






前言
什么叫Inode节点很奇怪,昨晚发的博客不见了....所以就少了Linux学习第六篇,这篇博客是第六篇Inode节点的补充.
inode节点翻译成中文应该叫做索引节点,学过编程语言的人都知道数组存储数据时就需要使用索引(index).
Inode在linux中是一种数据结构,包含了文件系统中文件相关的重要信息.
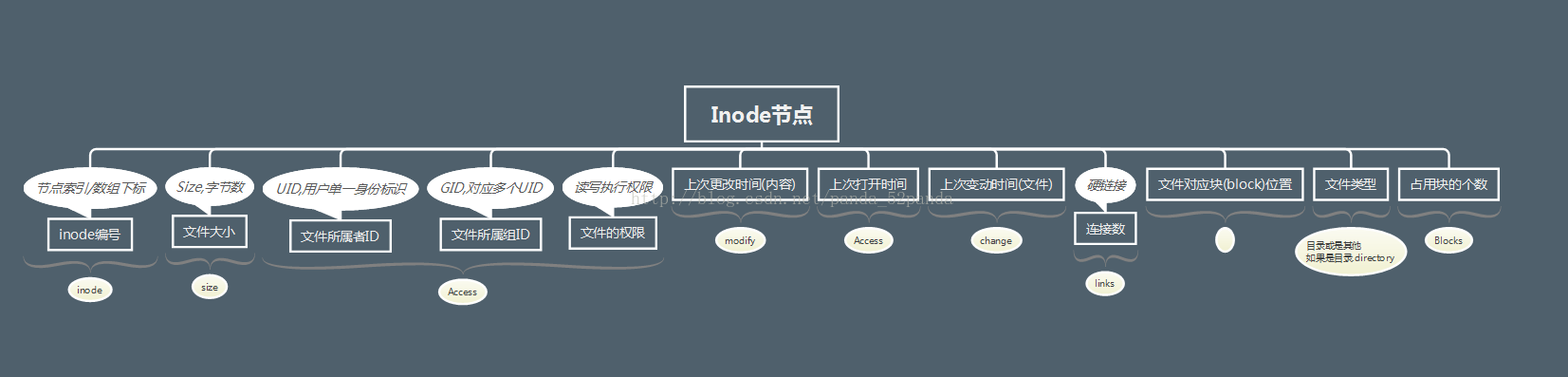
提到Inode节点通常还会提到一个词汇:索引编号,索引编号本质上是Inode节点的标志编号,所以也被称为inode编号/索引编号.
如果想要详细的讲清楚inode节点,那么就要涉及到一个概念文件系统.
在linux中每一个分区都是一个文件系统,他们各自拥有自己的目录树,当然最后,linux会把他们整合成一个目录树.
为了维护这颗目录树,linux使用了Inode节点来记录文件信息.需要注意的是,每个文件系统(分区)都会维护一个索引节点的数组
那么这个节点中又存放了什么样的数据呢?
在上图中涉及到了一个概念--块(block).
块(block):在之前的博客中提到过硬盘的存储,其中硬盘存储的最小单位是扇区,大小为512个字节,系统在读取硬盘时,为了提高效率会连续读取多个扇区的内容,这几个扇区构成一个块,所以块是文件存取的最小单位,通常8个扇区组成一个块,即每个块的大小4KB.
那么linux又是如何将inode节点和文件进行关联的呢?如果学过编程语言的话,应该会知道一种数据结构,HashMap.
在linux中,会将文件的名称和inode节点的索引同时保存在一块,每一对文件名称好索引成为一个链接.
这样当用户访问文件时,通过文件名称查找到对应的inode节点,然后就能读取到指定块内的数据了.
当然inode节点不止这么简单,但是此处只是作为第六篇的补充,所以了解其概念就好啦~

















 2295
2295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









