






Splunk数据检索概要
0.提要
Splunk Enterprise的强悍之处基本上全部体现在其强大的数据检索功能上。不同于传统的事件数据管理工具,其将“自身之于事件数据内容”与“Google之于WWW数据内容”相提并论。
本文就Splunk中的数据检索特性涉及的功能界面、检索命令、交互机制等方面作以概要介绍。
1.数据检索
1.1 前序准备
在使用Splunk进行数据检索之前,应当了解以下内容:
- 了解如何导入数据
- 了解数据管理基本概念
- 了解知识对象基本概念
(上述内容参见《Splunk数据处理概要》)
1.2 检索界面
Splunk Enterprise将会在系统中启动Splunkd进程提供数据检索服务。通常情况下,用户连接该服务的途径有三种:
- Splunk Web
- CLI
- REST API
1.2.1 Splunk Web
Splunk Web是最常用的功能界面。该界面由运行在Splunkd进程中的splunkweb模块提供。用户通过Web浏览器访问,即可进行图形化功能操作。
1.2.2 CLI
Splunk提供了命令行操作界面。该界面对应的可执行程序位于<code>$SPLUNK_HOME/bin/splunk</code>。使用该程序可以访问本地或者远程的Splunk服务。该界面通常情况下都不会被用到。
1.2.3 REST API
Splunk提供了几乎全功能的REST API。使用最简单的curl工具即可连接进行任何操作。放眼当前大部分的流行的技术产品,这种设计也是大势所趋(摈弃面向任何具体语言的SDK包,直接通过Web工具访问)。
至少在笔者试用的6.2.1版本中,可确定使用Splunk Web的时候,浏览器端的操作其实就是在Splunk的REST API的支持下执行的。在使用CLI的时候,由于是通过SSL连接的,不太容易直接看到网络包明文。但可看出网络包的传输情况(大小、数量和先后顺序),还有最明显的是指定了带https协议头的目标地址,根据以上迹象猜测的话,也应该是通过REST API执行的用户操作。
另外,从Splunk安装的系统服务中能够看出,在6.2版本之前splunkd与splunkweb是运行在两个进程中的,6.2版本之后splunkweb服务就不再启用了。如下所示:

后经演化,合二为一,两个模块都在一个叫做<code>Splunkd</code>的系统进程中,对应的系统注册服务名称为<code>Splunkd Service</code>。

1.3 检索命令与SPL
尽管用户可以选用不同的交互界面,但无论何种界面下,检索操作都是通过提交 检索命令 来进行的。换句话说,Splunk异常强大的信息检索能力正是来源于功能强悍且丰富的 检索命令。Splunk设计了一套面向Ad-hoc查询称为SPL(Splunk Processing Language)的表达式语言,用以定义检索命令。
在讨论SPL之前,首先梳理一下Splunk关于数据检索功能的设计思想。
作为在事件管理领域积累多年的大厂,Splunk总结了用户利用事件数据进行分析的两大需求方向:
- 数据调查:在事件记录中寻找导致问题的根本原因。
- 数据汇总:将事件数据汇总于表格或者可视化图表之中。
相应地,Splunk将自身的数据检索也分为了两大类:
- 原始事件检索(Raw Event Search)
- 报表汇总检索(Transforming Search)
所谓的“原始事件检索”就是指首先依靠索引字段从索引中查找事件数据,然后可能再进一步结合一些检索条件获得目标结果,最终的结果集可能并不大。
所谓的“报表汇总检索”主要是指对从索引中获得的结果集进行一定的计算与转换,最终获得变形之后的目标结果,比如一组统计数字。
以上先说到这里。那么,SPL具体长什么样子,都包括什么呢?
SPL由以下内容组成:
- 命令项定义:包括命令关键字名称、命令参数结构等
- 函数定义:完成常用的计算、统计等功能的算子,通常作为命令参数使用
- 子句定义:作为命令项的补充,主要服务于一些统计、报表命令
- 管道:连接命令执行,传递命令执行结果
另外,SPL还定义了基本的简单语法,以约束命令的使用与组合方式。
上述解释,看起来非常地。。。凌乱。SPL确实是Splunk原创的,但它实质上就是Unix/Linux命令与SQL的结合体。“命令与管道”参照了Unix/Linux系统命令,“函数与子句”则参照了SQL,而一些语法其实就是规定这两种风格的东西如何混在一起使用。
从两种非常优秀的系统中吸取精华,自然能够保证自身的强大。但是,另外一方面,正如前述,它非常的杂乱,尤其是初阶使用多少会感觉难以摸准规律(几乎没有规律)、难以掌握。这也是Splunk被广为诟病的问题。
用SPL定义的,向检索命令整体结构大致如下:
检索 := <command>{<pipe><command>}
其中的<pipe>就是符号“|”,而<command>结构就比较杂乱了,其中有一部分类Linux命令设计的。比如,“取得结果中的前20行数据”的命令如下:
... | head 20
Splunk中的这类命令并不像linux里那样,以“-”符号表示命令选项,并在选项后紧随参数值,而多是直接后跟“选项参数名称=选项参数值”的形式。与<code>... | head 20</code>等价的非简略写法如下:
... | head limit=20
除了以上这种仿照linux系统命令的命令项,还有一种就是类SQL的了。比如,“对数据分组后在某个时间维度上做统计”的命令如下:
... | chart dc(clientip) over date_hour by categoryId
以上命令中,<code>chart</code>是命令项名称关键字,<code>over</code>与<code>by</code>是子句关键字,而<code>dc(...)</code>是去重计数函数。这就有点类似于SQL中的<code>select ……,count(distinct ...) from ... group by ... </code>结构。
1.4 检索命令的性质与类别
读者可能注意到,上节中关于检索命令的示例中,命令的开头处都带了<code>...|</code>这一小段。什么意思呢?这须从Splunk的命令的性质谈起。
首先,按照命令的输入与输出性质。Splunk将命令分成两大类,
- 产生式(Generating)命令
- 非产生式命令
所谓的产生式命令是指,命令本身不需要从前序管道中接收任何数据输入,而是可以系统索引或者系统元信息作为输入源数据,根据命令参数处理后输出结果。典型的产生式命令如<code>search</code>以及<code>metadata</code>等。
产生式命令执行后的结果输出可以作为最终结果,也可以通过管道传输给后续命令进行处理。在后续的命令里,就差不多轮到非产生式命令发挥作用了,它们通常用来过滤、转换、补充、计算输入的数据。所以,非产生命令,又被称作“报表(reporting)命令”或者“转换(transforming)命令”。
那么,上节中关于检索命令的示例中,命令的开头处都带了<code>...|</code>,是因为例子中涉及的<code>head</code>与<code>chart</code>命令都属于非产生式命令,这类命令不可能放置于检索定义的头部位置。
在一个检索定义中,无论其中有多少步管道处理,位于最前部的命令必须是产生式命令。
以上是就命令的输入输出角度来讨论命令性质。另外,若根据命令在管道连接中处理数据的方式来看,那么可以将命令分为:
- 并行流式
- 集中流式
- 非流处理
分别解释如下。
1.4.1 并行流式
首先“流式”的含义是指,命令指定的数据处理操作不需要等待上游数据准备完全,而是可以数据块为单位,从上游管道中按块获取,按块处理,并按块传入下个管道。
再次,“并行”是指,命令的处理逻辑可以允许将任务作并行处理,各子任务之间无需同步等复杂操作。
示意图如下所示:

典型地此类命令,多涉及到一些简单的转换、过滤等操作。如:<code>convert</code>、<code>fields</code>等命令。
1.4.2 集中流式
集中流式首先满足“流式”含义。但是,由于命令的处理逻辑中涉及到状态处理,则无法轻易地将任务并行化。
示意图如下所示:
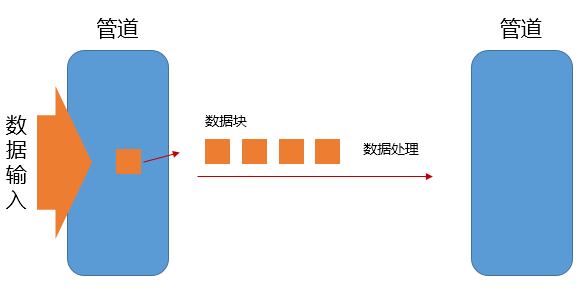
此类命令的例子比如<code>head</code>,它需要计数所得到的事件个数,达到指定个数为止。为了方便状态的维护,只能作集中处理而不能并行化。
1.4.3 非流处理
非流处理命令是指,命令指定的数据处理操作必须等待上游数据准备完全,不能够做到“从上游管道中按块获取,按块处理,并按块传入下个管道”。
示意图如下所示:

此类命令的例子,比如使用<code>sort</code>对数据进行排序。它不能按块处理后并按块向后传递,相反,它必须等待上游的结果全部准备完毕后,才能得出最终处理结果,然后再统一向下传递。
1.5 提交检索
使用Splunk Web进行数据检索的时候,通常给人的体验是在线、同步的感觉。这只是表面上的感觉,以Splunk Web为例,其实Splunk执行用户检索的过程如下:
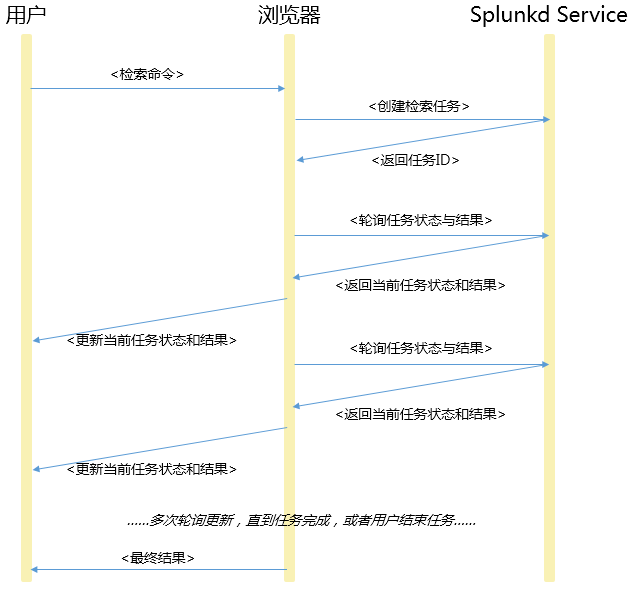
这个过程,理论上讲是离线、异步的过程。只是时间粒度大小的问题。
2.检索效率与优化
若参看过《Splunk数据处理概要》并且读完本文以上章节以后,就会明白:若想要用好Splunk,关于其背后的一些原理性内容,还是需要有一定掌握的。尤其是涉及到检索效率的问题时,很容易由于不良的检索定义造成检索执行无效率、甚至无法完成检索的后果。
首先需要明确的是: 在一个检索定义中,位于最前部的检索命令会从索引中获得原始的事件数据,后续的再过滤、转换、计算、统计等等操作都是在内存中进行的!
所以,一切优化的原则都是以尽可能精准地获取原始数据,缩小数据输入规模为基础!
3.检索命令宏定义与自定义检索命令
Splunk支持检索命令宏定义。
Splunk支持用户自定义检索命令,主要是完成一些注册配置工作,命令逻辑由用户提供python脚本定义。注意,用户自定义命令等方式为提供python脚本并不代表Splunk内置的所有命令都是由python定义的,python是一种良好的可嵌入的脚本,可在很多种语言平台上执行。
4.总结与讨论
Splunk的检索与报告能力非常强大,但由于设计与实现的其原理与机制,笔者对于其应对大规模数据处理存在疑问。
举个简单的例子:从索引中检索出1T大小的原始事件数据,后续又管道衔接了非流处理的命令,那么上哪去找1T的空间供管道缓存这1T数据?
至少Splunk没有正式地对类似的这种情况作以特殊说明。
End















 1407
1407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









