







2.7 版本对中文很不友好
具体的不友好
- 遍历字符乱码
- 长度计算
len('你好') # returns 6是会有问题的, 一个中文字符按三个长度算. - 字符串输出
list.__str__()
['你好','世界'].__str__()会返回乱码, 但','.join(['你好','世界'])就不会.
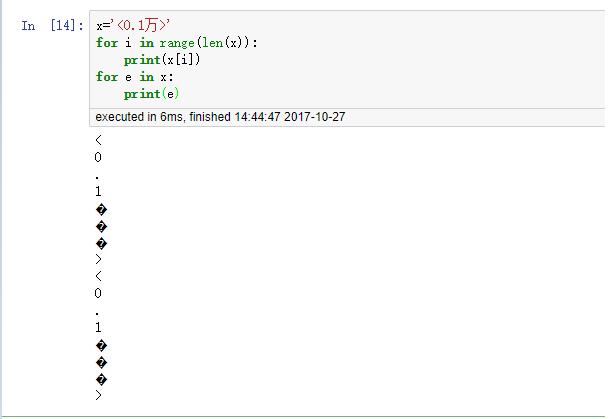
我的主意
- 处理中文前使用
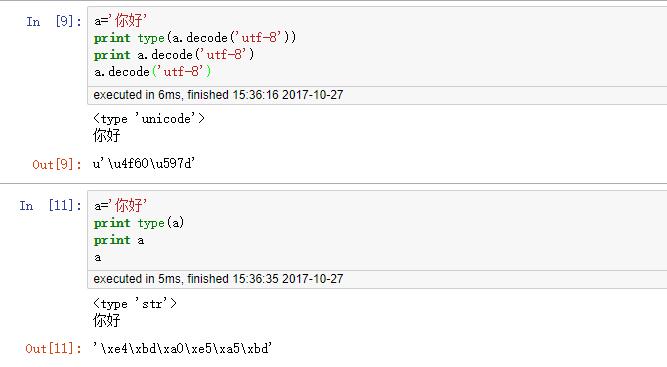
builtins.str#decode()方法, 如'你好'.decode('utf-8') - 创建中文字符常量用于相比时主动加
u前缀, 如name=u'小明'. - 在调用
str.join()方法时再使用builtins.str#encode()方法. 如my_arr.add(word.encode('utf-8'))
方案
一个实际的例子, 判断字符串是否为广义的数字且长度是否合理.
# coding:utf-8
import sys
class StringUtils:
"""
工具静态类
"""
@staticmethod
def is_generic_number(x):
"""
广义的数字--- 整数,符号,小数点,百分号,分数,计量
:param x:
:return:
"""
flag = False
#中文前不加 u前缀, 是不能与 Unicode的字符比较的, 永远不会相等.
generic_number_set = set(['+', '-', '*', '/', '.', '%', ':', u'十', u'百', u'千', u'万', u'亿'])
for i in range(len(x)):
the_char = x[i]
if the_char.isdigit() or the_char in generic_number_set:
flag = True
else:
flag = False
break
return flag
@staticmethod
def is_too_long_or_short_word(x):
return len(x) > 30 or len(x) <= 1
@staticmethod
def should_drop(x):
if not isinstance(x, str):
return False
if sys.version.__contains__('2.7'):
try:
x=x.decode('utf-8')
except:
sys.stderr.write("decode utf-8 error. the str is {}".format(x))
return False
return StringUtils.is_too_long_or_short_word(x) or StringUtils.is_generic_number(x)
x = '0.1万亿'
print(StringUtils.should_drop(x))#True













 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









