







PMML, Predictive Model Markup Language.
1.简述
PMML 用于描述算法模型, 允许您在不同的应用程序之间轻松共享预测分析模型.
通俗地讲, 我有一个决策树模型, 使用效果也不错, 那么就可以把树的结构(节点间的父子关系, 节点内的丰富信息 等)序列化为PMML文件, 共享给其他人使用.
2. 主要结构
PMML 文件的结构遵从了用于构建预测解决方案的常用步骤,包括:
- 数据词典
这是一种数据分析阶段的产品,可以识别和定义哪些输入数据字段对于解决眼前的问题是最有用的。这可以包括数值、顺序和分类字段。 - 挖掘架构
定义了处理缺少值和离群值的策略。这非常有用,因为通常情况,当将模型应用于实践时,所需的输入数据字段可能为空或者被误呈现。 - 数据转换
定义了将原始输入数据预处理至派生字段所需的计算。派生字段(有时也称为特征检测器)对输入字段进行合并或修改,以获取更多相关信息。例如,为了预测停车所需的制动压力,一个预测模型可能将室外温度和水的存在(是否在下雨?)作为原始数据。派生字段可能会将这两个字段结合起来,以探测路上是否结冰。然后结冰字段被作为模型的直接输入来预测停车所需的制动压力。 - 模型定义
定义了用于构建模型的结构和参数。PMML 涵盖了多种统计技术。例如,为了呈现一个神经网络,它定义了所有的神经层和神经元之间的连接权重。对于一个决策树来说,它定义了所有树节点及简单和复合谓语。 - 输出
定义了预期模型输出。对于一个分类任务来说,输出可以包括预测类及与所有可能类相关的概率。 - 目标
定义了应用于模型输出的后处理步骤。对于一个回归任务来说,此步骤支持将输出转变为人们很容易就可以理解的分数(预测结果)。 - 模型解释
定义了将测试数据传递至模型时获得的性能度量标准(与训练数据相对)。这些度量标准包括字段相关性、混淆矩阵、增益图及接收者操作特征(ROC)曲线图。 - 模型验证
定义了一个包含输入数据记录和预期模型输出的示例集。这是非常重要的一个步骤,因为在应用程序之间移动模型时,该模型需要通过匹配测试。这样就可以确保,在呈现相同的输入时,新系统可以生成与旧系统同样的输出。 如果实际情况是这样的话,一个模型将被认为经过了验证,且随时可用于实践。
3. GBDT例子
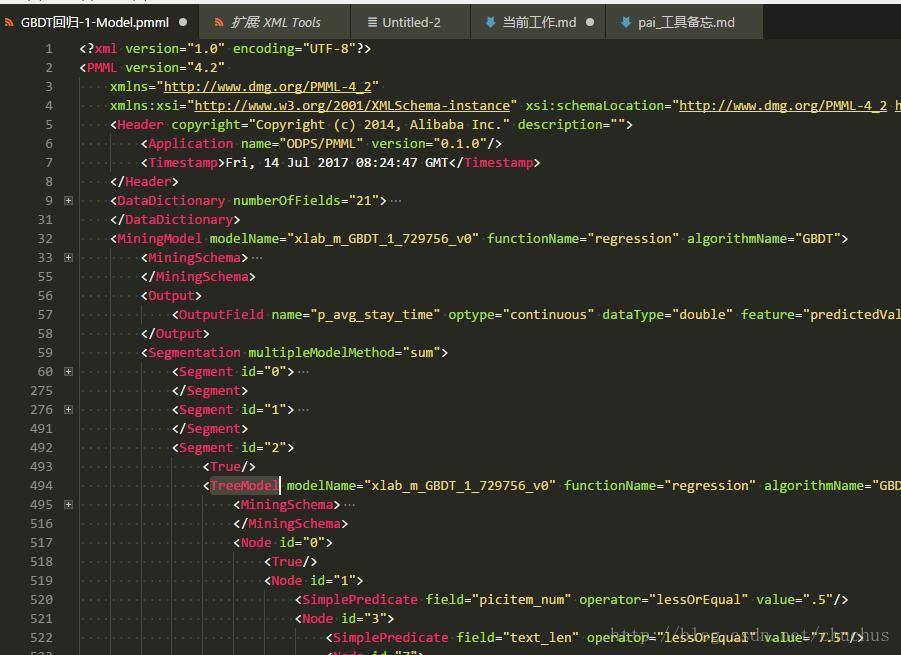
图3-1 一个GBDT决策树的回归模型
可以看出模型是由若干棵树组成的, 通过加和来使用.
每棵树的编号从0开始, 是根节点. 因为是完全二叉树, 所以若当前节点为x, 则左子树为2x+1, 右子树为2x+2.
具有父子关系的节点, 子节点会在父节点内部且有缩进.
简化一下图3-1中的 模型, 得到下列xml片段. 它的可视化见图3-2 .
<!--代码片3 , 回归决策树的表达-->
<!--section_num表示文章中段落个数, picitem_num表示商品图个数等, 根据这些特征来预测文章的等级.-->
<Node id="0">
<Node id="1">
<SimplePredicate field="section_num" operator="lessOrEqual" value="6.5"/>
<Node id="3" score="2">
<SimplePredicate field="picitem_num" operator="lessOrEqual" value="15.5"/>
</Node>
<Node id="4" score="3">
<SimplePredicate field="picitem_num" operator="greaterThan" value="15.5"/>
</Node>
</Node>
<Node id="2">
<SimplePredicate field="section_num" operator="greaterThan" value="6.5"/>
<Node id="5" score="4">
<SimplePredicate field="text_len" operator="lessOrEqual" value="895.5"/>
</Node>
<Node id="6" score="5">
<SimplePredicate field="text_len" operator="greaterThan" value="895.5"/>
</Node>
</Node>
</Node>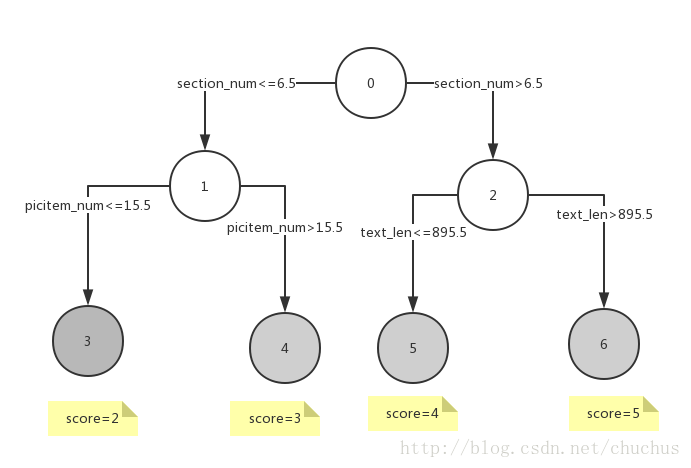
图3-2 代码片3的可视化表示
4.参考资料
参考资料:
IBM 知识库:何为 PMML?
PMML 4.1 GeneralStructure 文档
PMML 4.1 TreeModels 结构文档















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









