






一、HDFS简介
这篇官网的文章是介绍HDFS特性的:
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
这里截取HDFS关键架构的图:
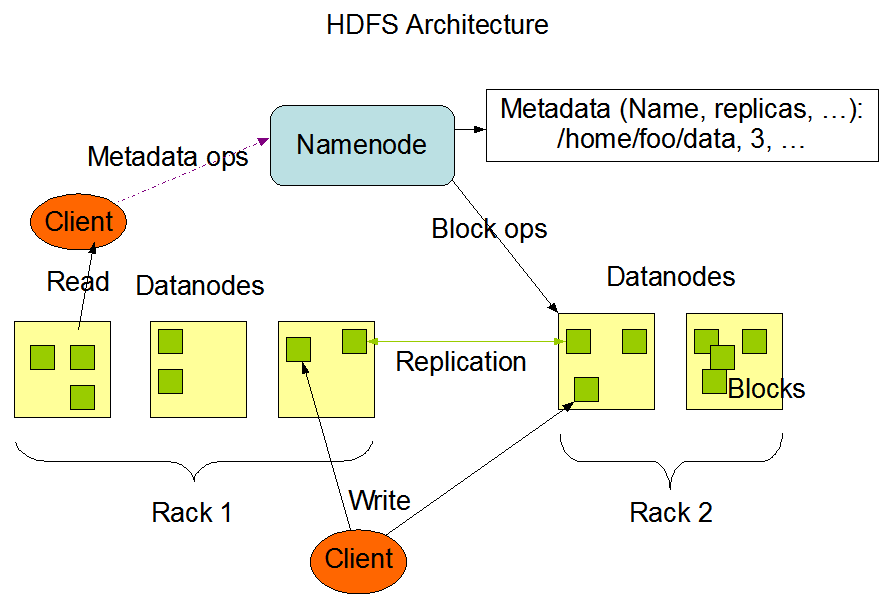
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
二、运行HDFS
1、配置core-site.xml
主要配置默认hdfs位置和数据空间
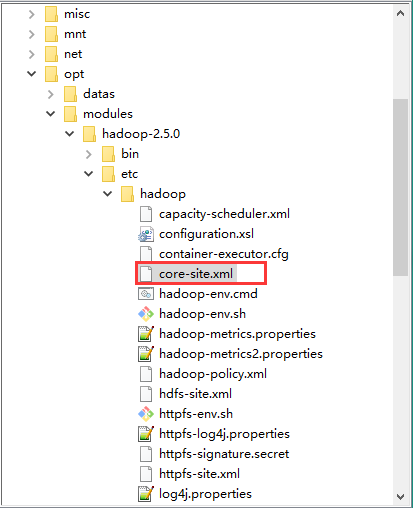
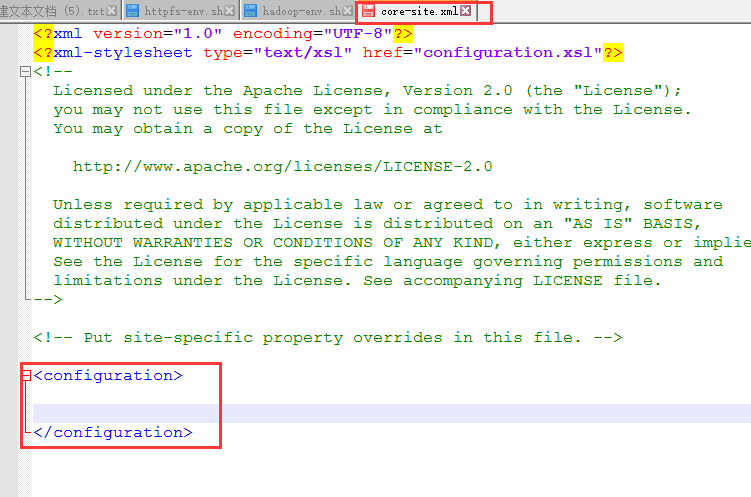
加入两个配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
另外一个是hadoop数据
在hadoop根目录下创建data/tmp
mkdir -p /opt/modules/hadoop-2.5.0/data/tmp
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
最后core-site.xml是这样的:
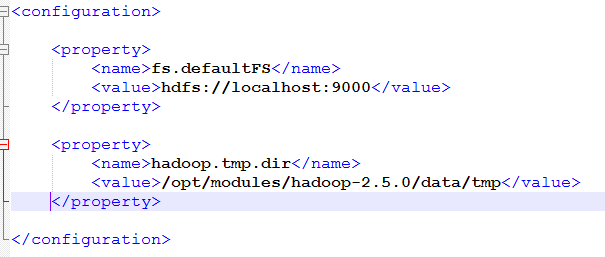
2、配置hdfs-site.xml
主要是配置备份数
加入这个:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3、启动
先到hadoop主目录下:
cd /opt/modules/hadoop-2.5.0
(1)格式化hdfs系统:
bin/hdfs namenode -format
(2)启动namenode
sbin/hadoop-daemon.sh start namenode
(3)启动datanode
sbin/hadoop-daemon.sh start datanode
(4)jps查看进程,如果有两个进程,表示成功了
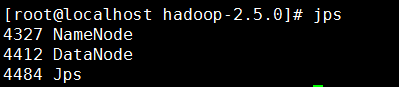
(5)可以在浏览器中访问hdfs
IP:50070
这里可能会访问不到,因为防火墙开着,需要在防火墙中开发50070端口
vi /etc/sysconfig/iptables
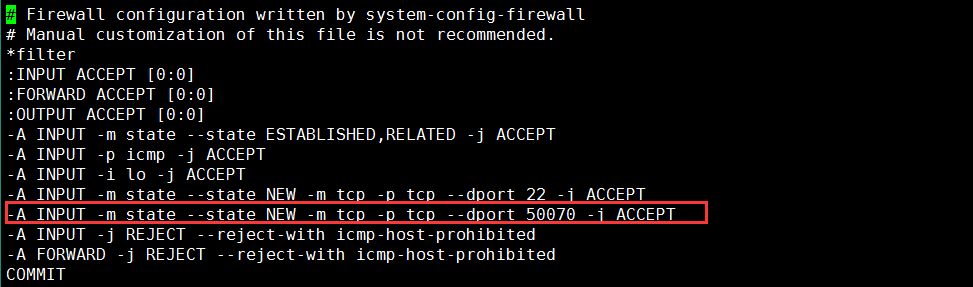
在命令模式下(按Esc),可以在端口22那一行,按两下yy,再按下p
就可以复制那一行粘贴到下一行,改一下端口即可
4、hdfs常用命令
(1)查看一个目录的内容
bin/hdfs dfs -ls -R /
这个是查看根目录下的所有东西
中间有两个参数:-ls 表示查看目录信息 -R 表示递归查看
(2)创建目录
bin/hdfs dfs -mkdir -P /user/wangkai/wordcount/input
这个是递归创建目录
两个参数:-mkdir 表示创建目录 -P 表示创建多级目录
(3)上传文件
bin/hdfs dfs -put /opt/datas/wcinput/* /user/wangkai/wordcount/input
-put参数表示上传文件
是说把本地/opt/datas/wcinput/*的内容,全部上传到hdfs中的/user/wangkai/wordcount/input中
(4)查看文件
bin/hdfs dfs -cat /user/wangkai/wordcount/input/hdfs-site.xml
-cat表示查看文件
5、在hdfs上运行wordcount程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/wangkai/wordcount/input /user/wangkai/wordcount/output
运行完后,查看结果:
bin/hdfs dfs -cat /user/wangkai/wordcount/output/part-r-00000
这样就在hdfs上运行了hadoop程序了















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









