






注:本人环境 :spark-2.2.0 ,hadoop 2.6.3, kafka 0.10.x.x
Spark 官方给出来的 Structured Streaming Demo 是这样的:
SparkSession spark = SparkSession.builder().appName("JavaStructuredKafkaWordCount").getOrCreate();
// Create DataSet representing the stream of input lines from kafka
Dataset<String> lines = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option(subscribeType, topics)
.load()
.selectExpr("CAST(value AS STRING)")
.as(Encoders.STRING());
// Generate running word count
Dataset<Row> wordCounts = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String x) throws Exception {
return Arrays.asList(x.split(" ")).iterator();
}
}, Encoders.STRING()).groupBy("value").count();
// Start running the query that prints the running counts to the console
StreamingQuery query = wordCounts.writeStream().outputMode("complete").format("console").start();
query.awaitTermination();上面的例子是接收 kafka 数据,然后经过一个 字符串拆分 、group by 和 count 操作。最后,输出到 console 的示例。
当然,这里没有给出 .schema() 这个方法。
val userSchema = new StructType().add("name", "string").add("age", "integer")通过这个方法,我们可以对接收到的 text, csv, json, parquet 数据直接进行处理。
这种方式,并不一定适合所有的数据,,比如,我有这样的数据格式:
key,value1,v11,v12,v13##key2,value2,v21,v22,v23
就不能直接处理了。。。。接下来,主要介绍一下,如何自定义自己的 format 方式。
================================================================
从 spark 的源码中,我们可以看出来,主要的接口类为:DataSource 类的 lookupDataSource 方法中:其中有一句代码:
val serviceLoader = ServiceLoader.load(classOf[DataSourceRegister], loader)
注意这里的 DataSourceRegister。
如果我们要自定义自己的 DataSource ,需要继承这个接口类,并实现相应的方法。
当你直接在 main 中运行的时候,你就会发现,我们自己定义的类,是不能被 Spark 找到,并正确运行,主要原因为:我们的这个实现类,没有注册到他的 Spark 的 dataSource 的 Provider 中。
对 ServiceLoader 数据的朋友都知道,如果要注册,就需要在自己的 classpath 下,创建 META-INF 文件夹,在该文件下面创建 org.apache.spark.sql.sources.DataSourceRegister 文件,在该文件中,写入自己的全报名加类名称。如下 Spark 源码示例:
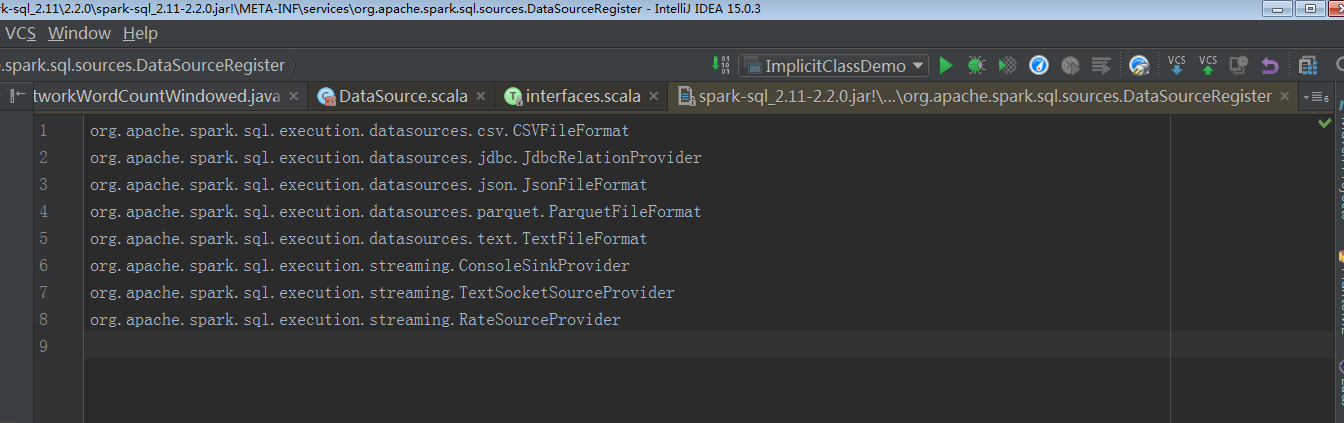
上面介绍了,需要实现 DataSourceRegister ,可能你要问了,该类中只有一个方法,而且是返回字符串 shorName() 根本没有达到需要的效果。
感谢你还会继续往下阅读!
接着再研究源码,你可以方法这里还需要一些东西,在 DataSource 这个类里面,还有两句源代码是需要我们研究的东西,如下代码:
lazy val providingClass: Class[_] = DataSource.lookupDataSource(className)lazy val sourceInfo: SourceInfo = sourceSchema()serviceLoader.asScala.filter(_.shortName().equalsIgnoreCase(provider1)).toList match {
providingClass 一眼就能看懂,是从 DataSource.looupDataSource 方法中,去查找它的 ProvidingClass ,从上图中的第三句可以到,是进行了 匹配工作。假如,我们这里没有找到。
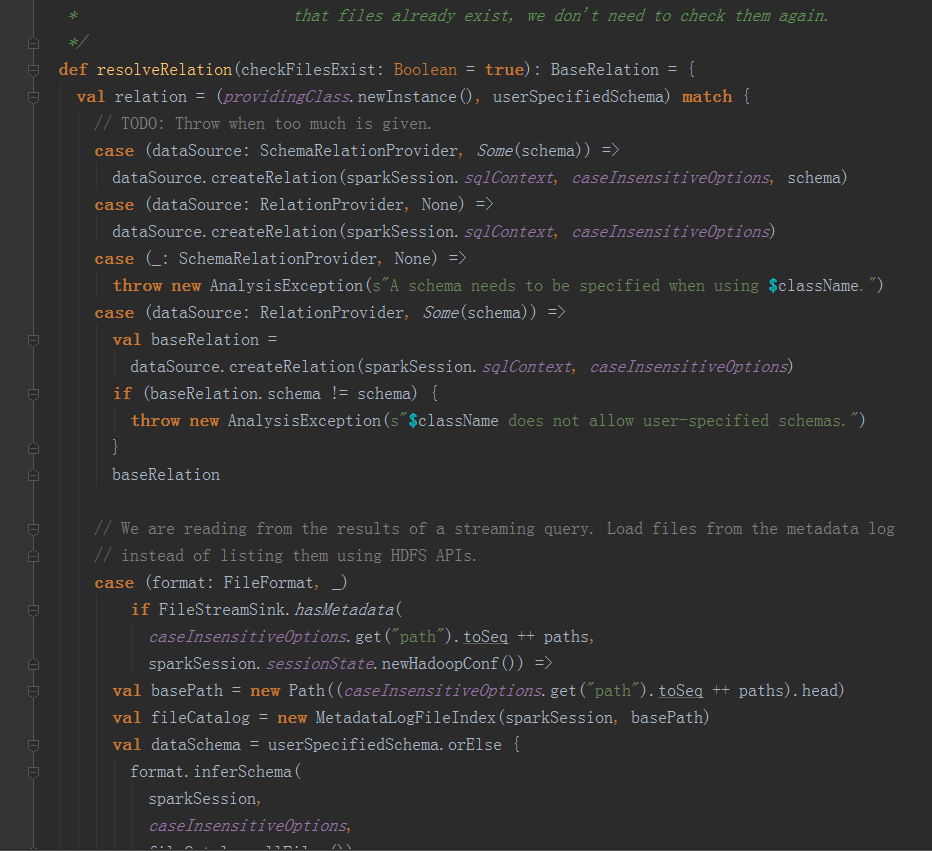
接着运行第二句代码,在 sourceSchema() 这个方法中,主要是去实例化 Source 并创建 Source 类,传入相应的参数。
下图为 sourceSchema() 这个方法的详情,
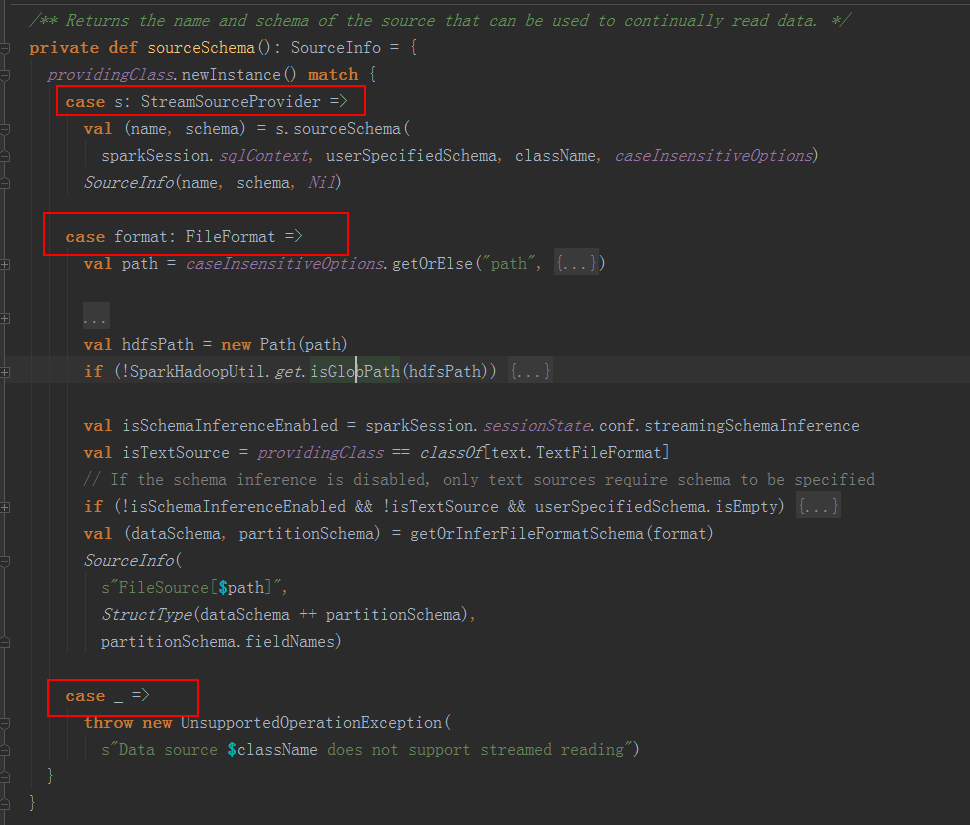
看到这里,是不是已经很明白了,,
Spark Structured Streaming 支持两种方法。分别是 FileFormat 和 StreamSourceProvider 。
我们的 DataSource 类,是需要提供 FileFormat 或 StreamSourceProvider 的实现。
这才是我们正在定义自己 format 的地方。
看看 Spark 官方提供的实现:
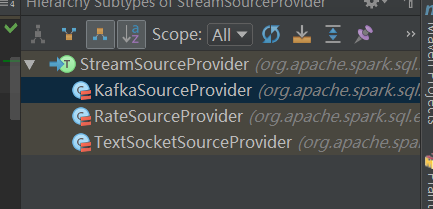
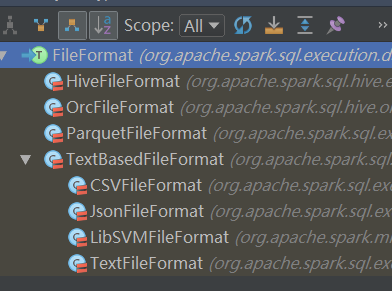
下图,这里是 Spark 中已经有的 provider , 当然,我们也看到了 SinkProvider,相信不用我介绍 Sink,你也能自己创造出 Sink 的 方式了。
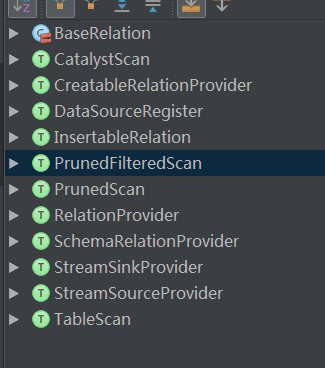
说到这里,,其实,还缺少一种 format 方式,那就是 :RelationProvider, 这种方式,主要源码在 DataSource.scala 类的 resolveRelation 方法中。
综上所述,最后,我们的自定义方式就是如下这种方式:
class Image extend MyRelationProvider implements DataSourceRegister {
}class MyRelationProvider implements RelationProvider {
}
我这里没有实现相应的方法。
如果读者有什么疑问,可以随时与我沟通!















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









