





1.MapRedce 是一个分布式运行框架
优点:简单的实现一些接口就可以完成分布式程序
高容错性:一天机器挂掉,会迁移到另一台机器。处理数据量大
缺点:慢 不擅长实时计算 不擅长流式计算(spark解决了) ,不擅长DAG(有向图)计算
2.MapReduce核心编程思想

1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行
3.手写WordCount累加
创建一个maven工程,引入jar
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
编写Mapper类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
编写Reducer类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
编写Driver驱动类
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
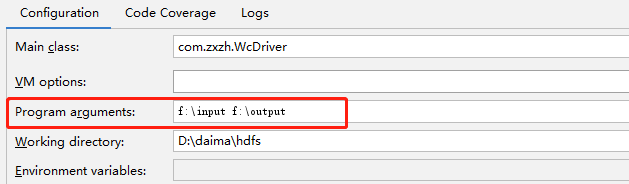
设置参数(Windows环境上配置HADOOP_HOME环境变量,解压win10的hadoop jar包)

4.Hadoop序列化(Java的序列话是一个重量级的框架)编写MapReduce程序徐需要序列化 implements Writable 重新write,readFields 方法
Hadoop序列号特点
1.紧促:高效使用存储空间
2.快速:读写数据的额外开销小
3.可扩展:谁着通信协议的升级而升级
4.互操作:支持多语言的交互
5.MapReduce原理

1)切片与MapTask并行度决定机制(yarn会在就近的机器上启动,IO网络传输消耗时间)
1.MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
eg:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2.MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行


按文件切分,和splitSize(默认等于Block大小)的1.1倍计较。按照splitSize1倍切分。不考虑数据集整体。逐个对每一个文件单独切分。
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}6.MapReduce工作原理


2.流程详解
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)多个溢出文件会被合并成大的溢出文件
4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
6)ReduceTask会取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
7.shuffle机制

1).Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value序列化数据,Partition分区信息等。
2).Spill 阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3).Merge 阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程(一个是内存到磁盘的合并,一个是磁盘到磁盘的合并)对内存到本地的数据文件进行合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask 阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可
Shuffle的大致流程为:Maptask会不断收集我们的map()方法输出的kv对,放到内存缓冲区中,当缓冲区达到饱和的时候(默认占比为0.8)就会溢出到磁盘中,如果map的输出结果很多,则会有多个溢出文件,多个溢出文件会被合并成一个大的溢出文件,在文件溢出、合并的过程中,都要调用partitoner进行分组和针对key进行排序(默认是按照Key的hash值对Partitoner个数取模),之后reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,reducetask会将这些文件再进行合并(归并排序)。合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出每一个键值对的Group,调用UDF函数(用户自定义的方法))















 2906
2906











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









