






 本文介绍了一种爬取特定用户微博数据的方法,包括点赞数、评论数、转发数等,并进行了初步的数据分析,探讨了文本长度与互动数之间的关系。
本文介绍了一种爬取特定用户微博数据的方法,包括点赞数、评论数、转发数等,并进行了初步的数据分析,探讨了文本长度与互动数之间的关系。
目的:爬取易烊千玺的微博,包括:点赞数、评论数、转发数、发布时间、微博正文长度、每次的微博id
结果呈现:屏幕显示爬取完成;相应的文件夹的生成
注:此时进行简单的数据分析-------文本长度、点赞数、评论数、转发数的关系---->简单的数据分析
注:易烊千玺这个宝藏男孩!是我的命啊!简直爱到不能自已!!!帅,而且话少!我的菜!!!动不动就上热搜~心水他❤~
注:信息存储在xhr文件中,就是Ajax请求~
易烊千玺微博:https://m.weibo.cn/u/3623353053
#下面为本实例的爬虫代码,若有问题可以给我留言,或者有更好的解决方法也可以私信我~
import os
import csv
import requests
import json
def get_page(page):
base_url='https://m.weibo.cn/api/container/getIndex'
params={
'type':'uid',
'value':'3623353053', #主页的id
'containerid':'1076033623353053', #107603+主页的id
'page':page
}
headers={'user-agent':'Mozilla/5.0'}
try:
r=requests.get(base_url,params=params,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except Exception as e:
print(e)
def parse_page(page):
html=get_page(page)
info_data=json.loads(html)
info=info_data['data']['cards']
for item in info:
try:
mblog=item['mblog']
user_id=mblog['user']['screen_name'] #微博id
#text=mblog['text'] #微博id的内容 【太乱了,就不进行正则表达式的提取了】
text_len=mblog['textLength'] #文本长度
attitudes_count=mblog['attitudes_count'] #点赞数
comments_count=mblog['comments_count'] #评论数
reposts_count=mblog['reposts_count'] #转发数
created_at=mblog['created_at'] #发布时间
#bmiddle_pic=mblog['bmiddle_pic'] #图片,并不是所有微博都有的
result=[user_id,text_len,attitudes_count,comments_count,reposts_count,created_at]
save_to_csv(result)
except:
continue
print('{}---第{}页---?'.format(user_id,page))
def save_to_csv(res):
file='YYQX.csv'
with open(file,'a+',encoding='utf-8',newline="")as csv_file:
csv_write=csv.writer(csv_file)
if os.path.getsize(file)==0:
csv_write.writerow(['用户id','文本长度','点赞数','评论数','转发数','发布时间'])
csv_write.writerow(res)
csv_file.close()
if __name__ == '__main__':
for page in range(1,51): #爬取前50页
parse_page(page)
(1)屏幕显示:
(2)文件夹显示:

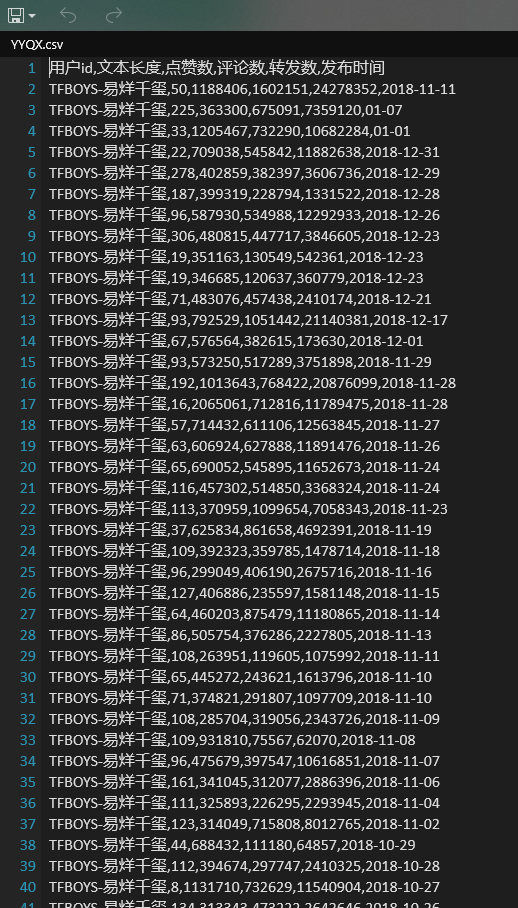
爬取成功!
简单的数据分析
下面进行简单的数据分析,通过绘图,看下:文本长度、点赞数、评论数、转发数的关系
- 需要对其进行归一化,不然的话,数据之间相差太大,不具备可比性!
- 选取前100条微博进行比较,不然的话,数据都堆在一起,看不清规律!
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties #中文字符的解决
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
#读入数据
data=pd.read_csv('E:\YYQX.csv')
text_len=data['文本长度']
attitudes_count=data['点赞数']
comments_count=data['评论数']
reposts_count=data['转发数']
#数据处理:选取前100;归一化
text_len=text_len[:100]
text_len=text_len/max(text_len) #文本长度 【红色】
attitudes_count=attitudes_count[:100]
attitudes_count=attitudes_count/max(attitudes_count) #点赞数【蓝色】
comments_count=comments_count[:100]
comments_count=comments_count/max(comments_count) #评论数 【绿色】
reposts_count=reposts_count[:100]
reposts_count=reposts_count/max(reposts_count) #转发数 【紫色】
text_len.plot(label='文本长度',style="--",color='r')
attitudes_count.plot(label='点赞数',style='--',color='b')
comments_count.plot(label='评论数',style='--',color='g')
reposts_count.plot(label='转发数',style='--',color='y')
plt.title(u'易烊千玺微博分析', fontproperties=font) #题目自行修改
plt.legend(prop=font)
plt.show()
图片如下:
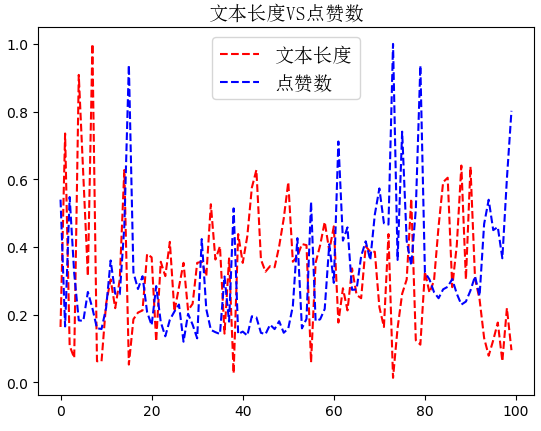
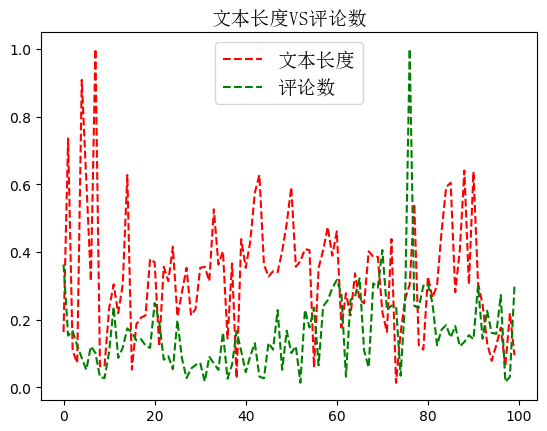
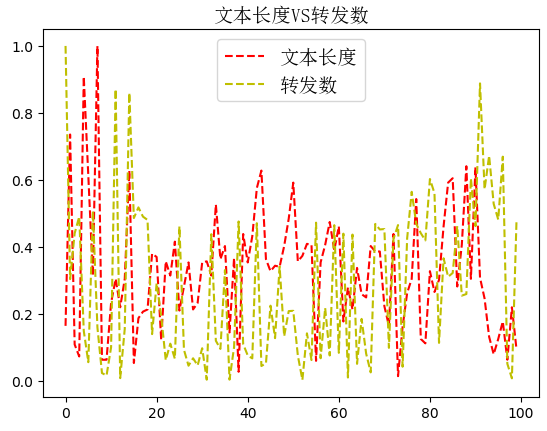
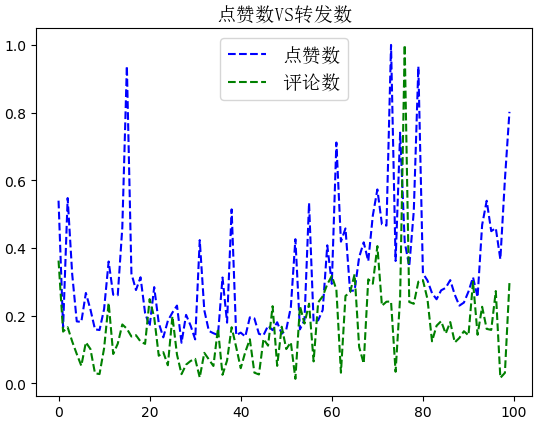
分析这些发现:文本长度和点赞数、评论数、评论数没有关系!但是点赞数和转发数正相关!
注:这是简单的数据分析,时候做使用sklearn库进行一些机器学习的分析!
注:易烊千玺,我真的很喜欢他!首先:长得好看!其次:舞跳得好!最重要的是:性格啊!!!!冷都男!!!!--->附上一张黑历史!【我觉得很可爱~(@^_^@)~】

今日爬虫&简单的数据分析完成!
今日鸡汤:勇敢地去选择你想要过的生活,并坚持下去,这就是一种很棒的人生,致自己!
加油ヾ(◍°∇°◍)ノ゙


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









