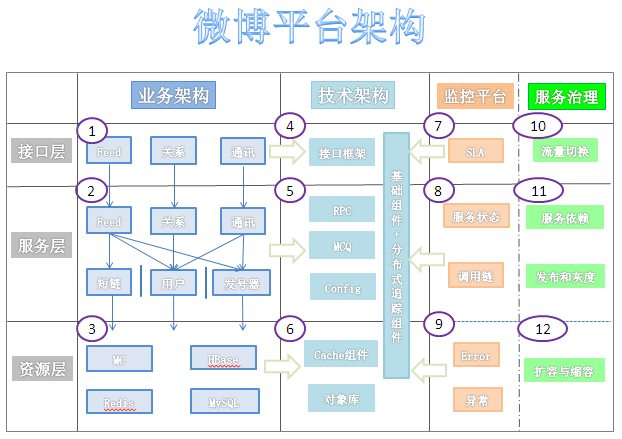
从上图可见,新浪微博的架构从发一篇微博开始,就已经展开了一张巨大的网,每一个节点相关联但又相对独立。在其资源层采用了常见的mysql,hbase,redis,并依赖cache组件与对象库满足了其高并发的性能要求。服务层架构离不开RPC远程调用框架以及消息队列框架(mcq)。而整个feed系统是用户接触最多,也是我们这次仿写微博的主战场,它蕴含的技术点也不少。 依据此,也依据我们团队的技术特点及实际业务能力。在资源层,采用了redis,mongodb以及mysql数据库作为数据存储支撑。在cache组件方面使用redis代理了mybatis的二级缓存,适应读多写少的业务环境。同时参考京东的架构应用mongodb这种文件存储型数据库存储微博回复内容,而依据redis在计数方面的优越性能,在微博点赞及好友关注业务上做了具体实现。 具体的服务层设计,依赖在Mysql中创立关系表维护用户间好友关系,而Feed系统的架构依赖Active这只消息中间件及Websocket全双工通信协议及Mqtt即时通讯协议,在通讯方面依旧采用与Feed系统同样的策略。 下图展示的内容大概是我们微博的整体构思,也是目前实现的大多。
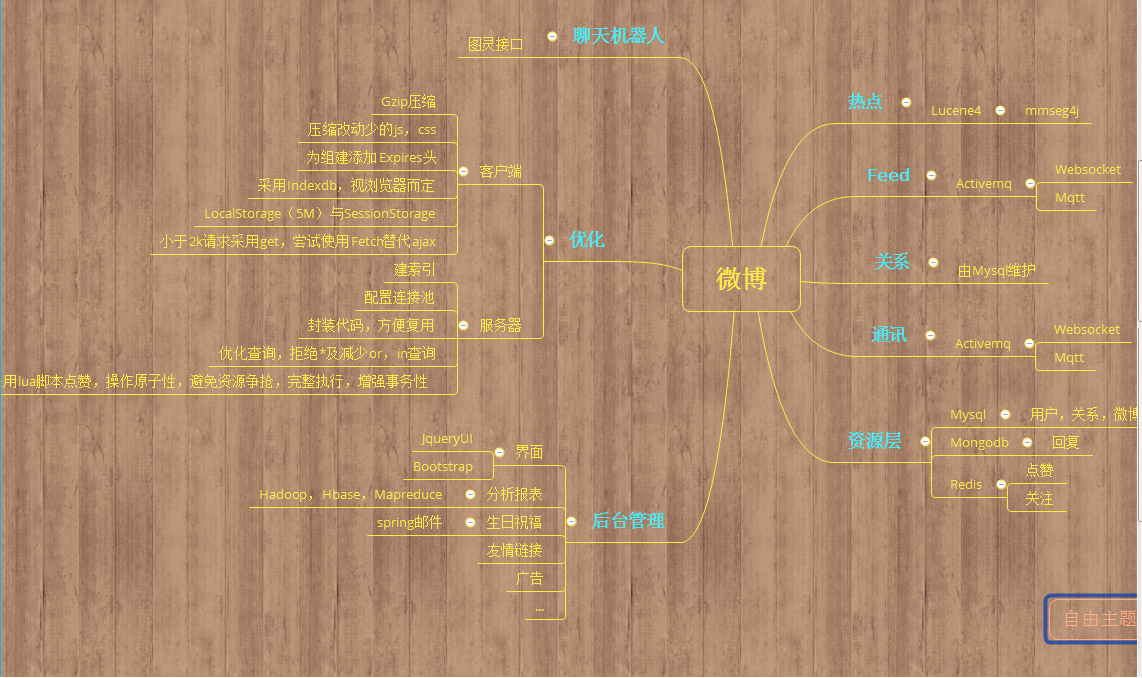
在Feed系统的实现上,主要遇到的难点是消息的实时推送,例如小红发一条微博,他的在线好友小明小华都得实时收到微博更新。 这里就以小红为例,在登录微博的时候,便请求到其关注好友最近发的微博,这是一条sql语句实现的。获取到服务器返回数据后,这里简单考虑将小红好友的uid存到一个数组中,然后小红开启websocket的客户端,连接到Activemq服务器,订阅并监听以好友uid为地址的消息队列。于是小明发微博的流程是这样的,首先往mysql中存储微博数据,客户拿到成功结果后往小明自己的主题队列添加一条消息。小红因为监听了小明的消息队列,首先在其界面隐藏的消息框存储,为了友好先提示小红小明更新了微博,她点开便是一条小明崭新还热乎的微博。于是具体的代码就以下几句了。 [code lang="javascript"] var client; function showchat() { client = new Messaging.Client('localhost', Number("61614"), "example-" + (Math.floor(Math.random() * 100000))); client.onConnect = onConnect; client.onMessageArrived = onMessageArrived; client.onConnectionLost = onConnectionLost; client.connect({ userName : "100", password : "100", onSuccess : onConnect, onFailure : onFailure }); } var onConnect = function() { console.log("connected to MQTT"); var uidarr=sessionStorage.getItem("uidarr"); uidarr = uidarr.split(","); for(var i=0;i<uidarr.length;i++){ client.subscribe(uidarr[i].toString()); } }; function onFailure(failure) { console.log("failure"); console.log(failure.errorMessage); } function onMessageArrived(message) { var divmessage = document.getElementById("message"); //解决string字符转换为html代码的问题 divmessage.innerHTML=message.payloadString; } function onConnectionLost(responseObject) { if (responseObject.errorCode !== 0) { console.log(client.clientId + ": " + responseObject.errorCode + "\n"); } } [/code] 在这里需要特别说明的是,其中用到了Mqtt这个即时通讯协议,Facebook便在用,但它更广阔的施展舞台是在安卓端以及物联网。大概每隔几秒,基于心跳感应机制,客户端会向服务器发送一个数据包表示自己还活着,一但超时没发数据包便被服务器判定为挂了。 Redis代理Mybatis二级缓存就相对简单了,首先继承mybatis的cache接口注入redistemplate就可以开始玩了。 基于Lucene做热词的分析,首先需要先建好索引. [code lang="java"] public void index() throws Exception { Document document = null; writer = getWriter(OpenMode.CREATE); ApplicationContext context=new ClassPathXmlApplicationContext("beans.xml"); MessageBiz messageBiz=(MessageBiz) context.getBean("messageBizImpl"); List<Message>list = messageBiz.selectAllMessage(); for (Message me:list) { document = new Document(); try { String mcontent=me.getMcontent(); //咱得解决一些html,js代码抽风跑进来的问题 mcontent=mcontent.replaceAll("\\&[a-zA-Z]{1,10};","").replaceAll("<[^>]*>", ""); mcontent=mcontent.replaceAll("[(/>)<]", ""); //其实我们用到的也就微博内容的索引,但是在这里咱得在lucene表里面存齐全了,方便之后的查询 //这里Field 相当于传统数据库里面的列,而document指一条记录,没写好一条记录就往lucene表里添 Field field = new TextField("Mcontent",mcontent,Store.YES); document.add(field); Field field1 = new TextField("Mid",String.valueOf(me.getMid()),Store.YES); document.add(field1); Field field2 = new TextField("Mdatetime",me.getMdatetime(),Store.YES); document.add(field2); Field field3 = new TextField("Uid",String.valueOf(me.getUser().getUid()),Store.YES); document.add(field3); Field field4 = new TextField("Ualais",String.valueOf(me.getUser().getUalais()),Store.YES); document.add(field4); Field field5 = new TextField("Uimage",String.valueOf(me.getUser().getUimage()),Store.YES); document.add(field5); if (writer.getConfig().getOpenMode() == OpenMode.CREATE) { System.out.println("adding " + me); writer.addDocument(document); } else { System.out.println("updating " + me); writer.updateDocument(new Term("path", me.toString()), document); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } try { if (writer != null) writer.close(); } catch (IOException e) { e.printStackTrace(); } } [/code] Lucene的热词分析,这里通过统计关键词出现的频率来实现热点分析,但是没做相关聚合,于是就真的只是热词而已。 [code lang="java"] public List<HotWord> Hotword() throws IOException{ List<HotWord>list = new ArrayList<HotWord>(); //找到相关索引表 Directory indexDirectory = FSDirectory.open(new File("d:/index")); //索引读取器 IndexReader indexReader = DirectoryReader.open(indexDirectory); //根据具体列查询出关键字集合 Terms terms = MultiFields.getTerms(indexReader, "Mcontent"); TermsEnum termsEnums = terms.iterator(null); BytesRef byteRef = null; while ((byteRef = termsEnums.next()) != null) { //关键词 String term = new String(byteRef.bytes, byteRef.offset,byteRef.length); //出现频率 long total=termsEnums.totalTermFreq(); //System.out.println("term is : " + term); //System.out.println(termsEnums.totalTermFreq()); //这里由于用户少微博少,只将热词出现大于五的取出来,初步实现 //解决方案,利用数组对词频排序,取前十。同时存关键词,利用遍历数组找寻排序后数的之前位置,对应关键词数组下标 //优化方案,利用redis排序 if(total>5&&term.length()>=2){ HotWord hotWord = new HotWord(); hotWord.setTotal(total); hotWord.setWord(term); list.add(hotWord); } } return list; } [/code] 其实很多新技术对于大牛而言,都是些用烂的东西,对于我们新手而言却是无比陌生,许多时候折腾一上午也许就写出了五六行代码,但同时学到了许多解决方案,虽然它们的实现偏离了我的需求。 最后给个之前录的两个视频,redis及微博红人榜没来得及整上来,界面比较丑~ http://v.qq.com/x/page/m0326np5kae.html http://v.qq.com/x/page/q0326sol3k4.html





















 1085
1085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









