






前几天在写WORKS APPLICATIONS的两题笔试题,就没空写博客了。现在写完了,先分享一下第一个题Magic Cube里遇到的知识点“引用和clone方法”。详细的题解请关注后续博客。
先来说说我是怎么遇到这个知识点的,在解题过程中,我写了一个包含三维数组的类和一个递归方法,大概如下:
publicclassCube{
privateintlen;//立方体边长
privateint[][][] cells;//立方体点阵
publicCube(intlen,int[][][] cells){
this.len = len;
this.cells = cells;
}
//省略一些代码
publicstaticvoidmain(String[] args){
//省略一些代码
Scanner sc = newScanner(System.in);
intN = sc.nextInt();
Cube[] smallCubes = newCube[N];
for(inti =0; i < N; i++) {
intlen = sc.nextInt();
Ns = newint[len][len][len];
System.out.println(Ns);//获取Ns的哈希码
for(intj =0; j < len; j++) {
for(intk =0; k < len; k++) {
for(intl =0; l < len; l++) {
Ns[j][k][l] = sc.nextInt();
}
}
}
smallCubes[i] = newCube(len, Ns);
System.out.println(smallCubes[i].cells);//获取smallCubes[i].cells的哈希码
}
}
}运行后会发现两次输出的哈希码一样,如果有多组数据(N>1),那么你会发现每组数据输出两个相同的哈希码,组与组之间的哈希码不同。每组数据同样是Ns,地址却不同,这是为什么呢?别急,我们先保留这个疑惑,看看下面的情况。
因为解题需求,这时候我需要复制一个立方体:
Cube c1 = newCube(1,newint[][][]{{{1}}});
Cube c2 = c1;
System.out.println(c1);
System.out.println(c2);//这两句输出的哈希码一样
c1.cells[0][0][0]++;
System.out.println(c2.cells[0][0][0]);//输出2这样“复制”肯定不行,c2和c1的哈希码是一样的,即c2是指向c1的引用,改变c1的值c2的也被改变。
那上述传Ns值的时候为什么每组的Ns的哈希码不一样呢?原来是new关键字,new出来的对象都是Heap上一块新内存。JVM把程序申请的内存从逻辑上划分为四个部分,如下: 
然后我们结合代码和图示来分析一下程序运行时JVM中内存的动作
String s1 = "123";//"123"被放入String池,JVM自动new字符串对象o指向"123",s1指向o
String s2 = "123";//String池中存在"123",s2指向o
String s3 = newString("123");//String池中存在"123",s2指向"123"
System.out.println(s1 == s2);//true s1和s2引用同一个对象
System.out.println(s1 == s3);//false s1和s3引用不同对象
System.out.println(s1.equals(s3));//true s1和s3值相同 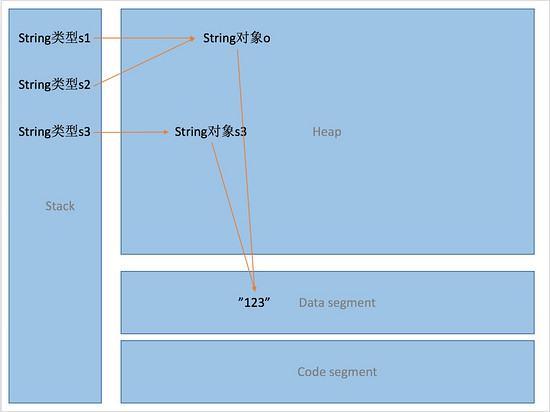
同理,Cube类和其中cells三维数组在main函数中的内存分析如下: 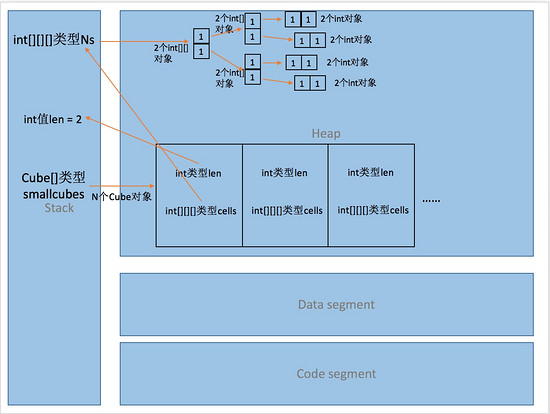
再看之前的代码:
for(inti =0; i < N; i++) {
intlen = sc.nextInt();
Ns = newint[len][len][len];
for(intj =0; j < len; j++) {
for(intk =0; k < len; k++) {
for(intl =0; l < len; l++) {
Ns[j][k][l] = sc.nextInt();
}
}
}
//每次传进去的Ns都是new出来的不一样的,这里每个smallCube也是new出来的不一样的
smallCubes[i] = newCube(len, Ns);
} 之前的疑惑“那传Ns值的时候为什么每组的Ns的哈希码不一样呢?”,这段代码里,每遍循环Ns都会被new分配到一块新的内存,所以每遍的Ns互相不会影响,所以每个smallCube都是独立的互不影响的。为了看的清楚点,这里我只举了两个例子。 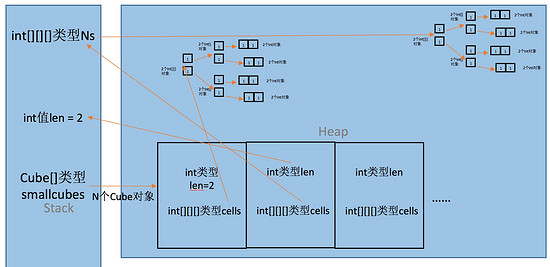
现在我们可以回过头来考虑复制Cube对象时出现的问题了。
Cube c1 = newCube(1,newint[][][]{{{1}}});
Cube c2 = c1;
System.out.println(c1);
System.out.println(c2);//这两句输出的哈希码一样
c1.cells[0][0][0]++;
System.out.println(c2.cells[0][0][0]);//输出2 还是这段代码,现在我们可以画图,直观地说明为什么c1和c2的哈希码一样,而且改变c1.cells的值,c2.cells的值也会随之改变了。简单来说就是c1和c2指向了同一个引用对象。 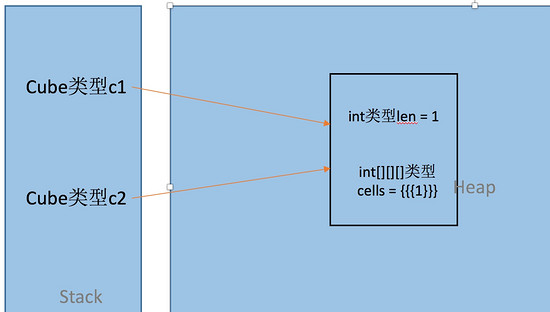
那么我们想达到的复制效果应该是这样的: 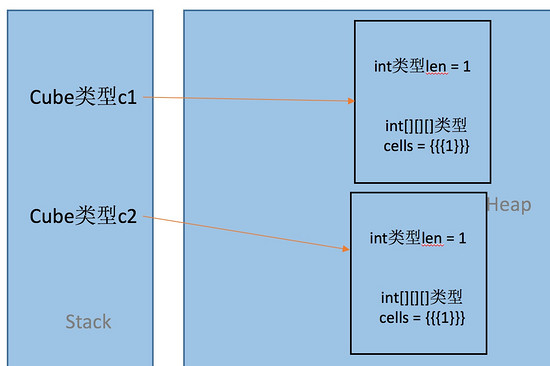
这里就不得不介绍Java提供给我们的java.lang包里面Object类的clone方法: 
protected Object clone()
throws CloneNotSupportedException
创建并返回此对象的一个副本。“副本”的准确含义可能依赖于对象的类。这样做的目的是,对于任何对象 x,表达式:
x.clone() != x
为 true,表达式:
x.clone().getClass() == x.getClass()
也为 true,但这些并非必须要满足的要求。一般情况下:
x.clone().equals(x)
为 true,但这并非必须要满足的要求。
按照惯例,返回的对象应该通过调用 super.clone 获得。如果一个类及其所有的超类(Object 除外)都遵守此约定,则 x.clone().getClass() == x.getClass()。
按照惯例,此方法返回的对象应该独立于该对象(正被复制的对象)。要获得此独立性,在 super.clone 返回对象之前,有必要对该对象的一个或多个字段进行修改。这通常意味着要复制包含正在被复制对象的内部“深层结构”的所有可变对象,并使用对副本的引用替换对这些对象的引用。如果一个类只包含基本字段或对不变对象的引用,那么通常不需要修改 super.clone 返回的对象中的字段。
Object 类的 clone 方法执行特定的复制操作。首先,如果此对象的类不能实现接口 Cloneable,则会抛出 CloneNotSupportedException。注意,所有的数组都被视为实现接口 Cloneable。否则,此方法会创建此对象的类的一个新实例,并像通过分配那样,严格使用此对象相应字段的内容初始化该对象的所有字段;这些字段的内容没有被自我复制。所以,此方法执行的是该对象的“浅表复制”,而不“深层复制”操作。
Object 类本身不实现接口 Cloneable,所以在类为 Object 的对象上调用 clone 方法将会导致在运行时抛出异常。
返回:
此实例的一个副本。
抛出:
CloneNotSupportedException - 如果对象的类不支持 Cloneable 接口,则重写 clone 方法的子类也会抛出此异常,以指示无法复制某个实例。所以我们来尝试实现Cloneable接口重写一下clone方法:
publicclassCubeimplementsCloneable{
privateintlen;
privateint[][][] cells;
publicCube(intlen,int[][][] cells){
this.len = len;
this.cells = cells;
}
@Override
publicCubeclone()throwsCloneNotSupportedException{
return(Cube)super.clone();
}
publicstaticvoidmain(String[] args){
Cube c1 = newCube(1,newint[][][]{{{1}}});
Cube c2 = c1.clone;
System.out.println(c1);
System.out.println(c2);//这两句输出的哈希码终于不一样了
c1.cells[0][0][0]++;
System.out.println(c2.cells[0][0][0]);//输出的竟然还是2
}
}这不可能啊,明明调用了clone方法,怎么得到的c2还是与c1引用了同一个对象。
经过搜索查阅得知,原来clone分shallow Clone(浅克隆)和deep Clone(深克隆)两种,其区别在于:对于被克隆的对象,若使用shallow Clone,则基本数据类型的成员被复制的是值,而含引用的成员被复制的是引用;若使用deep Clone,则所有成员都是以值被复制。
从前面的内存分析中我们得知Cube类中的int成员len是基本数据类型的,而三维整型数组cells则是引用类型,所以上面调用super.clone()时实现的是浅克隆,内存分析如下图: 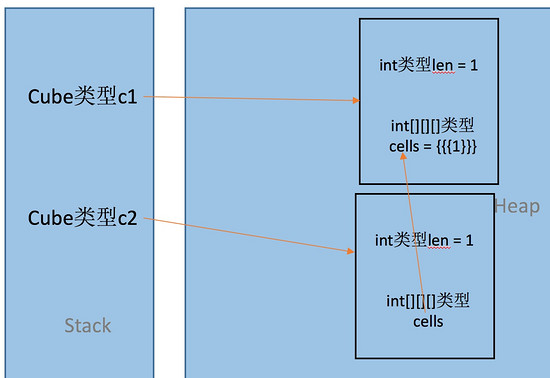
明白原因以后就简单了,现在我们来实现Cube类的deep Clone(深克隆):
@Override
publicCubeclone()throwsCloneNotSupportedException{
int[][][] cells =newint[len][len][len];
for(inti =0; i < len; i++) {
for(intj =0; j < len; j++) {
System.arraycopy(this.cells[i][j],0, cells[i][j],0, len);
//注意:多维数组本身的深克隆是对其最深维进行数组拷贝
//当然,new出一块新内存后也可以一个一个重新赋值
System.arraycopy(this.cells[i][j],0, cells[i][j],0, len);
// for (int k = 0; k < len; k++) {
// cells[i][j][k] = this.cells[i][j][k];
// }
}
}
returnnewCube(len, cells);
}
publicstaticvoidmain(String[] args){
Cube c1 = newCube(1,newint[][][]{{{1}}});
Cube c2 = c1.clone;
System.out.println(c1);
System.out.println(c2);//这两句输出的哈希不一样
c1.cells[0][0][0]++;
System.out.println(c2.cells[0][0][0]);//输出的终于是1了
System.out.println(c1.cells[0][0][0]);//输出2
}今天的分享就到此结束了,最后用两句话总结一下clone的用法:
1、什么时候使用shallow Clone,什么时候使用deep Clone,这个主要看具体对象的成员是什么性质的,基本类型还是引用类型
2、调用Clone()方法的对象所属的类必须实现Clonable接口















 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









