






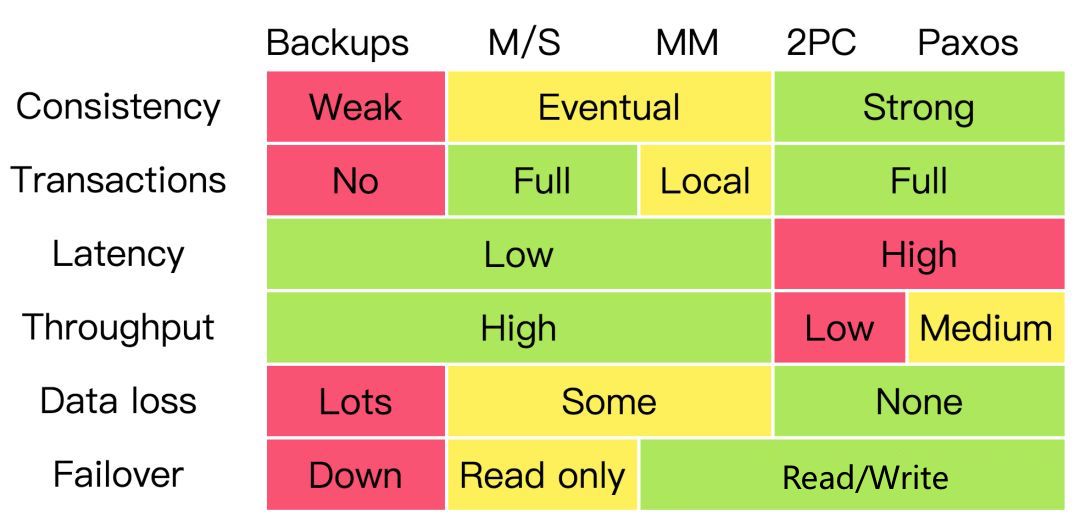
前面讲了那么多的一致性理论和算法,那么我们必须要了解一下不同一致性算法下的事务、性能、错误的对比关系:
在分布式系统中,比如不同的服务进程操作不同的数据或副本,服务进程间必须要保证事务数据的一致性。所以今天,让我们来回顾一下,事务中的数据一致性。
一、事务基础
1.1. 事务的隔离级别
- 读未提交
- 读已提交
- 可重复读
- 串行化
而对应的事务并发问题主要就是这些 :
- 丢失更新-回滚覆盖
- 脏读:一个事务读到了另一个未提交的数据。
- 不可重复读:同一事务同一份数据,前后读取结果不一致,也叫“模糊读”。
- 丢失更新-提交覆盖
- 幻读:同一事务同一个查询,前后返回结果数不一致。
它们的关系是这样的:
| 事务隔离级别 | 回滚覆盖 | 脏读 | 不可重复读 | 提交覆盖 | 幻读 |
|---|---|---|---|---|---|
| 读未提交 | x | 可能发生 | 可能发生 | 可能发生 | 可能发生 |
| 读已提交 | x | x | 可能发生 | 可能发生 | 可能发生 |
| 可重复读 | x | x | x | x | 可能发生 |
| 串行化 | x | x | x | x | x |
“不可重复读”和“幻读”很像,但针对点不同。前者针对的是update,关注的是前后读取的结果不一致,即不能读到相同的数据内容;后者针对的是delete或insert,关注的是同样的条件同一对象,前后读取到的条目数不一样。
从上往下,事务隔离级别越高,并发副作用越小,代价也越大,因为事务隔离实质上是使事务在一定程度上“串行化”,显然与并发是矛盾的。所以我们大多数将数据库DBMS设置为可重复读,来解决了脏读和不可重复读,并具有较好的并发性,或者设置为读已提交比如MySQL,通过MVCC来防止“不可重复读”、增加间隙锁来防止幻读。
1.2. 事务的传播性
- propagation_requierd: 支持当前事务,如果当前没有事务则新建一个事务;
- propagation_supports: 支持当前事务,如果当前没有事务则以非事务方式执行;
- propagation_mandatory:支持当前事务,如果当前没有事务则抛出异常;
- propagation_required_new:不支持当前事务,如果当前存在事务则把当前事务挂起,如果没有事务则新建;
- propagation_not_supported:不支持当前事务,如果当前存在事务则把当前事务挂起,否则以非事务方式执行;
- propagation_never:不支持当前事务,如果当前存在事务则抛出异常,否则以非事务方式执行;
- propagation_nested:如果当前存在事务则在嵌套事务内执行,如果当前没有事务则执行与propagation_required类似的操作
Spring默认的事务传播行为是propagation_required,它适合于绝大多数的情况。假设ServiveX#methodX()都工作在事务环境下(即都被Spring事务增强了),程序中存在如下的调用链:Service1#method1()->Service2#method2()->Service3#method3(),那么这3个服务类的3个方法通过Spring的事务传播机制都工作在同一个事务中。
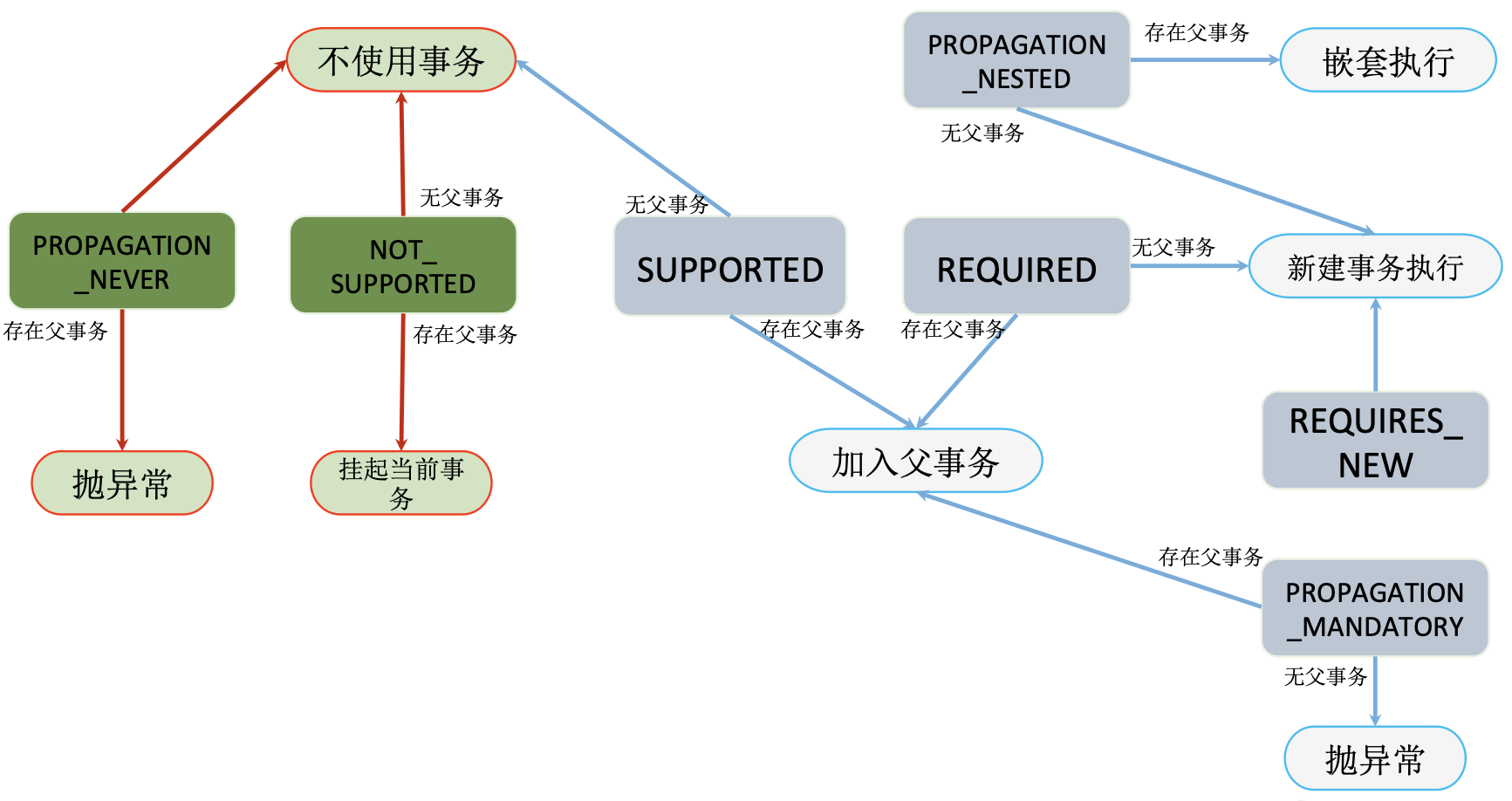
这七种事务传播性中,“propagation_nested”是Spring提供的一个特殊变量。它要求事务管理器使用JDBC 3.0 Savepoint API提供嵌套事务的行为,即开启一个嵌套事务。对Spring而言,这个内部事务其实是拥有自己的隔离范围和自己的锁。当内部事务开始执行时,它将记录一个保存点(save point),外部事务将被挂起;当内部事务失败,回滚到此保存点;内部事务结束,外部事务唤起。
1.3. 事务的一致性
常见的比如强一致性 ACID和弱一致性 BASE:
1.3.1. ACID
- A(原子性)
- C(一致性):
- 单调读一致性(访问者:读-读):如果已经读到一个值,那么后续不会读到更早的值。
- 单调写一致性(副本顺序:写-写):所有的副本以相同的顺序执行所有的写操作。
- 会话一致性(会话:写-读):提交更新操作的用户在同一个会话里能读取到该数据的最新值。
- 读写一致性(访问者:写-读):用户对某个数据进行写操作之后,能读取其最新的值,而其他用户不能保证。
- 因果一致性(多个访问者之间:写-读读):相互独立的A、B、C三个进程对数据进行操作,A进行写后通知B,B进行读,那么能读取到A写之后的数据值,但是由于A没有通知C,那么系统将不保证C一定能够读取到A写之后的数据值。
- I(隔离性)
- D(持久性)
1.3.2. BASE
- BA(基本可用性):出故障时,允许损失一部分可用性来保证整体可用;
- S(柔性状态):允许存在中间状态且不影响系统整体可用;
- E(最终一致性):经过一定延时,最终达到一致的状态;
BASE其实是为了兼顾可用性、效率的需要,放宽了一致性的要求(并不是完全放弃了ACID),只要“基本可用,最终一致”就可以了。简单来说,“事务完成后的一致性严格遵循,事务中的一致性适当放宽”就是BASE思想。我们把严格遵循ACID、强一致性的事务称为刚性事务,而基于BASE思想实现的事务则称为柔性事务。
弱一致性和强一致性是相反的,最终一致性其实是弱一致性的特殊情况。
二、分布式事务
分布式场景下的事务,常见的难题是:每一个机器节点都能明确的知道自己执行的事务成功 or 失败,但是却无法知道其他分布式节点的事务执行情况。当一个事务要跨越多个分布式节点的时候,为了保证该事务满足事务一致性的要求,一定要引入一个协调者,而其他的节点被称为参与者。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务进行提交。这就是常见的分布式事务了。
所以,在大体上,分布式事务都会有一个活动管理器或者中心协调者,负责活动登记和业务编排,并记录日志来做恢复,只是有些是隐式的。比如Saga或本地消息表中的活动发起者。
2.1. 刚性事务
2.1.1. DTP型
分布式事务有两层:一个是涉及对多个数据库资源的访问,控制在单一服务的内部;一个是涉及对多个服务的访问,是跨越多个服务的。后者很复杂,要解决比如对多资源的协调、事务的跨服务传播等,但本质都是为了保证ACID特性。
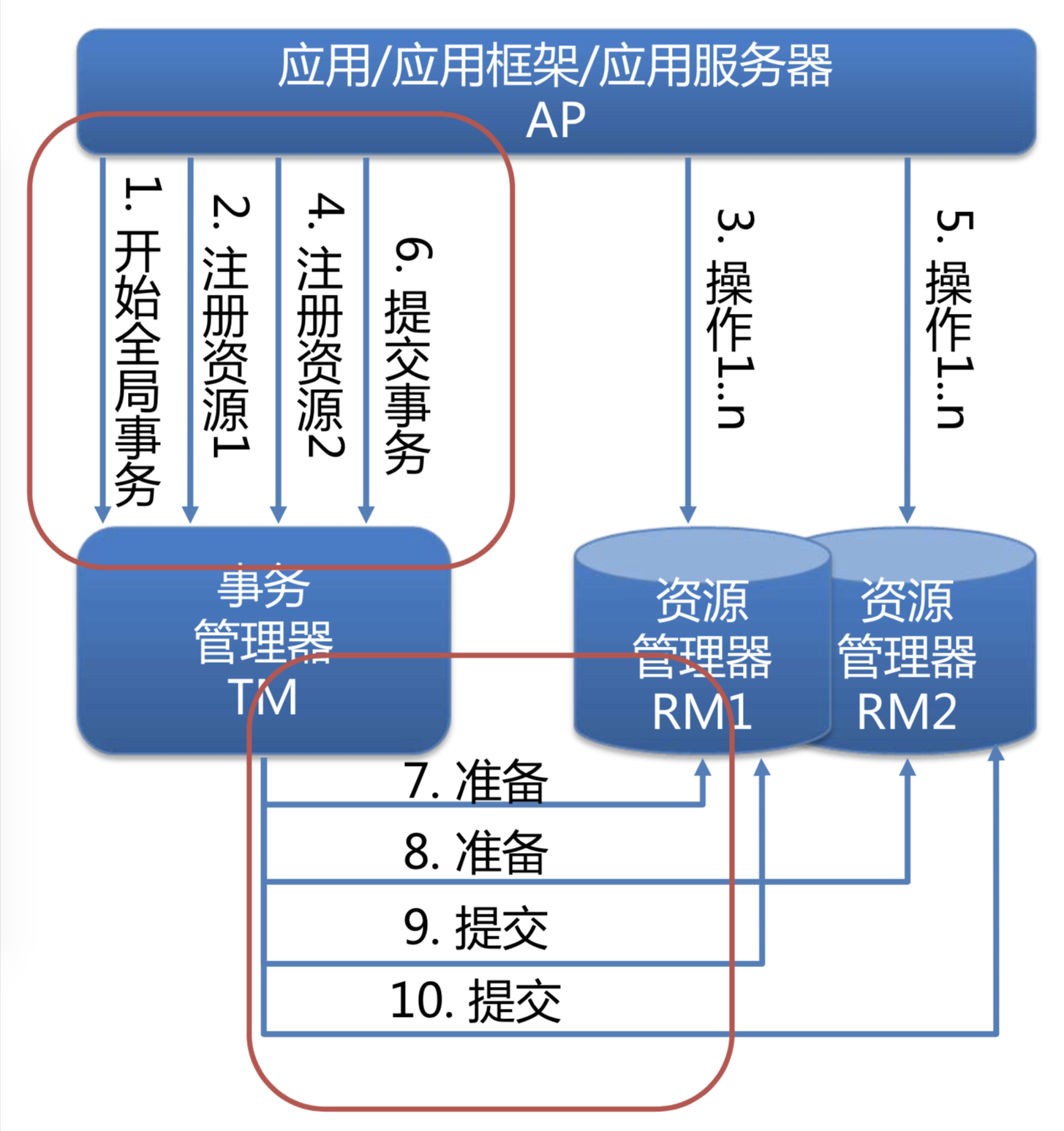
最经典的分布式事务模型就是DTP型了,它包含一个全局事务管理器TM和多个资源管理器RM,以及涉及到的TX协议(描述了APP与TM之间的接口)和XA协议(描述了TM与RM之间的接口)。
DTP型的实现:
a)APP向TM申请开始一个全局事务;
b)APP向TM注册/登记操作的RM,TM通过XA接口通知对应的RM开启子事务;
c)APP操作RM管理的资源,根据执行情况通知TM提交或回滚全局事务,然后TM通过XA接口告知RM提交或回滚子事务;
c')先预提交,根据反馈决定正式提交或回滚。
d)RM操作完毕,全局事务结束;
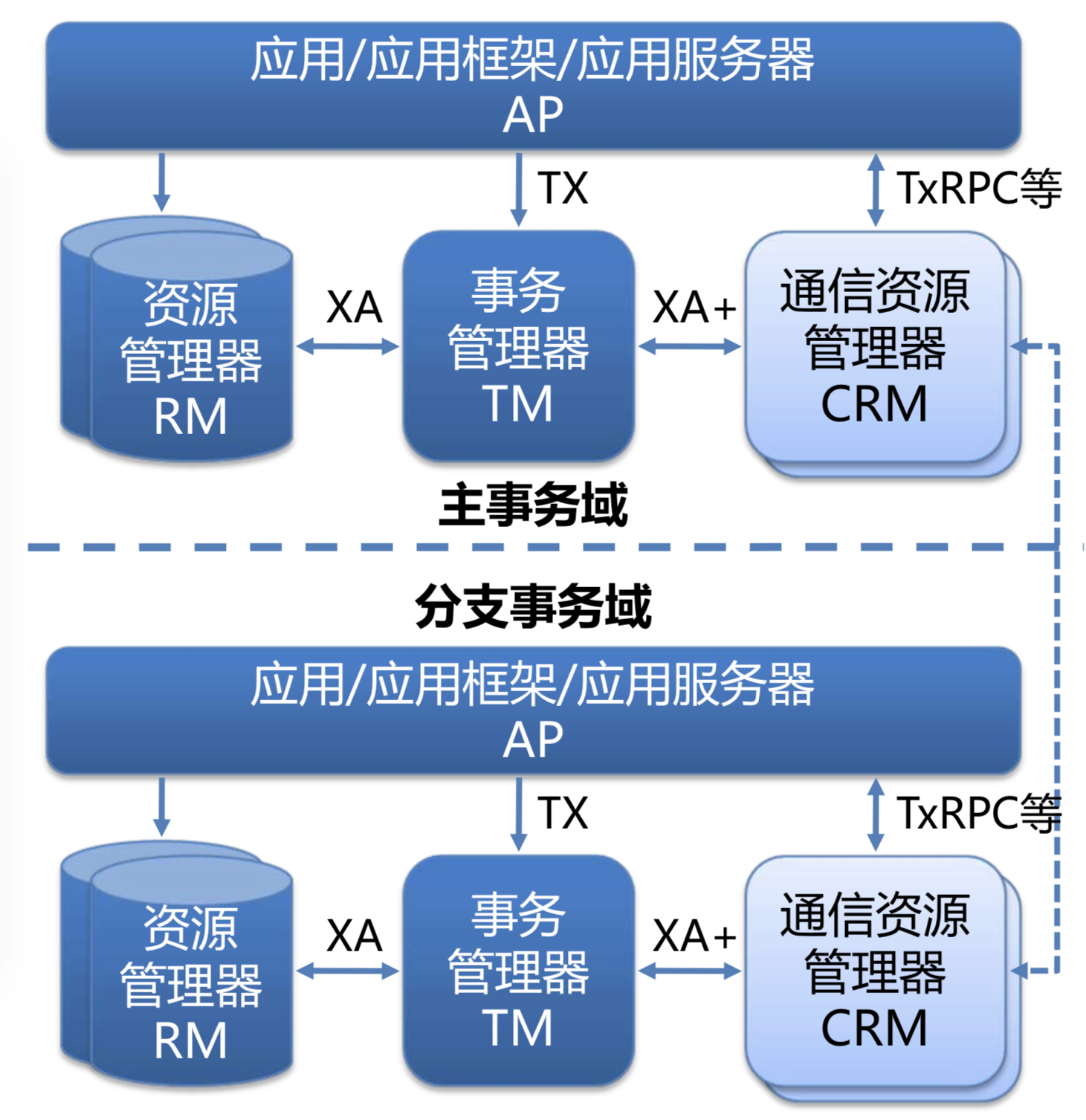
基于DTP实现的分布式事务的隔离性,是由每个RM本地事务的隔离性来保证的。在具体实现上,又分为普通DTP和跨域DTP的:
- 普通DTP:
- 跨域DTP:
DTP型通常实现在数据库资源层,ACID严格,强一致。但DTP型也有很多缺点:
- 更高的协议成本,效率低下
- 更脆弱,故障点多
- 故障影响大,恢复困难
2.1.2. 2PC协议
2PC,即所谓的“两阶段提交”:
- prepare阶段:完成资源操作,出现问题则回滚;
- commit阶段:完成事务提交,不允许出错;
两阶段事务的关键是在准备阶段,在这个阶段所有参与者必须完成约束检查,达成关于分布式事务一致性的共识。然后在第二阶段,根据之前达成的共识,完成提交或者取消操作。
提交事务的过程中需要在很多个资源节点之间进行协调,而且每个节点对锁资源的释放必须等到事务最终提交的时候。因此,两阶段事务提交会耗费很长的时间。长时间执行的事务意味着锁资源发生冲突的概率增加。当事务的并发量积累到一定数量的时候,很可能出现事务积压甚至死锁,这将压垮系统的性能和吞吐量。
2PC的缺点很明显:
- 对业务有侵入性,多个资源需要提供准备和提交两个接口;
- 吞吐不高(因为要互斥,事务执行过程中资源都是被锁定的);
- 存在全局锁问题(造成阻塞与死锁倾向);
- 高昂的协议成本,导致只适用于短事务,不适合较严苛的分布式场景比如高并发高性能;
- 牺牲了一定可用性(CAP模型中典型的C+A,不能容忍网络分区);
2.1.3. 3PC协议
我们假设在一个2PC通信的事务网络中发生机器故障,会有下面几种情况:
- 协调者挂了,参与者没挂:只需要找到一个新的协调者,来询问所有参与者最后那条事务的执行情况,就可以知道是应该YES or NO了。所以,这种情况不会导致数据不一致;
- 参与者挂了,协调者没挂:这又可以分为两种情况:
- 挂了之后没有恢复,不会导致数据一致性的问题;
- 挂了之后又恢复了,询问协调者应该怎么做,协调者比对自己的事务执行记录和该参与者的事务执行记录,来告诉他怎么做,也能保证数据的一致性了;
- 参与者挂了,协调者也挂了:这种情况下,新的协调者被选举出来之后,由于不知道参与者在挂之前的执行情况,有可能参与者在挂之前已经执行了事务,但没有人知道他执行了,这就会造成数据不一致了;
为了避免第三种情况,就有了2PC的改进版本——3PC:
- CanCommit:询问参与者是否可以执行事务操作,参与者返回YES;
- PreCommit:执行事务操作,参与者返回YES;
- DoCommit:执行commit或者rollback;
简单来说,就是通过将prepare阶段的事务询问和事务执行拆分开,新的协调者不用等其他节点宕机恢复就能决定事务状态。再拿上面第三种情况来说明:当新的协调者发现存活节点中有的节点状态是preCommit或doCommit,那么说明宕机之前所有节点都对"可以提交"达成了共识,协调者就执行commit操作,否则执行rollback操作。而宕机恢复后的参与者通过询问协调者,就能和其他节点保持数据一致性了。
也就是说,3PC协议解决了2PC协议在参与者、协调者都宕机的情况下事务状态不可知的问题,也降低了全局锁范围。但无论2PC或3PC,均无法彻底解决分布式数据一致性问题,脑裂问题依然存在:参与者收到PreCommit请求后网络分区,等待超时后,不管参与者是继续commit或rollback,因为没有协调者参与协调,始终会有数据不一致的情况。
2.2. 柔性事务
一般来说,服务之间的一致性比服务内部的一致性要更加容易弱化,XA协议、DTP模型在资源层面上实现了通用分布式事务的一致性保证,而当上升到服务层面,服务与服务之间也已实现了功能的划分和逻辑的解耦,也就更容易弱化一致性。也因此,在SOA或微服务架构下更提倡BASE思想的最终一致性,比如TCC模式、Saga模式。即通过业务逻辑将互斥操作从资源层面上移到业务层面,放宽了一致性要求,借助本地事务来实现最终一致性并保证系统的吞吐。
简单的说,柔性事务就是利用可以利用的业务弹性,业务上对于事务过程中不一致的容忍度,让事务最终一致的方法。比如转账,A账户上的余额扣减、B账户上的余额增加,刚性事务是要求这两个操作同时发生,这在分布式环境下是很难保证的,而柔性事务则允许先减少A账户上的余额,在业务能容忍的时间范围内,最终把B账户的余额给加上去。
2.2.1. 补偿型
简单而言,补偿型事务的模式上是这样的:
- do: 执行业务,业务处理结果外部可见;
- compensate:业务补偿,补偿操作要考虑是否可重入、是否幂等;
补偿型事务的实现:
- 主业务服务作为发起者,负责发起并完成整个业务活动;
- 若干从业务服务作为参与者,提供业务补偿操作;
- 业务活动管理器作为协调者,负责控制业务活动的一致性,登记业务活动中的操作并在业务活动取消时调用补偿操作;
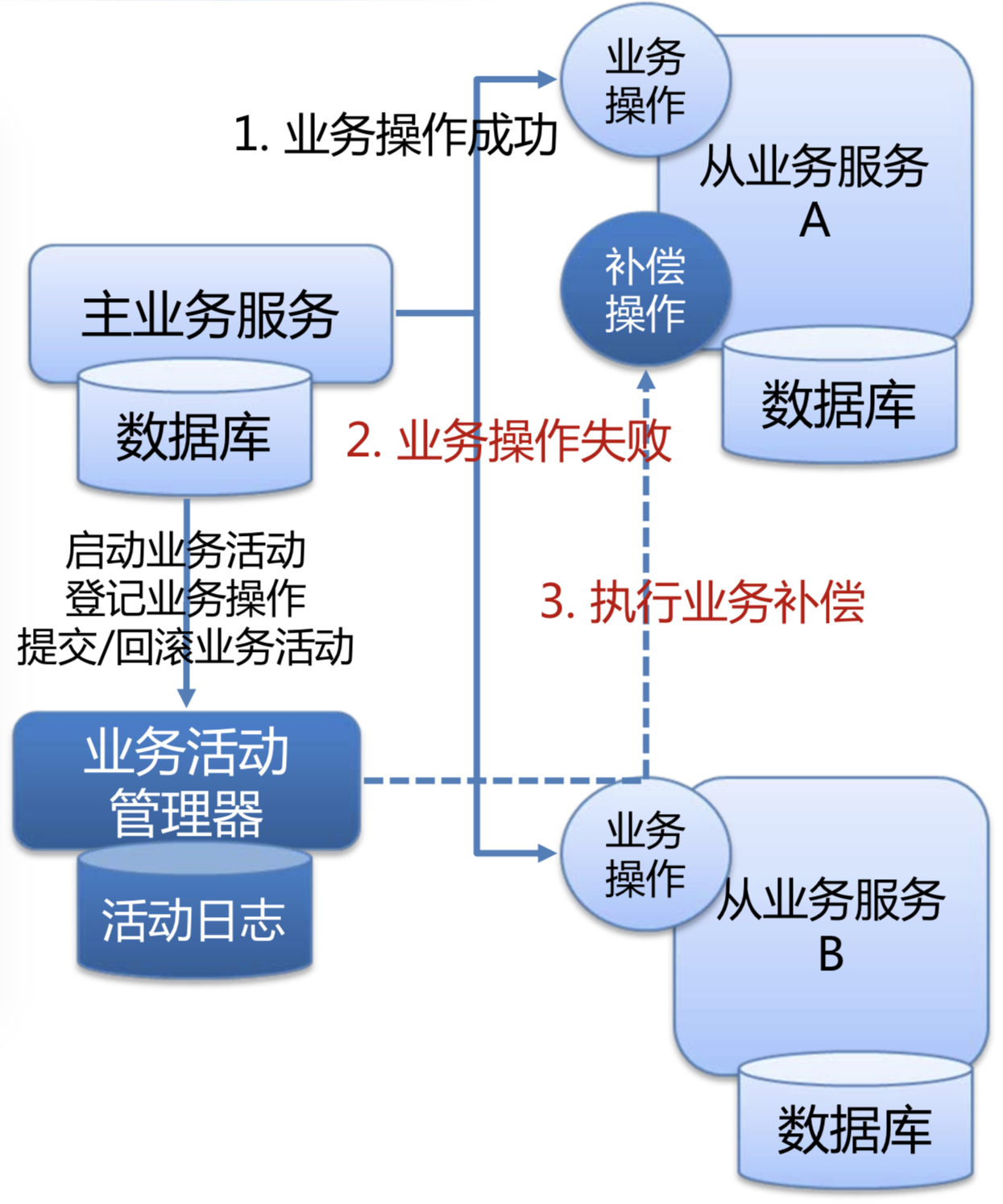
补偿型事务的前提是,业务补偿在业务上是可行的、逻辑上是行得通的,其次是要关注到补偿操作的成本,因有中间态而可能无法完全补偿。
所以,补偿型的成本在于:
- 从业务服务实现补偿操作的成本
- 由于无法完全补偿带来的业务成本
- 业务活动管理器的业务活动日志的成本(满足可用性)
补偿型的适用范围:
- 弱隔离性,弱一致性要求的业务活动
- 适用于执行时间较长的业务
2.2.2. TCC型
传统的像2PC协议和数据库的2PL两阶段锁(加锁阶段,只加锁不放锁;解锁阶段,只放锁不加锁),都要求一直持有资源锁直到整个事务执行结束,这导致他们吞吐量都不高、并发性能下降。而TCC型事务,则是通过对业务逻辑的分解,在一阶段结束之后,把资源层的隔离性上升到业务层,放宽了一致性要求,从而释放了整体的并发性能,更多的灵活性。TCC的每个操作对于资源层来说,都是单个本地事务,操作结束则本地事务结束。但这也要求,一阶段要预留业务资源来保证二阶段不会出错,比如交易时一阶段冻结交易资金,到第二阶段时扣除资金。
TCC型事务的模式:
-
Try操作:尝试执行业务(完成业务检查,预留业务资源);
-
Confirm操作:确认执行业务,不做业务检查,满足幂等性;
-
Cancel操作:取消执行业务(释放预留的业务资源),也要满足幂等性;
具体的实现是这样的:
- 主业务服务作为发起者,负责发起并完成整个业务活动;
- 若干从业务服务作为参与者,提供TCC型业务操作;
- 业务活动管理器作为协调者,控制业务活动的一致性,登记业务活动中的操作并在业务活动提交/取消时调用相应的Confirm/Cancel操作;
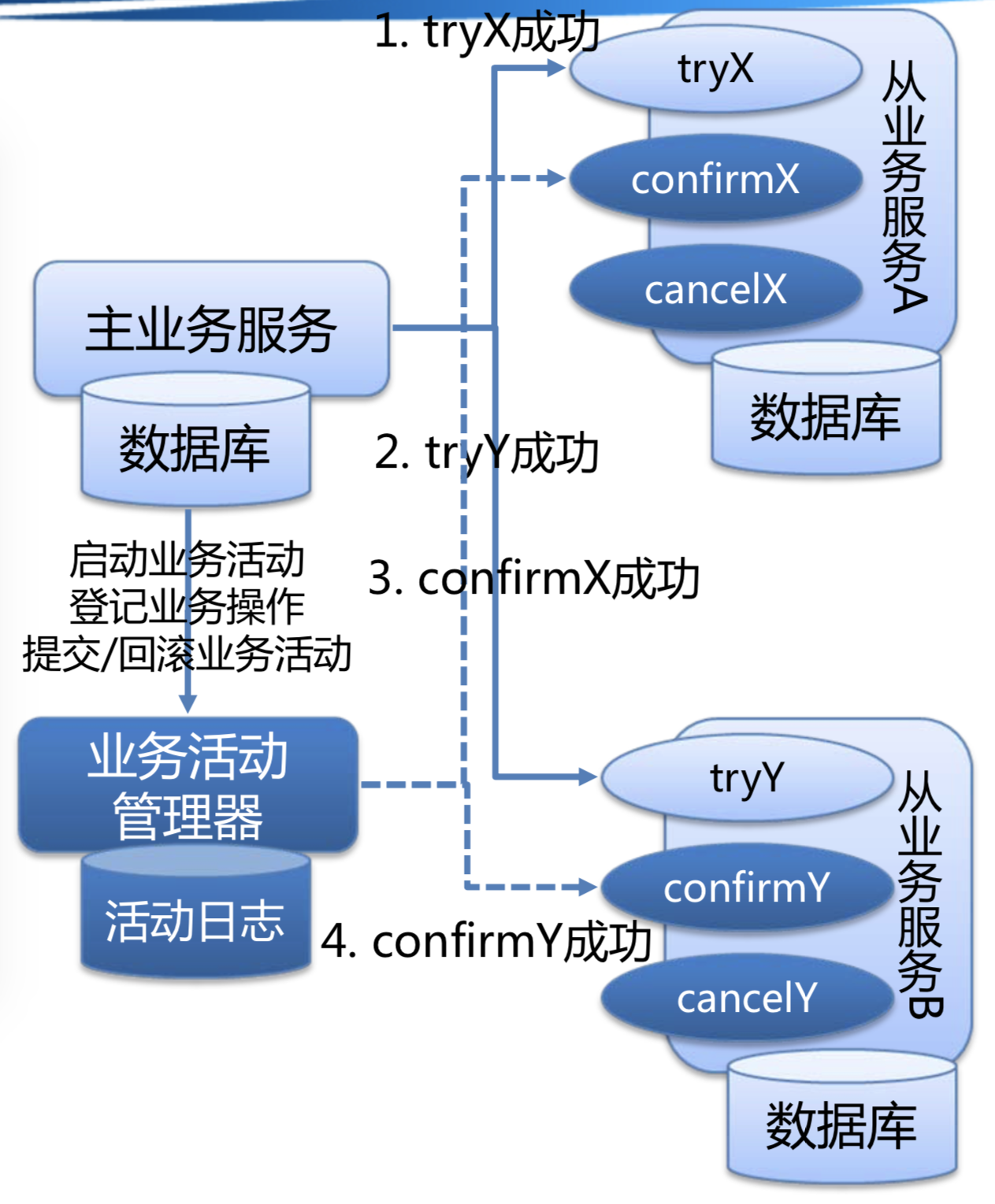
TCC型在事务处理过程中也会有中间态,会有数据短暂不一致的情况,但最终会让事务的数据达到最终一致。
TCC型除了幂等性要求外,还有两点要求:
- 允许空回滚:
在未收到Try请求的情况下收到Cancel请求,这种情况被称为空回滚。这很好理解,比如超时、丢包,此时为了确保事务一致性,将触发Cancel操作。- 防悬挂:
在实现上允许空回滚,但要拒绝执行空回滚后到来的Try请求。
TCC型的成本:
- 侵入性,需要用户提供三个接口(Try接口/Confirm接口/Cancel接口);
-
业务开始时实现Try操作的成本,业务活动结束时Confirm或Cancel操作的成本;
-
业务活动管理器的业务活动日志的成本;
TCC型的作用就是协调从业务服务的最终一致性,但它也有缺点,接入成本太高、需要拆分出三个接口。蚂蚁的DTX(对内叫XTS)提供了三种模式的能力:TCC模式、TCC的托管版本——FMT模式和XA模式。
FMT(Framework-managed transactions)即无侵入的框架托管模式,主要解决的就是TCC型接入成本的问题,提高易用性。它通过一个拦截层,自动解析SQL语义,自动生成二阶段提交和回滚操作。实现上,就是将从业务服务的本地事务作为一阶段,拦截业务SQL,根据SQL保存原数据快照->执行用户SQL->保存新数据快照(类似于MySQL的undo、redo日志);在二阶段,如果事务提交则删除快照,如果事务回滚则校验脏写->合并或覆盖->删除快照。
FMT型本质上就是TCC型,也包含主业务服务、从业务服务和业务活动管理器,但从业务服务不需要提供Try、Confirm、Cancel三个接口方法,而是按照JDBC标准,通过托管框架与底层数据源交互。也就是说,对业务透明、对业务代码无侵入。
TCC型的适用范围:
- 强隔离性,严格一致性要求的业务活动
- 适用于执行时间较短的业务
2.2.3. Saga型
Saga型事务也叫“Long-running-transaction”长时间事务,其实就是有一系列本地事务,每个本地事务都有执行和补偿操作,通过发布消息或事件来触发Saga里的下一个本地事务。当Saga中的一个本地事务出错了,通过相关补偿操作做事务恢复,来达到事务的最终一致性。它的核心思想是将长事务拆分成多个本地短事务,由中央协调器协调或相互协调,如果事务失败,则根据调用关系做正向补偿(重试异常步骤)或反向补偿(回滚前序步骤)。
对应于ACID,Saga只提供了ACD保证:原子性通过Saga协调器来实现,一致性由本地事务和落事务日志来实现,持久性则不用说。也就是说,Saga不保证隔离性,因为Saga事务没有准备阶段,事务没有隔离,而缺少隔离性的后果是,可能会有更新丢失-回滚覆盖、脏读、模糊读等情况。通常我们会在业务层面引入比如业务锁、预先占用资源、Session层隔离等方式来隔离这部分资源,以规避这部分问题。
对应于2PC、TCC他们是同步的事务模型,而事实上Saga模式就是一种异步补偿事务。
根据有无中心协调者可以分为:命令协调方式和事件编排方式。
♦ 命令/协调方式(Orchestration)
集中式Saga,就是有一个集中式的中央协调器来协调子事务的执行情况。为了解决分布式Saga事件源难以维护的复杂性问题,引入中央协调器来集中式的进行事件决策和业务编排,,以命令/回复的方式与每个子事务通信,负责告诉每个参与者什么时候该做什么,协调事务的执行 or 回滚。
集中式Saga的中央协调器协调器,有两点要求:
- 需要预先知道Saga事务的调用图,一般会通过读取业务流程配置或者XML,或者使用类似Zipkin这样的分布式链路组件,来实现Saga事务调用关系的跟踪;
- 集中式的协调器,包含Saga调用请求接收、分析、调用执行、结果查询,需要通过流程引擎做业务流的协调;
集中式Saga的优点:
- 避免服务之间的循环依赖
- 只需执行命令或回复,降低参与者的复杂性
- 在添加新步骤时,事务复杂性保持线性,回滚更容易管理
- 更容易实施和测试
集中式Saga的缺点:
- 存在单点风险
- 基础设施上,协调器要保证高可用
- 参与者和协调器耦合度高
华为的ServiceComb项目是国内目前唯一的基于集中式Saga实现的开源项目,作为华为云微服务框架引擎的一部分,由ServiceCenter做服务发现(基于ETCD)、由Zipkin做链路追踪。它有两个参与者,一边是协调端,负责协调事务执行情况,一边是监控端,负责收集事务执行情况,并向协调端上报信息并执行相关指令。
大致的实现方式:
- 监控端通过注解或者XML配置以切面编程的方式向应用注入相关的模块,比如拦截事务请求,用来构建分布式事务调用的上下文;
- 监控端在事务初始阶段处理事务的资源准备操作,例如创建Saga起始事件以及相关的子起始事件,根据事务执行的成功或者失败生产相关的事务终止或者失败事件;
- 协调端收到事件通知后,根据Saga事务执行情况,来决定是否给客户端下达指令进行相关的回滚恢复;
- 如果服务调用的过程中抛出异常,监控端将终止事件发送到协调器,协调端进程会定时做扫描,发现有需要恢复的事件,而后发消息通知客户端调用相关的恢复操作,来保证整个Saga事务的原子性;
♦ 事件/编排方式(Choreography)
分布式Saga,就是用事件驱动的方式让参与的服务相互交互(订阅相关的领域事件),服务方自己彼此协调。就是说,每个服务生产并监听其他服务的事件,并决定是否应采取行动。第一个服务执行一个事务,然后发布一个事件,该事件被一个或多个服务监听,这些服务再执行本地事务并发布(或不发布)新的事件;当最后一个服务执行完本地事务且不发布任何事件时,意味着事务结束。
比如订单服务,发布一个订单创建事件,被支付服务监听,进行完支付并发布支付完成事件后,被库存服务监听,做库存扣减并发布库存准备事件后,被货运服务监听,下货运单并发布货物交付事件,最后再被订单服务监听,变更订单状态为完成。因为需要跟踪订单状态,订单服务可能需要监听所有事件并更新其状态,其实除了订单服务以外的其他服务都是订单服务的子服务。也就是说,一个订单的完成需要经过这么些步骤,领域上订单服务与这些服务是包含与被包含关系,订单服务即发起方在业务上就是一个协调者。
分布式Saga的优点:
- 简单,容易理解
- 降低系统的复杂度,提高系统扩展性
- 所有参与者都是松耦合的
- 如果事务涉及步骤不是很多,那么它是合适的
分布式Saga的缺点:
- 如果涉及大量的业务事件会变得很混乱,即难以维护难以跟踪比如哪些服务监听哪些事件
- 服务之间会有循环依赖的问题,因为它们必须订阅彼此的事件
- 流程测试实施起来很麻烦
2.2.4. 消息型
消息型事务,即通过将同步的事务操作转变为基于MQ、消息队列的异步操作,避免了对数据库事务的争用,以及同步阻塞操作的影响,它其实就是通过本地事务+消息表的定时补偿来实现分布式事务。消息型事务的约束,一般来说,业务参与方的事务处理结果不影响业务发起方的处理结果。
在具体实现上,又分为两个版本:
♦ 最大努力型
实现方式:
- 业务发起方,在完成业务处理的同一个本地事务中,记录消息数据;
- 事务提交后,发送消息通知业务参与方,发送成功即删除/失效消息数据;
- 业务发起方定期扫描未成功发送的消息,做消息补发;
最大努力型模式,就是通过可靠消息最大限度的通知参与方(以最大重试次数为上限),利用MQ或消息队列可靠消息的特性来保证分布式事务处理的一种方式。它的成本,在于发起方本地消息表的建设成本,以及业务系统对消息数据CRUD成本。
它的适用范围:
- 对业务最终一致性的时间敏感度高;
- 降低业务参与方的实现成本;
♦ 数据核对型
实现方式:
- 业务发起方完成业务事务后,发送消息通知业务参与方;
- 业务参与方定期向业务发起方询问,恢复可能丢失的消息数据;
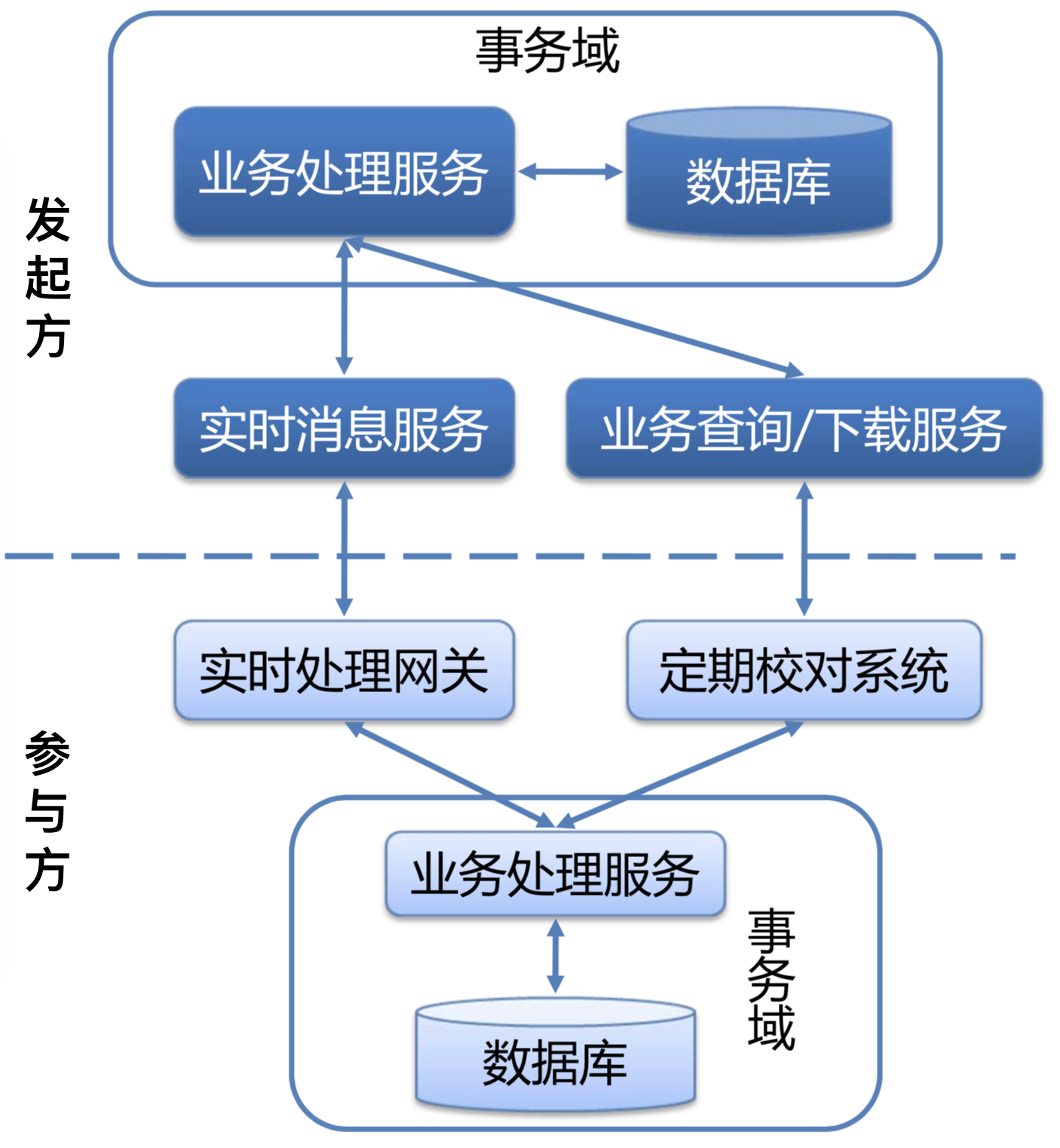
简单来说就是定期校对、核查,数据核对型模式的成本,是业务查询与校对系统的建设成本。它的适用范围,主要是对业务最终一致性的时间敏感度低的事务。
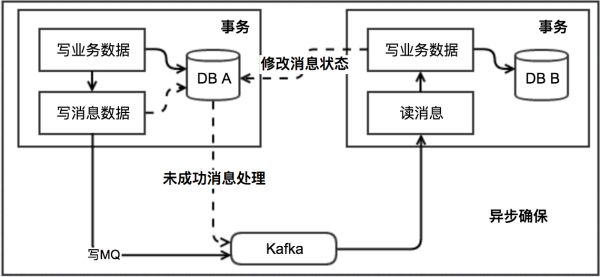
♦ 异步确保型
实现方式:
- 业务发起方在事务提交前,向消息中心发送消息数据,消息中心只记录、不发送(即事务型消息);
- 事务提交后,业务发起方向消息中心确认发送,消息中心收到确认后才真正开始发送消息数据;
- 事务回滚后,业务发起方向消息中心取消发送,消息中心删除/失效消息数据;
- 消息中心定期扫描未确认发送或回滚发送的消息数据,询问业务发起方的消息状态,后者根据消息ID或消息数据内容属性确定该消息是否有效,以决定是否发送该消息数据;
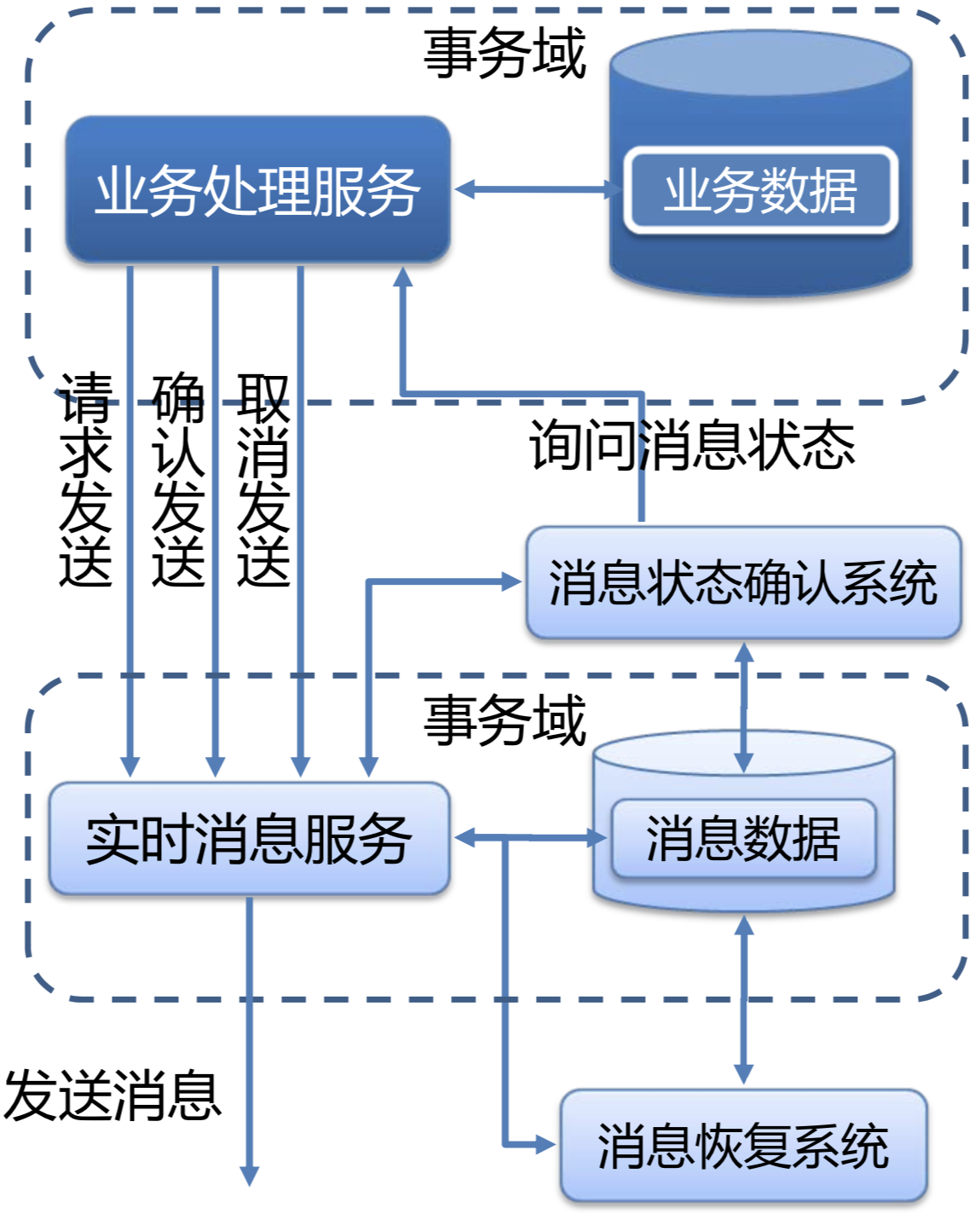
异步确保型模式,其实是利用了MQ或消息队列的事务型消息,MQ的异步回查来确保本地消息表未确认或回滚发送的消息补偿。它的成本,在于一次消息发送需要两次请求的通信成本,以及业务发起方需提供消息状态回查接口的业务代码侵入成本。但它的优点是,消息数据独立存储、独立伸缩,降低了业务系统与消息系统间的耦合。
消息型事务可以是单向的也可以是双向的,即发起方可以只管消息成功投递给参与方,对参与方成功或失败不关心,也可以关心后者的消费结果。它与分布式Saga的区别在于,分布式Saga的发起方天然就是一个隐式的协调者,它需要感知消息链路上每个节点上的状态变更,而双向的消息型事务,更多的是两个或三个节点互通。A通知BB通知C,B的成功失败、C的成功失败消费发送方可以感知,但在分布式Saga中A必须要感知。
2.2.5. “无锁”型
在本地事务上,事务性能和吞吐瓶颈往往是因为强事务带来的资源锁,如何很好地解决资源锁问题往往是实现事务高性能的关键。放弃资源锁也是解决问题的一个思路,但放弃锁并不意味着放弃隔离性,如果隔离性没保障,则必然要在后续引入其它方案来规避可能会大量出现的数据脏读、模糊读等问题。
无锁型的实现方式:
- 避免事务进入回滚:
事务出现异常时,如果可以不回滚也能满足业务要求,也就是要求业务不管出现任何情况,只能继续朝事务处理流程的正向继续处理,这样中间状态即使对外可见,由于事务不会回滚,也不会有什么脏读的问题。 - 辅助业务变化明细表:
对热数据数据源(比如资金或商品库存)进行事务操作时,采用记录这些增减变化的明细表或日志记录的方式,避免大量事务均对同一数据表进行更新操作,从而造成数据访问热点的问题。
同时,不同事务中处理的数据进行业务维度的拆分和隔离,互不干扰互不影响,拉低事务并发问题的发生概率。 - 乐观锁
悲观的锁策略对数据访问具有极强的排他性,也是产生事务处理瓶颈的原因之一。若能用乐观锁(比如状态机)、自旋,则在一定程度上缓解了这个问题。
2.3. 总结
在实际应用中,大型分布式事务的解决方案,一般是对一个大的事务进行拆分,拆成若干个小的事务,然后通过设计业务补偿等手段来考虑最终一致性。即大多数的分布式场景,尽量不用强一致性事务(除非有强一致性需求),更脆弱、效率更低,最简单的办法就是允许不一致,通过本地事务(XA)+MQ可靠消息/异步确保/定期补偿,提供回滚接口来达到最终一致性。
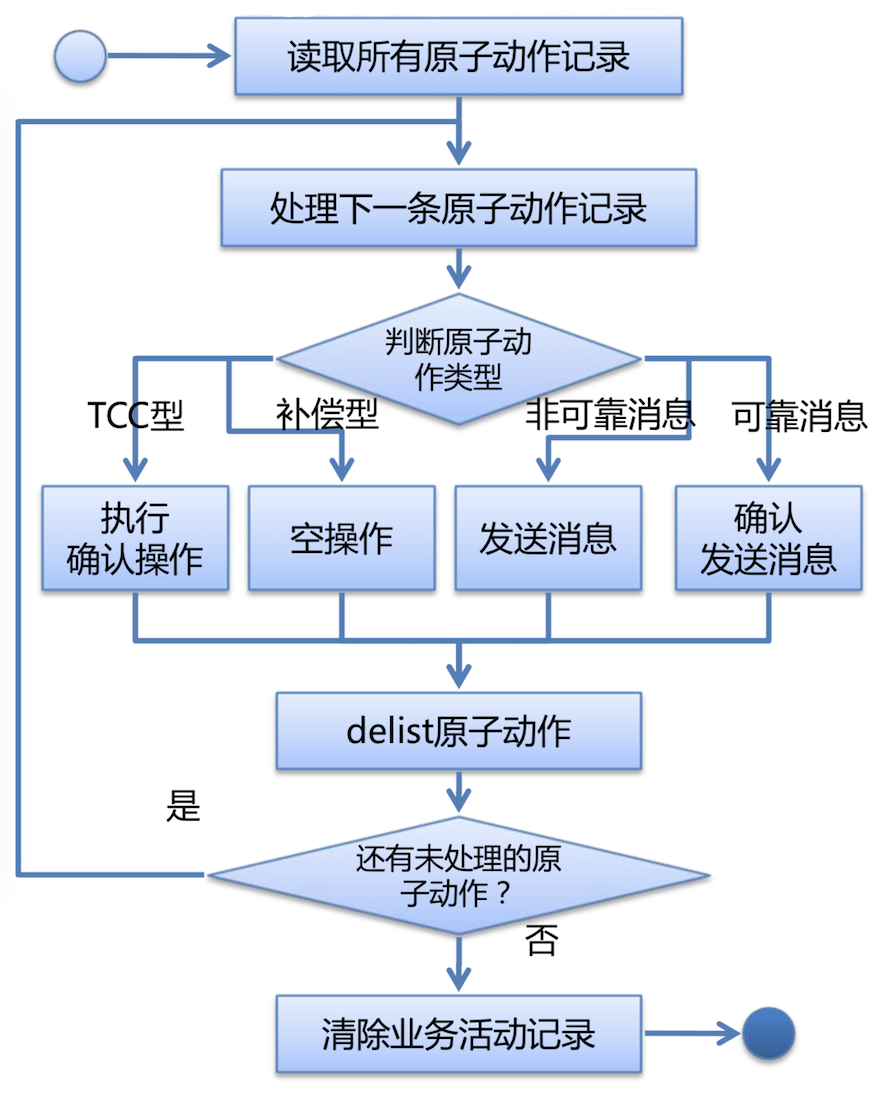
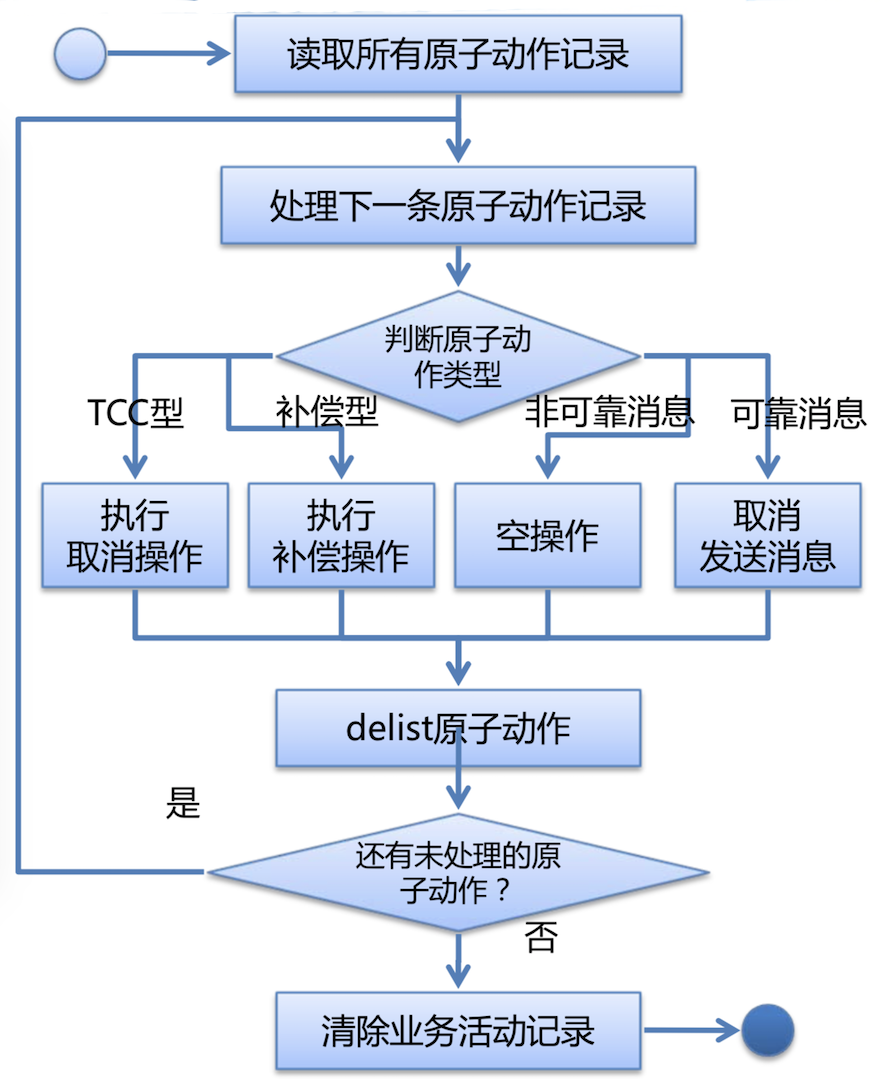
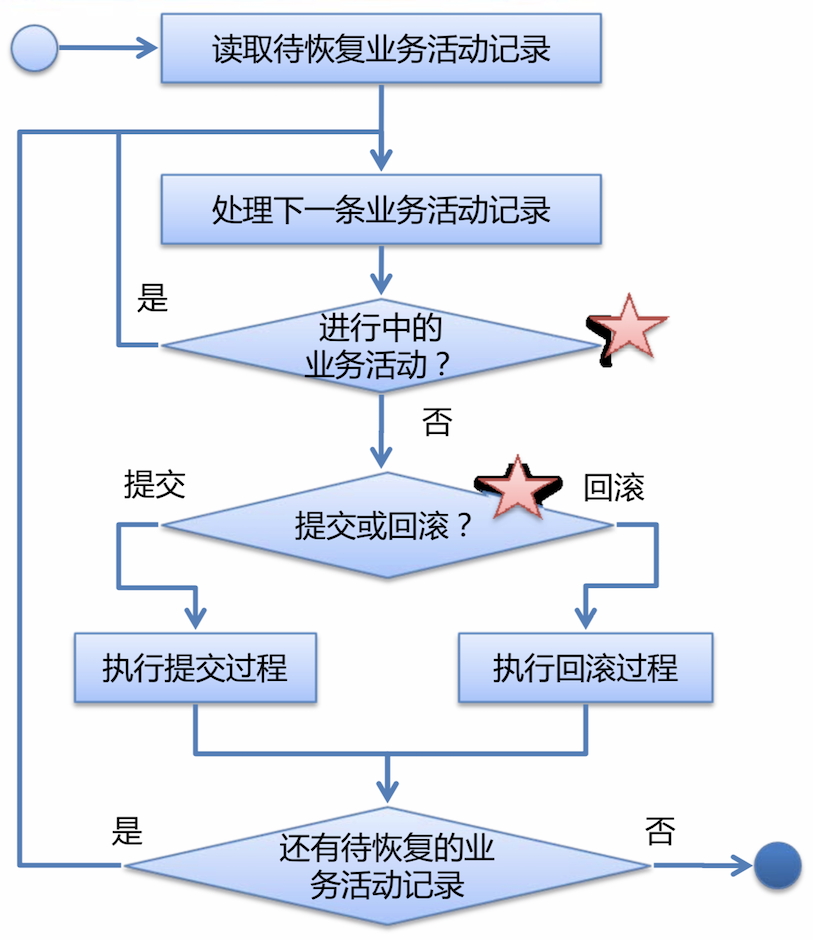
简单的实现过程:
- 事务提交:
- 事务回滚:
- 事务恢复:
实现策略:
- 在主控动作的本地事务提交/回滚后,由业务活动管理器接管执行;
- 通过注册事务同步器监听主控动作的本地事务提交事件;
- 提交过程可能时间较长,具体实现时,尽量让这个过程异步化、并行化;
-
提交过程中如果发生故障造成处理中断,由恢复过程自行恢复;
实践上的总结:
- 事务ID的生成规则:
需要为每个事务创建一个唯一的事务ID,便于后续追踪处理步骤,以及幂等性需求; - 可靠投递与回查:
在事件或命令中添加回复地址,便于确定来源和链路追踪;
设计上要有一定的容错能力,比如因为上游的bug,可能会触发/重发不需要的消息; - 业务补偿要求:
幂等性,空回滚与防悬挂
可以定期做数据核对比如T+1,降低业务风险 -
并发控制
预留资源或锁资源
发生竞争之后的业务补偿或异步重试
大事务拆多个小事务,降低并发度
做异步化,降低锁时长
通过蓄洪、削峰填谷,降低数据热点
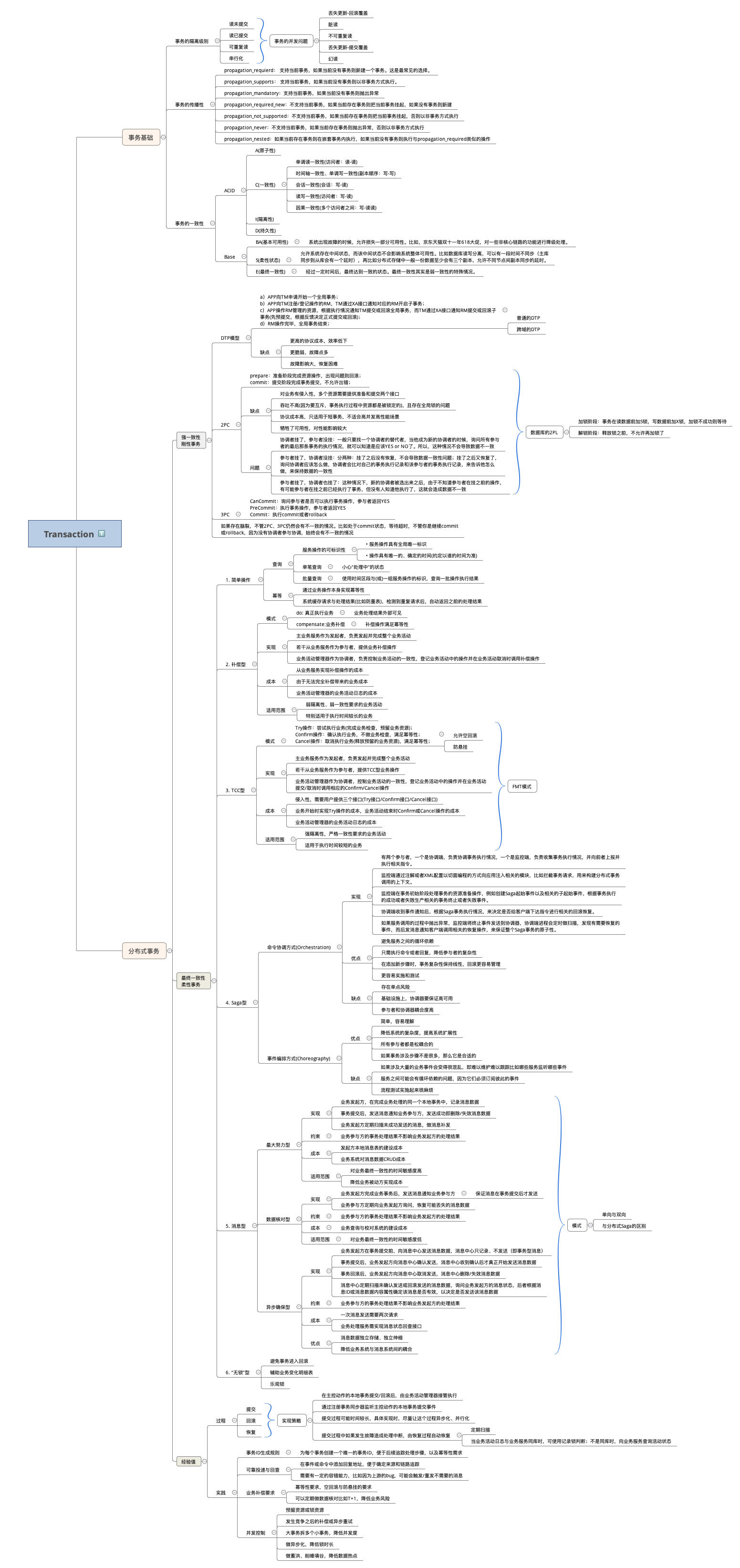
最后,来张知识体系导图作为总结:
※ 附录:
参考:
- 大规模SOA系统中的分布事务处事-程立:wenku.baidu.com/view/be946bec0975f46527d3e104.html;
- Saga分布式事务解决方案与实践:servicecomb.apache.org/cn/docs/distributed-transactions-saga-implementation/;















 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









