):这种级别下的事务读不到其他事务未提交的数据,可以解决脏读问题,但仍然存在同一个事务中出现不可重复读问题;
● 可重复读(Repeated Read):同一个事务中,同一份数据的读取结果总是一致的;
● 串行化(Serialization):事务串行化执行,以保证事务之间没有任何干扰。它隔离级别最高,但牺牲了系统的并发性。
其中,区分事务隔离级别是为了权衡事务并发问题的影响范围的:
- 脏读(dirty read):一个事务读到了另一个未提交事务的更新数据,形成脏读;
- 不可重复读(unrepeated read):同一事务中,对于同一份数据前后读取结果不一致;
- 幻读(phantom read):同一事务中,同一个查询返回结果不一致;
- 丢失更新(lost update):分为回滚覆盖丢失和提交覆盖丢失,指的是回滚/提交一个事务时,把其它已提交事务的更新数据一并覆盖了。因为写操作依赖于事务内读到的数据。
如下所示:
| 事务隔离级别 | 回滚覆盖 | 脏读 | 不可重复读 | 提交覆盖 | 幻读 |
|---|---|---|---|---|---|
| 读未提交 | x | 可能发生 | 可能发生 | 可能发生 | 可能发生 |
| 读已提交 | x | x | 可能发生 | 可能发生 | 可能发生 |
| 可重复读 | x | x | x | x | 可能发生 |
| 串行化 | x | x | x | x | x |
我们一般将数据库的隔离级别设为Read Commmitted,解决脏读了并具有较好的并发性能,但不保证幻读和不可重复读还有数据更新丢失的并发问题。 “不可重复读”和“幻读”出现的原因都是事务并发更新对象导致的,它们的区别在于:不可重复读的重点在于修改数据,在一个事务中前后两次读取的结果不一致,形成不可重复读(即不能读到相同的数据内容);幻读的重点在于新增或删除数据,同样的条件同一个对象,两次读出来的记录数不一样,形成幻读。一般我们通过MVCC来避免“不可重复读”,增加间隙锁来防止幻读(比如MySQL的GAP LOCK)。
二、事务并发控制
并发控制是指,如何在多个进程同时操作时,保证事务的强一致性同时最大程度的并发。
列举一下常见的事务并发场景和策略选择:
- 读多于写
这是我们通常见到的,读操作的比例远大于写操作,如果使用悲观锁机制,读写互斥则会有大量的读操作被阻塞,影响并发性能。一般我们会使用乐观锁或MVCC,以保持稳定的读并发能力。 - 读写频繁,且对读的响应速度有要求
有一类系统比如股票交易机,更新特别频繁,而且对读的响应速度要求很高。我们一般会根据实际应用情况,来采取MVCC+乐观锁或MVCC+悲观锁的策略,来保证并发读、稳定写的能力。 - 写冲突频繁
这其实是经常见到的,系统中写操作的比例很高,且冲突频繁,这个时候其实我们需要评估写失败的成本有多高。在MVCC机制下,两个冲突的任务其中一个要retry,如果retry代价很低,比如我们可以把第1次执行的有效结果缓存下来,以减少retry时的耗时;如果retry代价很高,银行月末清账、海量报表统计这种需要花数小时甚至数天,则应该采取悲观锁机制避免retry。
更多精简的,当我们应对并发场景、选择并发策略时,可以从以下几个维度思考:读写频次,冲突频率,响应时间,重试代价。
1. 什么是MVCC
MVCC(Multi-Version Concurrency Control,多版本并发控制),一种用来实现无锁事务语义的并发控制方法。
1)优点是:并发时我们将锁分为读/写锁,读会阻塞写、写也会阻塞读,效率都不会太高,在粒度较大时尤其突出。而MVCC机制提供了一种保证读不阻塞但细粒度阻塞写的机制,读写不阻塞,高并发访问的场景。
2)缺点是:一行数据拥有多个版本,废旧的死版本无法轻松删除,因为索引没有可见性信息,维护开销呈指数膨胀;
3)一句话概括,MVCC就是使用读写分离的方式,维护同一份数据保留的多个版本,来实现并发控制;
MVCC一般在数据库管理系统(DBMS,提供DDL和DML语言操作)中实现对数据库的并发访问、在编程语言中实现事务内存的一种并发控制方法。它使用一种与加锁不同的手段,每个读者在某个瞬间看到的是数据库的一个快照,写操作造成的变化在它完成之前(或数据库事务提交之前),对于读者而言是不可见的。
当一个MVCC数据库需要更新一条数据记录的时候,它并不是直接用新数据覆盖旧数据,而是增加新版本的数据并将旧数据标记为过时(obsolete)。这样一个对象就会有多个版本的数据,但只有一个是最新的,它能够让读者在read过程中不受影响,即使这条数据半路上被人修改、删除了。这种多版本控制、读写分离快照隔离的方式,避免了读写并发时写操作在内存和磁盘存储结构造成的空洞开销,但代价是需要周期性整理(sweep through)那些过时的、废弃的旧数据。
MVCC提供了时间点一致性视图(point in time),并发控制下的读事务一般使用时间戳(S)或者递增的事务ID(T)去标记当前读取的这个数据的版本,读写分离不加锁,读写并存时写操作根据当前数据状态,创新一个新版本,而并发的读则依旧访问旧版本的数据(即保证一个读事务永远不会被阻塞)。
对象P存有多个版本,每个版本会有一个读时间戳(RTS)和写时间戳(WTS),假设有事务T读对象P的最新版本,该版本早于事务Ti的读时间戳RTS(Ti)。然后事务Ti对对象P执行写操作,此时如果有其它事务Tk同时对P操作(读/写),则有RTS(Ti)<RTS(Tk)时(写之前要先读),Ti对P的写操作才能完成。也就是说,写事务在创建新版本之前要等待前面的事务都完成了,它的事务才能提交成功,因为写之前的读必须要读到最新版本的数据。换句话说,如果某个事务Ti在对P进行写操作时,存在一个拥有较早时间戳的其它事务的话,那么此时事务Ti会将退出并重新开始,否则事务Ti就创建P的一个新版本,并设置该新版本的时间戳。
显而易见的,MVCC明显的缺点是存储多个版本数据的冗余开销,并且还将体现在同一份数据多个版本的维护上。但同时,优点是读操作永远不会被阻塞,提供了一个很好的读并发能力,这对我们通常以读操作为主的数据库来说非常重要。
1.1. 并发控制的区别
很多人都以为MVCC是OCC的一个变种,但它们其实不一样,这在上面其实已经说清楚了,但我仍觉得有必要再提一提。
- 悲观并发控制(PCC):对事务竞争持悲观态度,它基于悲观锁的锁机制,保证当前操作最大程度的独占性。但它的缺点是DBMS的大量开销,尤其是对长事务而言更是如此;无法避免产生死锁的问题。悲观锁能防止丢失更新和不可重复读的问题;
- 乐观并发控制(OCC):对事务竞争持更加宽松的乐观态度,它基于乐观锁的锁机制。它一般使用版本检查,这通常包含了基于version和基于timestamp两种实现;
- 多版本并发控制(MVCC):基于快照版本隔离机制,它实现了非阻塞的读操作,写操作也只是锁定必要的行,适用于对读并发要求比较高的场景;
MVCC是多版本控制,同一份数据多个版本,基于版本隔离机制,事务开启时看到哪个版本就是哪个版本,写冲突时回退,它最大的好处是读写不冲突,这个特性很大程度上提升了读的性能。乐观锁是基于一个前提假设,先修改然后提交时check,遇到读写冲突时需要回退。而悲观锁是独占的,无论读写事务先加锁,且读写阻塞,所以悲观锁需要回退时不是因为写冲突时,而是因为死锁或表间约束。
2. MVCC的实现
大多事务型数据库系统基于并发性能考虑,都实现了MVCC,但不同的数据库各自的实现机制不尽相同。MVCC保证可以不阻塞地读到一致的数据,但是MVCC并没有对实现细节做约束。我们简单了解下:
- Postgres:它是严格无锁,对写操作也是乐观并发控制。在表中存储同一份数据的多个版本,每次写都是创建新版本而回避更新。在事务提交时,按版本号检查当前事务提交的数据是否存在写冲突,有则快速失败,抛出错误返回给用户并回滚事务;
- Innodb:对读无锁、对写上锁的悲观并发控制。这意味着,Innodb通过悲观锁回避了更新时的写冲突。它在更新数据时给每份数据上行级锁,同时将旧数据写入undo log日志;表和 undo log 中行数据都记录着事务ID,在检索时,只读取来自当前已提交的事务的行数据;
MVCC使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,而是把数据库的行锁与行的多个版本结合起来,只需要很小的开销就可以实现非锁定读,从而提高数据库系统的并发性能。
我们以MySQL为例。
2.1. MySQL基本情况
MySQL几个比较常用的存储引擎:
- MyISAM:这是mysql最早提供的。这种引擎又可以分为静态MyISAM、动态MyISAM和压缩MyISAM这三种,但不管是何种MyISAM表,都不支持事务、行级锁和外键约束。
它的优点是,在筛选大量数据时非常有用,而且支持并发插入的特性,MyISAM存储引擎特别适合管理邮件或服务器日志数据; - Merge:它是MyISAM类型的一种变种,是将几个相同的MyISAM表合并为一个虚表。它在某些情况下非常有用,比如日志和数据仓库。
- InnoDB:一个健壮的标准型事务存储引擎,并且引入了行级锁定和外键约束。MySQL支持外键的存储引擎只有InnoDB。Innodb特点在于支持并发与表间引用。
它适合处理以下几个场合:更新密集型的表,自动灾备恢复。 - Memory:它突出的特点是速度,最快的响应时间,因为这种类型的数据表只存在于内存中,而且它使用散列索引。一般应用于临时表。
- Archive:一种特殊的存储引擎,只支持最基本的插入和查询两种功能,而且在MySQL 5.5以前不支持索引。但Archive存储引擎拥有很好的压缩机制,它使用zlib压缩库,在记录被请求时会实时压缩,所以它常被当做仓库使用,应用于日志记录和聚合分析等方面。
MySQL的锁机制比较简单,它大致可以归纳为3种锁:
- 表级锁(table-level locking):
开销小,加锁快;锁定粒度高,发生锁冲突的概率高,并发度低; - 行级锁(row-level locking):
开销大,加锁慢;锁定粒度小,发生锁冲突的概率低,并发度高; - 页级锁(page-level locking):
开销和加锁时间在表锁和行锁之间,锁定粒度也界于表锁和行锁之间,并发度一般;
表级锁更适用于以查询为主,少量按索引条件更新数据的应用;行级锁更适用于大量按索引条件并发更新不同数据,同时又并发查询的应用。页级锁则较少用到。MySQL锁机制最显著的特点是不同的存储引擎支持不同的锁机制。比如MyISAM和Memory存储引擎采用的是表级锁;InnoDB存储引擎默认情况下采用行级锁,也支持表级锁。
MySQL表级锁有两种模式:表共享锁(Table Read Lock)和表独占写锁(Table Write Lock)。MySQL行级锁也分为两种类型:共享锁(S)和排他锁(X)。
实际上,InnoDB行级锁是通过索引上的索引项来实现的,这一点与Oracle不同,后者是通过在数据中对相应数据行加锁来实现的。InnoDB这种行级锁实现特点意味者:只有通过索引条件检索数据,InnoDB才会使用行级锁,否则,InnoDB将使用表级锁!我们经常把行级锁用在写操作而不是读操作,因为成本太高。
那么InnoDB的 间隙锁 机制(GAP LOCK)是什么样的呢?当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据的索引项加锁。而对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁:锁定索引记录间隙,确保索引记录的间隙不变。显而易见的,它可以有效防止幻读的发生!
InnoDB使用间隙锁的目的,除了一方面是为了防止幻读,以满足相关隔离级别的要求,另一方面也是为了满足其恢复机制的需要。但它也是有弊端的,在使用范围条件检索并锁定记录时,InnoDB这种间隙锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。
2.2. Innodb中的MVCC
了解Innodb的行结构对于理解Innodb MVCC的实现具有重要意义。
Innodb存储的最基本row中包含一些额外的存储信息:
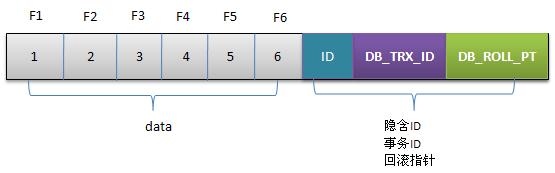
- 6字节的DATA_TRX_ID:它标记了最近更新这行记录的transactionID,每处理一个事务,该值+1;
- 7字节的DATA_ROLL_PTR:它指向当前记录项的rollback segment的undo log日志,找之前版本的数据就是通过这个指针;
- 6字节的DB_ROW_ID:用于索引当中,当Innodb自动产生聚集索引时,聚集索引会包含该值;
- DELETE BIT:用于标识该记录是否被删除。
那么一个具体的Update事务执行过程是这样的:
- 用排他锁锁定该行;
- 记录redo log;
- 记录undo log;
- 修改当前行的值,写transactionID;
- 回滚指针指向undo log中旧数据的记录;
更新前建立undo log,根据各种策略读取时非阻塞就是MVCC,undo log中的行就是MVCC中的多版本,这个可能与我们所理解的MVCC有较大的出入:每行都有版本号,保存时根据时间戳决定是否成功。但Innodb的实现方式是:
- 事务以排他锁的方式修改原始数据
- 把修改前的数据存于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
区别在于,当修改数据时是否要排他锁定?其实Innodb的实现算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,而不是多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据,特别是事务交叉修改时,理想的MVCC就显的无能为力了。比如,同一个T1中修改P1成功、修改P2失败,那么此时回滚P1,如果执行的是理想的MVCC,P1未被锁定,其数据可能又被T2修改,如果T1回滚P1成功,那么就无法保证事务T2的一致性。
※ 附录:
参考:
- 事务隔离级别:http://uule.iteye.com/blog/1109647
- 数据库事务:http://www.jianshu.com/p/71a79d838443
- 事务并发处理:http://blog.csdn.net/kenight/article/details/51322453
- 事务并发解决方案:http://www.jianshu.com/p/71a79d838443
- 乐观锁与MVCC的区别:https://www.zhihu.com/question/27876575
- MVCC基础:http://www.cnblogs.com/YFYkuner/p/5178684.html
- MVCC机制与原理:http://blogread.cn/it/article/5969
- MySQL中的MVCC:http://blog.csdn.net/chen77716/article/details/6742128















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









