






要抓取淘宝店铺的内容只能是通过传过来的淘宝URL来抓取。所以我们先要有一个URL。
有了URL之后就可以开始抓取工作了。根据URL的域名不同需要把URL分成两个部分,一个是淘宝的店铺,一个是天猫的店铺。截取URL的域名这里就不说了,大家不会的自行百度。之所以这么做是因为淘宝和天猫的店铺DOM结构是不一样的。
先说简单的天猫。
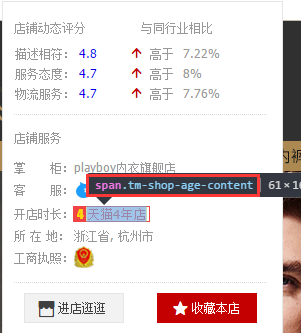
天猫的店铺等级在一个class名为tm-shiop-age-content中,所以用phpQuery的pq('.tm-shiop-age-content')->text()可以直接获取天猫店铺的等级。
然后就是店铺的评分。

天猫店铺的评分是在一个class为main-info的div中,所以也是直接pq('.main-info')->text()就可以了,返回的数据会是“描述4.8服务4.7物流4.7”这样的数据。
下面说比较麻烦的淘宝。
首先淘宝的店铺等级分为多种,比如皇冠、钻石等等,而且这些等级前面还有数量。先看一下淘宝店铺的店铺等级能在页面上哪里能找到:

等级信息在这里,第一个和第三个class是固定的,变化的是第二个class,都是形如tb-rank-xxx的形式,其中的对应关系:
crown:金冠
cap:皇冠
blue:钻石
red:红心
所以我们要根据这个class的不同的值来获取淘宝店铺的等级。
pq('.shop-rank .rank-icon-v2')->attr('class'),我们先把这个class里面的值拿过来。注意要从它的上一级,shiop-rank取,因为企业店铺的等级在页面上出现了两次,而我们只需要一个就够了。
接下来还要获取这个等级前的数量。
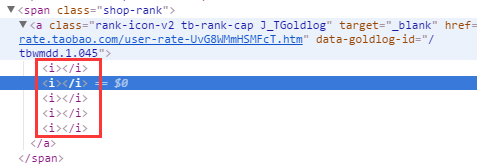
这个a标签里面的i的数量就对应了对应等级的数量。那我们就把a标签里的i标签也获取到:pq('.shop-rank .rank-icon-v2')->html()。
有了这两个东西我们就ok了,编写一个函数处理这两个内容,返回我们能看懂的店铺等级的值:
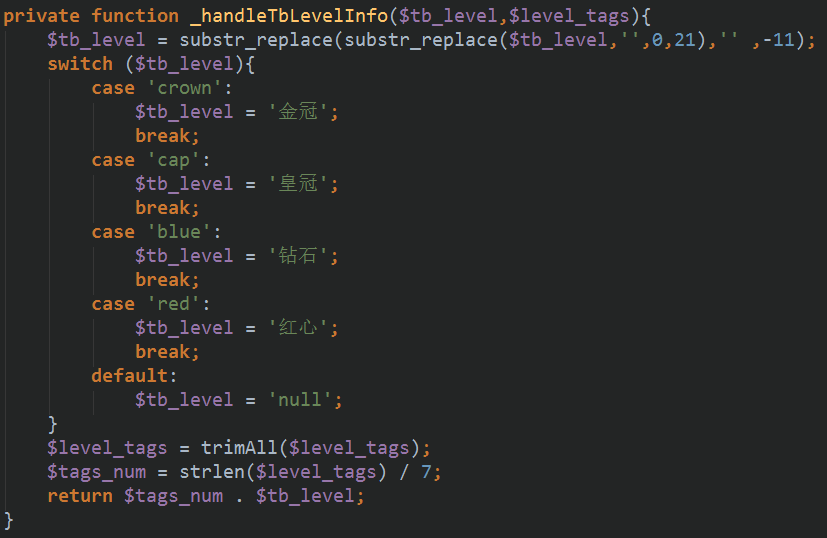
trimAll函数是替换抓取到的HTML页面中的空格的,我的上一篇抓取百度数据的博客中有这个函数,这里就不再贴一遍了。
最后我们会得到这样的数据:5皇冠。
然后就是抓取淘宝店铺的评分了。

淘宝店铺的评分在一个class为mini-dsr的a标签当中,我们直接获取这个标签当中的文本:pq('.mini-dsr')->text()。
抓取下来会发现变成了乱码。这是因为淘宝的页面编码是gbk,而phpQuery只认识GBK2312并不认识GBK,会帮我们自动转化为ISO-8859-1的编码,所以还需要讲抓取下来的数据转换一下编码。
先将数据转化为utf8,然后再转会GBK2312就OK了。
$str = mb_convert_encoding($str,'ISO-8859-1','utf-8');
$str = mb_convert_encoding($str,'utf-8','GBK');
这样我们就得到了上面天猫一样的评分数据了。
这是以上我在抓取的时候的方法以及遇到的问题,欢迎其他小伙伴有更好的方法一起讨论。















 3023
3023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









