






目的:爬取Booking上南京宾馆的信息,包括:店名、类型、等级、得分、地址、简介
结果呈现:保存在txt文件中
注:这个例子很简单,我就是用来练手的,主要锻炼自己写“面向对象”的能力!
Booking上南京宾馆的网址:https://www.booking.com/searchresults.zh-cn.html?aid=1212292;label=baidu-XpLADcjfSTr7D4LLteQtiQ-18879116270;sid=209dee09ca1ea9e50aee88346356e85b;city=-1919548;from_idr=1&;ilp=1;d_dcp=1
删减完为:https://www.booking.com/searchresults.zh-cn.html?city=-1919548
翻页是通过offset参数,每次传入15个。
#下面为本实例的爬虫代码,若有问题可以给我留言,或者有更好的解决方法也可以私信我~
【面向过程】
import requests
from bs4 import BeautifulSoup
def get_page(url):
headers={'user-agent':'Mozilla/5.0'}
try:
r=requests.get(url,headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except Exception as e:
print(e)
def get_num(url):
html=get_page(url)
soup=BeautifulSoup(html,'html.parser')
ul=soup.find_all('ul',{'class':{'bui-pagination__list'}})[-1]
num=ul('li')[-1].text.strip()
return int(num) #32
def get_info(url):
html=get_page(url)
soup=BeautifulSoup(html,'html.parser')
divs=soup.find_all('div',{'class':{'sr_item_default'}})
for div in divs:
info1=div.find('span',{'class':{'sr-hotel__name'}})
name=info1.text.strip() #店名
try:
info2=div.find('span',{'class':{'china_stars_categories_title'}})
style=info2.text.strip() #类型
except:
style='未知'
level=div['data-class'] #等级
score=div['data-score'] #得分
if score=='':
score='未知'
info3=div.find('div',{'class':{'address'}})
address=info3.text.strip().replace('\n','') #地址
info4=div.find('div',{'class':{'hotel_desc'}})
desc=info4.text.strip() #简介
with open('Booking_南京.txt','a+',encoding='utf8')as f:
f.write('店名:'+name+'\n')
f.write('类型:'+style+'\n')
f.write('等级:'+level+'\n')
f.write('得分:'+score+'\n')
f.write('地址:'+address+'\n')
f.write('简介:'+desc+'\n')
f.write('\n')
f.close()
print('{}-----(* ̄︶ ̄)'.format(name))
if __name__ == '__main__':
start_url='https://www.booking.com/searchresults.zh-cn.html?city=-1919548'
num=get_num(start_url)
for i in range(num):
page_url=start_url+'&offset='+str(i*15)
get_info(page_url)
(1)屏幕显示:
(2)文本显示:
![]()
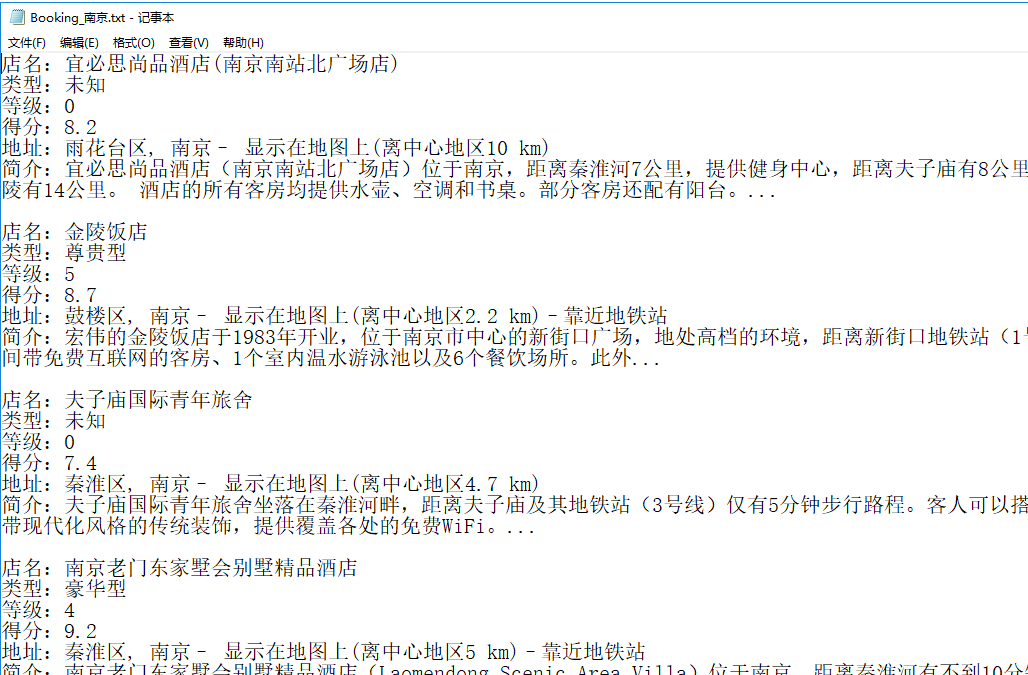
面向过程爬取完成!
---------(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)----------
【面向对象】
import requests
from bs4 import BeautifulSoup
class Booking():
def __init__(self,start_url):
self.start_url=start_url
def get_page(self,url):
headers = {'user-agent': 'Mozilla/5.0'}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
def get_num(self):
html=self.get_page(self.start_url)
soup=BeautifulSoup(html,'html.parser')
ul=soup.find_all('ul',{'class':{'bui-pagination__list'}})[-1]
num=ul('li')[-1].text.strip()
return int(num) #32
def get_info(self):
num=self.get_num()
for i in range(num):
page_url = self.start_url + '&offset=' + str(i * 15)
html=self.get_page(page_url)
soup=BeautifulSoup(html,'html.parser')
divs=soup.find_all('div',{'class':{'sr_item_default'}})
for div in divs:
info1=div.find('span',{'class':{'sr-hotel__name'}})
name=info1.text.strip() #店名
try:
info2=div.find('span',{'class':{'china_stars_categories_title'}})
style=info2.text.strip() #类型
except:
style='未知'
level=div['data-class'] #等级
score=div['data-score'] #得分
if score=='':
score='未知'
info3=div.find('div',{'class':{'address'}})
address=info3.text.strip().replace('\n','') #地址
info4=div.find('div',{'class':{'hotel_desc'}})
desc=info4.text.strip() #简介
with open('Booking_南京_面向对象.txt','a+',encoding='utf8')as f:
f.write('店名:'+name+'\n')
f.write('类型:'+style+'\n')
f.write('等级:'+level+'\n')
f.write('得分:'+score+'\n')
f.write('地址:'+address+'\n')
f.write('简介:'+desc+'\n')
f.write('\n')
f.close()
print('{}-----(* ̄︶ ̄)'.format(name))
nj_url='https://www.booking.com/searchresults.zh-cn.html?city=-1919548'
B=Booking(nj_url)
B.get_info()
(1)屏幕显示:

(2)文本显示:

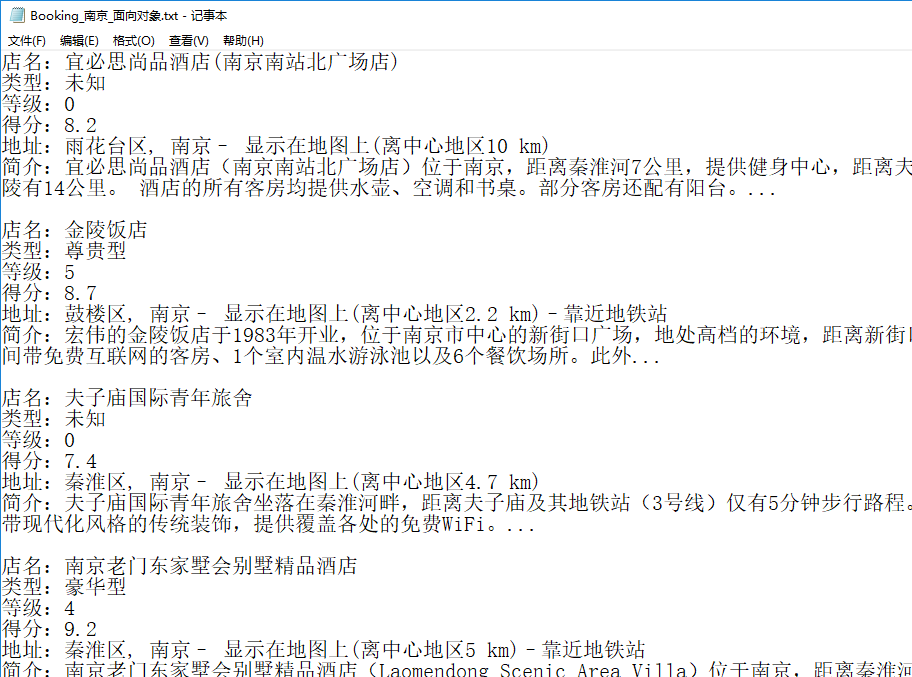
面向对象爬取完成!
---------(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)----------
注:以后写代码都要写成面向对象的形式!
今日爬虫完成!
今日鸡汤:你勤奋充电,你努力工作,你保持身材,你对人微笑,这些都不是为了取悦他人,而是为了扮靓自己,照亮自己的心,告诉自己:我是一股独立向上的力量。
加油ヾ(◍°∇°◍)ノ゙

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









