







目录
目标
能够串联两端, 理解整个流式应用, 以及其中的一些根本的原理, 比如说容错语义
能够知道如何对接外部系统, 写入数据
步骤
HDFS Sink
Kafka Sink
Foreach Sink自定义
Sink
Tiggers
Sink原理错误恢复和容错语义
5.1 HDFS Sink
目标
能够使用
Spark将流式数据的处理结果放入HDFS步骤
场景和需求
代码实现
5.1.1 场景和需求
场景:
-
Kafka往往作为数据系统和业务系统之间的桥梁 -
数据系统一般由批量处理和流式处理两个部分组成
-
在
Kafka作为整个数据平台入口的场景下, 需要使用StructuredStreaming接收Kafka的数据并放置于HDFS上, 后续才可以进行批量处理
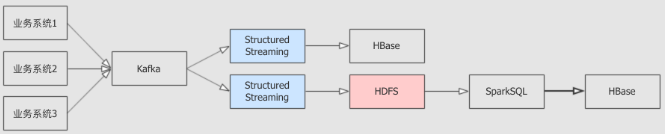
案例需求:
从 Kafka 接收数据, 从给定的数据集中, 裁剪部分列, 落地于 HDFS
5.1.2 代码实现
步骤说明:
-
从
Kafka读取数据, 生成源数据集-
连接
Kafka生成DataFrame -
从
DataFrame中取出表示Kafka消息内容的value列并转为String类型
-
-
对源数据集选择列
-
解析
CSV格式的数据 -
生成正确类型的结果集
-
-
落地
HDFS
整体代码:
import org.apache.spark.sql.{Dataset, SparkSession}
object HDFSSink {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark = SparkSession.builder()
.appName("hdfs_sink")
.master("local[6]")
.getOrCreate()
//2.读取kafka的数据
import spark.implicits._
val source = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","node01:9092,node02:9092,node03:9092")
.option("subscribe","streaming_test_1")
.option("startingOffsets","earliest")
.load()
.selectExpr("CAST(value AS STRING) as value")
.as[String]
//3. 处理CSV,Dataset(String),Dataset(id,name,category)
//1::Toy Story (1995)::Animation|Children's|Comedy
val result = source.map(item => {
val arr = item.split("::")
(arr(0).toInt,arr(1).toString,arr(2).toString)
}).as[(Int,String,String)].toDF("id","name","category")
//4.落地到HDFS中
result.writeStream
.format("parquet")
.option("path","dataset/streaming/moives")
.option("checkpointLocation", "checkpoint")
.start()
.awaitTermination()
}
}5.2 Kafka Sink
目标
掌握什么时候要将流式数据落地至 Kafka, 以及如何落地至 Kafka
步骤
场景
代码
5.2.1 场景
-
有很多时候,
ETL过后的数据, 需要再次放入Kafka -
在
Kafka后, 可能会有流式程序统一将数据落地到HDFS或者HBase
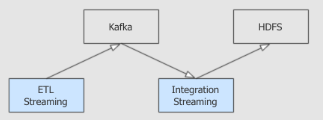
案例需求:从 Kafka 中获取数据, 简单处理, 再次放入 Kafka
5.2.2 代码
步骤
-
从
Kafka读取数据, 生成源数据集-
连接
Kafka生成DataFrame -
从
DataFrame中取出表示Kafka消息内容的value列并转为String类型
-
-
对源数据集选择列
-
解析
CSV格式的数据 -
生成正确类型的结果集
-
-
再次落地
Kafka
代码
import org.apache.spark.sql.streaming.OutputMode
import org.apache.spark.sql.{Dataset, SparkSession}
object KafkaSink {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "C:\\winutil")
// 1. 创建 SparkSession
val spark = SparkSession.builder()
.appName("hdfs_sink")
.master("local[6]")
.getOrCreate()
import spark.implicits._
// 2. 读取 Kafka 数据
val source: Dataset[String] = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092,node02:9092,node03:9092")
.option("subscribe", "streaming_test_2")
.option("startingOffsets", "earliest")
.load()
.selectExpr("CAST(value AS STRING) as value")
.as[String]
// 1::Toy Story (1995)::Animation|Children's|Comedy
// 3. 处理 CSV, Dataset(String), Dataset(id, name, category)
val result = source.map(item => {
val arr = item.split("::")
(arr(0).toInt, arr(1).toString, arr(2).toString)
}).as[(Int, String, String)].toDF("id", "name", "category")
// 4. 落地到 HDFS 中
result.writeStream
.format("kafka")
.outputMode(OutputMode.Append())
.option("checkpointLocation", "checkpoint")
.option("kafka.bootstrap.servers", "node01:9092,node02:9092,node03:9092")
.option("topic", "streaming_test_2")
.start()
.awaitTermination()
}
}5.3 Foreach Writer
目标
掌握
Foreach模式理解如何扩展Structured Streaming的Sink, 同时能够将数据落地到MySQL步骤
需求
代码
5.3.1 需求
场景:
-
大数据有一个常见的应用场景
-
收集业务系统数据
-
数据处理
-
放入
OLTP数据 -
外部通过
ECharts获取并处理数据
-
-
这个场景下,
StructuredStreaming就需要处理数据并放入MySQL或者MongoDB,HBase中以供Web程序可以获取数据, 图表的形式展示在前端
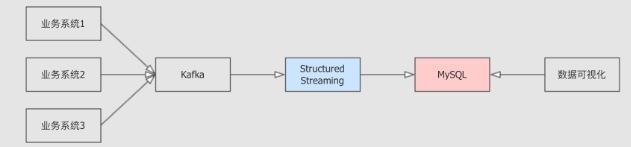
Foreach 模式:
起因
-
在
Structured Streaming中, 并未提供完整的MySQL/JDBC整合工具 -
不止
MySQL和JDBC, 可能会有其它的目标端需要写入 -
很多时候
Structured Streaming需要对接一些第三方的系统, 例如阿里云的云存储, 亚马逊云的云存储等, 但是Spark无法对所有第三方都提供支持, 有时候需要自己编写
解决方案

-
既然无法满足所有的整合需求,
StructuredStreaming提供了Foreach, 可以拿到每一个批次的数据 -
通过
Foreach拿到数据后, 可以通过自定义写入方式, 从而将数据落地到其它的系统
案例需求:

从 Kafka 中获取数据, 处理后放入 MySQL
5.3.2 代码
步骤:
创建
DataFrame表示Kafka数据源在源
DataFrame中选择三列数据创建
ForeachWriter接收每一个批次的数据落地MySQL
Foreach落地数据
代码:
import java.sql.{Connection, DriverManager, Statement}
import org.apache.spark.sql.{ForeachWriter, Row, SparkSession}
object ForeachSink {
def main(args: Array[String]): Unit = {
//1.创建SparkSession
val spark = SparkSession.builder()
.appName("hdfs_sink")
.master("local[6]")
.getOrCreate()
//2.读取kafka的数据
import spark.implicits._
val source = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","node01:9092,node02:9092,node03:9092")
.option("subscribe","streaming_test_1")
.option("startingOffsets","earliest")
.load()
.selectExpr("CAST(value AS STRING) as value")
.as[String]
//3. 处理CSV,Dataset(String),Dataset(id,name,category)
//1::Toy Story (1995)::Animation|Children's|Comedy
val result = source.map(item => {
val arr = item.split("::")
(arr(0).toInt,arr(1).toString,arr(2).toString)
}).as[(Int,String,String)].toDF("id","name","category")
//4.落地到MySQL
class MySQLWriter extends ForeachWriter[Row] {
private val driver = "com.mysql.sql.Driver"
private var connection: Connection = _
private val url = "jdbc::mysql//node01:3306/streaming-movies-result"
private var statement: Statement = _
override def open(partitionId: Long, version: Long): Boolean = {
Class.forName(driver)
connection = DriverManager.getConnection(url)
statement = connection.createStatement()
true
}
override def process(value: Row): Unit = {
statement.executeUpdate(s"insert into movies values(${value.get(0)},${value.get(1)},${value.get(2)})")
}
override def close(errorOrNull: Throwable): Unit = {
connection.close()
}
}
result.writeStream
.foreach(new MySQLWriter)
.start()
.awaitTermination()
}
}5.4 自定义 Sink
目标
Foreach倾向于一次处理一条数据, 如果想拿到DataFrame幂等的插入外部数据源, 则需要自定义Sink了解如何自定义
Sink步骤
Spark加载Sink流程分析自定义
Sink
5.4.1 Spark 加载 Sink 流程分析
Sink 加载流程
(1)writeStream 方法中会创建一个 DataStreamWriter 对象
def writeStream: DataStreamWriter[T] = {
if (!isStreaming) {
logicalPlan.failAnalysis(
"'writeStream' can be called only on streaming Dataset/DataFrame")
}
new DataStreamWriter[T](this)
}(2)在 DataStreamWriter 对象上通过 format 方法指定 Sink 的短名并记录下来
def format(source: String): DataStreamWriter[T] = {
this.source = source
this
}(3)最终会通过 DataStreamWriter 对象上的 start 方法启动执行, 其中会通过短名创建 DataSource
val dataSource =
DataSource(
df.sparkSession,
className = source,
options = extraOptions.toMap,
partitionColumns = normalizedParCols.getOrElse(Nil))(4)在创建 DataSource 的时候, 会通过一个复杂的流程创建出对应的 Source 和 Sink
lazy val providingClass: Class[_] = DataSource.lookupDataSource(className)(5)在这个复杂的创建流程中, 有一行最关键的代码, 就是通过 Java 的类加载器加载所有的 DataSourceRegister
val serviceLoader = ServiceLoader.load(classOf[DataSourceRegister], loader)(6)在 DataSourceRegister 中会创建对应的 Source 或者 Sink
trait DataSourceRegister {
def shortName(): String
}
trait StreamSourceProvider {
def createSource(
sqlContext: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source
}
trait StreamSinkProvider {
def createSink(
sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode): Sink
}- 提供短名
- 创建 Source
- 创建 Sink
自定义 Sink 的方式
-
根据前面的流程说明, 有两点非常重要
-
Spark会自动加载所有DataSourceRegister的子类, 所以需要通过DataSourceRegister加载Source和Sink -
Spark 提供了
StreamSinkProvider用以创建Sink, 提供必要的依赖
-
-
所以如果要创建自定义的
Sink, 需要做两件事-
创建一个注册器, 继承
DataSourceRegister提供注册功能, 继承StreamSinkProvider获取创建Sink的必备依赖 -
创建一个
Sink子类
-
5.4.2 自定义 Sink
步骤
读取
Kafka数据简单处理数据
创建
Sink创建
Sink注册器使用自定义
Sink
代码
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("kafka integration")
.getOrCreate()
import spark.implicits._
val source = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node01:9092,node02:9092,node03:9092")
.option("subscribe", "streaming-bank")
.option("startingOffsets", "earliest")
.load()
.selectExpr("CAST(value AS STRING)")
.as[String]
val result = source.map {
item =>
val arr = item.replace("\"", "").split(";")
(arr(0).toInt, arr(1).toInt, arr(5).toInt)
}
.as[(Int, Int, Int)]
.toDF("age", "job", "balance")
class MySQLSink(options: Map[String, String], outputMode: OutputMode) extends Sink {
override def addBatch(batchId: Long, data: DataFrame): Unit = {
val userName = options.get("userName").orNull
val password = options.get("password").orNull
val table = options.get("table").orNull
val jdbcUrl = options.get("jdbcUrl").orNull
val properties = new Properties
properties.setProperty("user", userName)
properties.setProperty("password", password)
data.write.mode(outputMode.toString).jdbc(jdbcUrl, table, properties)
}
}
class MySQLStreamSinkProvider extends StreamSinkProvider with DataSourceRegister {
override def createSink(sqlContext: SQLContext,
parameters: Map[String, String],
partitionColumns: Seq[String],
outputMode: OutputMode): Sink = {
new MySQLSink(parameters, outputMode)
}
override def shortName(): String = "mysql"
}
result.writeStream
.format("mysql")
.option("username", "root")
.option("password", "root")
.option("table", "streaming-bank-result")
.option("jdbcUrl", "jdbc:mysql://node01:3306/test")
.start()
.awaitTermination()5.5 Tigger
目标
掌握如何控制
StructuredStreaming的处理时间步骤
微批次处理
连续流处理
5.5.1 微批次处理
(1)什么是微批次

并不是真正的流, 而是缓存一个批次周期的数据, 后处理这一批次的数据
(2)通用流程
步骤
-
根据
Spark提供的调试用的数据源Rate创建流式DataFrame-
Rate数据源会定期提供一个由两列timestamp, value组成的数据,value是一个随机数
-
-
处理和聚合数据, 计算每个个位数和十位数各有多少条数据
-
对
value求log10即可得出其位数 -
后按照位数进行分组, 最终就可以看到每个位数的数据有多少个
-
代码
val spark = SparkSession.builder()
.master("local[6]")
.appName("socket_processor")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
spark.sparkContext.setLogLevel("ERROR")
val source = spark.readStream
.format("rate")
.load()
val result = source.select(log10('value) cast IntegerType as 'key, 'value)
.groupBy('key)
.agg(count('key) as 'count)
.select('key, 'count)
.where('key.isNotNull)
.sort('key.asc)(3)默认方式划分批次
介绍
默认情况下的 Structured Streaming 程序会运行在微批次的模式下, 当一个批次结束后, 下一个批次会立即开始处理
步骤
-
指定落地到
Console中, 不指定Trigger
代码
result.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.start()
.awaitTermination()(4)按照固定时间间隔划分批次
介绍
使用微批次处理数据, 使用用户指定的时间间隔启动批次, 如果间隔指定为 0, 则尽可能快的去处理, 一个批次紧接着一个批次
-
如果前一批数据提前完成, 待到批次间隔达成的时候再启动下一个批次
-
如果前一批数据延后完成, 下一个批次会在前面批次结束后立即启动
-
如果没有数据可用, 则不启动处理
步骤
-
通过
Trigger.ProcessingTime()指定处理间隔
代码
result.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start()
.awaitTermination()(5)一次性划分批次
介绍
只划分一个批次, 处理完成以后就停止 Spark 工作, 当需要启动一下 Spark 处理遗留任务的时候, 处理完就关闭集群的情况下, 这个划分方式非常实用
步骤
-
使用
Trigger.Once一次性划分批次
代码
result.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.trigger(Trigger.Once())
.start()
.awaitTermination()5.5.2 连续流处理
(1)介绍
-
微批次会将收到的数据按照批次划分为不同的
DataFrame, 后执行DataFrame, 所以其数据的处理延迟取决于每个DataFrame的处理速度, 最快也只能在一个DataFrame结束后立刻执行下一个, 最快可以达到100ms左右的端到端延迟 -
而连续流处理可以做到大约
1ms的端到端数据处理延迟 -
连续流处理可以达到
at-least-once的容错语义 -
从
Spark 2.3版本开始支持连续流处理, 我们所采用的2.2版本还没有这个特性, 并且这个特性截止到2.4依然是实验性质, 不建议在生产环境中使用
(2)操作
步骤
-
使用特殊的
Trigger完成功能
代码
result.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.trigger(Trigger.Continuous("1 second"))
.start()
.awaitTermination()(3)限制
-
只支持
Map类的有类型操作 -
只支持普通的的
SQL类操作, 不支持聚合 -
Source只支持Kafka -
Sink只支持Kafka,Console,Memory
5.6 从 Source 到 Sink 的流程
目标
理解
Source到Sink的整体原理步骤
从
Source到Sink的流程
Source 到 Sink 的流程

-
在每个
StreamExecution的批次最开始,StreamExecution会向Source询问当前Source的最新进度, 即最新的offset -
StreamExecution将Offset放到WAL里 -
StreamExecution从Source获取start offset,end offset区间内的数据 -
StreamExecution触发计算逻辑logicalPlan的优化与编译 -
计算结果写出给
Sink-
调用
Sink.addBatch(batchId: Long, data: DataFrame)完成 -
此时才会由
Sink的写入操作开始触发实际的数据获取和计算过程
-
-
在数据完整写出到
Sink后,StreamExecution通知Source批次id写入到batchCommitLog, 当前批次结束
5.7 错误恢复和容错语义
目标
理解
Structured Streaming中提供的系统级别容错手段步骤
端到端
三种容错语义
Sink的容错
5.7.1 端到端

-
Source可能是Kafka,HDFS -
Sink也可能是Kafka,HDFS,MySQL等存储服务 -
消息从
Source取出, 经过Structured Streaming处理, 最后落地到Sink的过程, 叫做端到端
5.7.2 三种容错语义
(1)at-most-once
-
在数据从
Source到Sink的过程中, 出错了,Sink可能没收到数据, 但是不会收到两次, 叫做at-most-once -
一般错误恢复的时候, 不重复计算, 则是
at-most-once
(2)at-least-once
-
在数据从
Source到Sink的过程中, 出错了,Sink一定会收到数据, 但是可能收到两次, 叫做at-least-once -
一般错误恢复的时候, 重复计算可能完成也可能未完成的计算, 则是
at-least-once
(3)exactly-once
-
在数据从
Source到Sink的过程中, 虽然出错了,Sink一定恰好收到应该收到的数据, 一条不重复也一条都不少, 即是exactly-once -
想做到
exactly-once是非常困难的
5.7.3 Sink 的容错

(1)故障恢复一般分为 Driver 的容错和 Task 的容错
-
Driver的容错指的是整个系统都挂掉了 -
Task的容错指的是一个任务没运行明白, 重新运行一次
(2)因为 Spark 的 Executor 能够非常好的处理 Task 的容错, 所以我们主要讨论 Driver 的容错, 如果出错的时候
-
读取
WAL offsetlog恢复出最新的offsets当
StreamExecution找到Source获取数据的时候, 会将数据的起始放在WAL offsetlog中, 当出错要恢复的时候, 就可以从中获取当前处理批次的数据起始, 例如Kafka的Offset -
读取
batchCommitLog决定是否需要重做最近一个批次当
Sink处理完批次的数据写入时, 会将当前的批次ID存入batchCommitLog, 当出错的时候就可以从中取出进行到哪一个批次了, 和WAL对比即可得知当前批次是否处理完 -
如果有必要的话, 当前批次数据重做
-
如果上次执行在
(5)结束前即失效, 那么本次执行里Sink应该完整写出计算结果 -
如果上次执行在
(5)结束后才失效, 那么本次执行里Sink可以重新写出计算结果 (覆盖上次结果), 也可以跳过写出计算结果(因为上次执行已经完整写出过计算结果了)
-
-
这样即可保证每次执行的计算结果, 在 Sink 这个层面, 是 不重不丢 的, 即使中间发生过失效和恢复, 所以
Structured Streaming可以做到exactly-once
5.7.4 容错所需要的存储
(1)存储
-
offsetlog和batchCommitLog关乎于错误恢复 -
offsetlog和batchCommitLog需要存储在可靠的空间里 -
offsetlog和batchCommitLog存储在Checkpoint中 -
WAL其实也存在于Checkpoint中
(2)指定 Checkpoint
只有指定了 Checkpoint 路径的时候, 对应的容错功能才可以开启
aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()指定 Checkpoint 的路径, 这个路径对应的目录必须是 HDFS 兼容的文件系统
5.7.5 需要的外部支持
如果要做到 exactly-once, 只是 Structured Streaming 能做到还不行, 还需要 Source 和 Sink 系统的支持
如果要做到 exactly-once, 只是 Structured Streaming 能做到还不行, 还需要 Source 和 Sink 系统的支持
-
Source需要支持数据重放当有必要的时候,
Structured Streaming需要根据start和end offset从Source系统中再次获取数据, 这叫做重放 -
Sink需要支持幂等写入如果需要重做整个批次的时候,
Sink要支持给定的ID写入数据, 这叫幂等写入, 一个ID对应一条数据进行写入, 如果前面已经写入, 则替换或者丢弃, 不能重复
所以 Structured Streaming 想要做到 exactly-once, 则也需要外部系统的支持, 如下
Source
|
| 是否可重放 | 原生内置支持 | 注解 |
|
| 可以 | 已支持 | 包括但不限于 |
|
| 可以 | 已支持 |
|
|
| 可以 | 已支持 | 以一定速率产生数据 |
| RDBMS | 可以 | 待支持 | 预计后续很快会支持 |
| Socket | 不可以 | 已支持 | 主要用途是在技术会议和讲座上做 |
Sink
|
| 是否幂等写入 | 原生内置支持 | 注解 |
|
| 可以 | 支持 | 包括但不限于 |
|
| 可以 | 支持 | 可定制度非常高的 |
|
| 可以 | 待支持 | 预计后续很快会支持 |
|
| 不可以 | 支持 |
|















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









