






本次我们来通过翻页爬取的方式爬取猫眼电影里面推荐的前100名电影,并存储到数据库。
1、我们登录猫眼,看下我们的数据在哪里
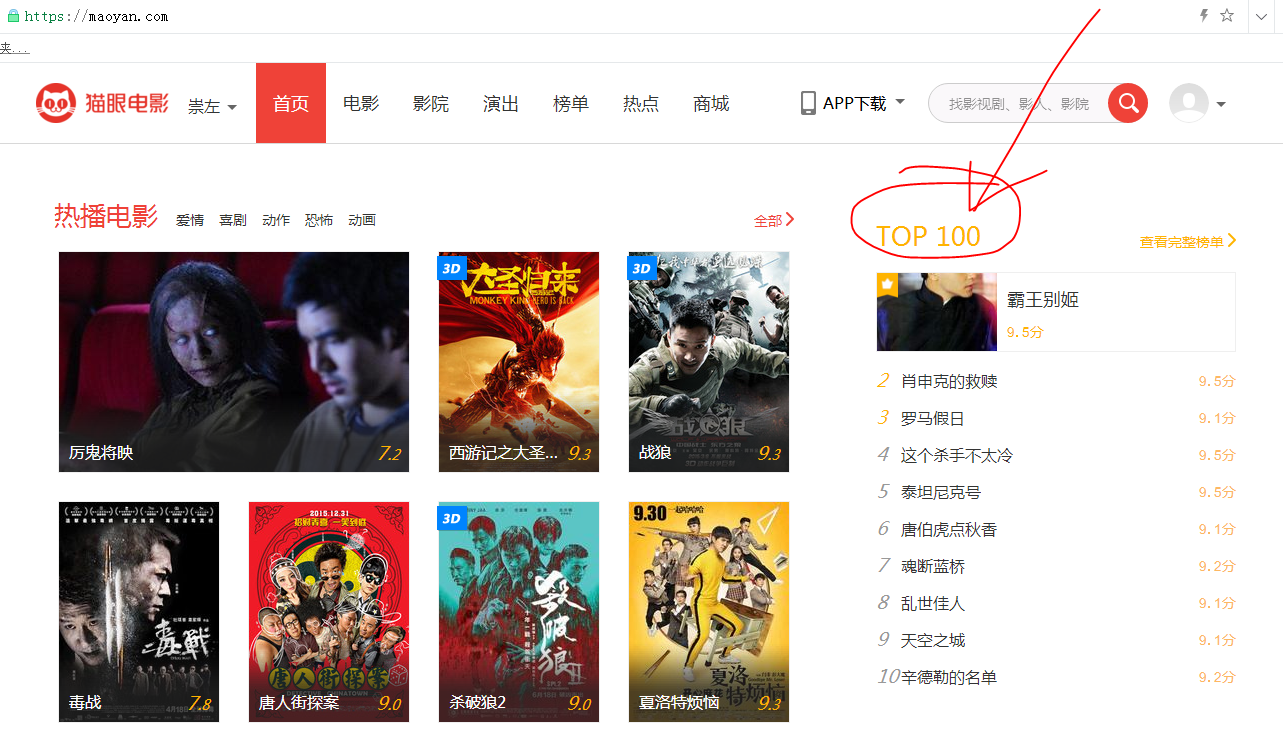
然后点击今日TOP100,看下具体的网页数据
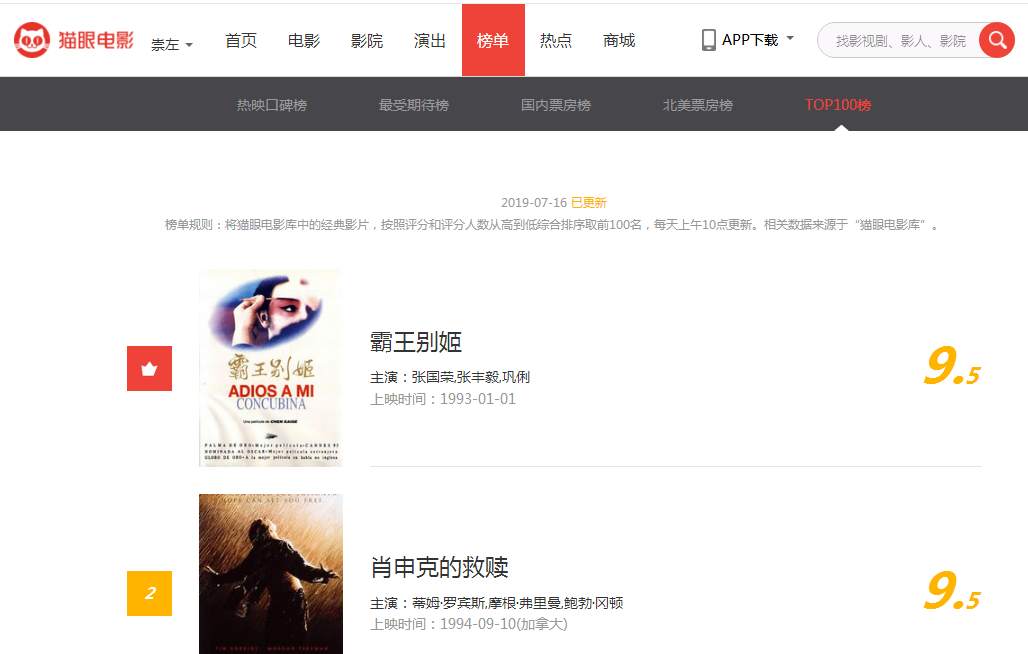
最下面我们看到底部有页码,并分析页码与地址栏的关系。
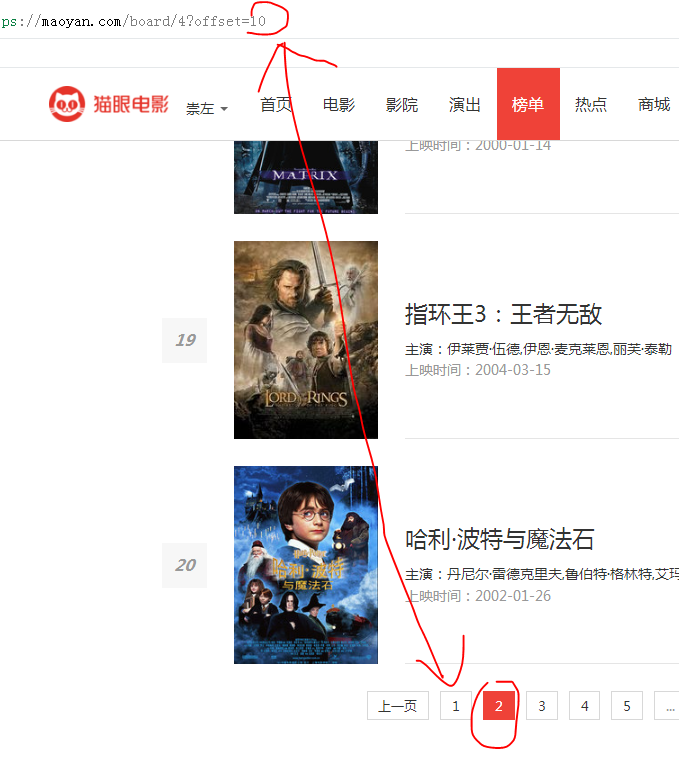
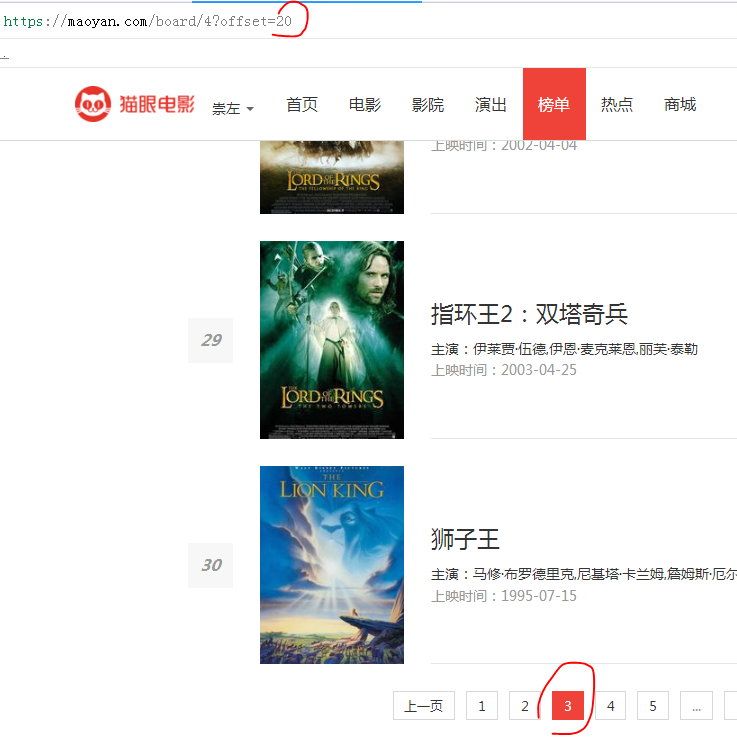

我们可以总结出以下规律:
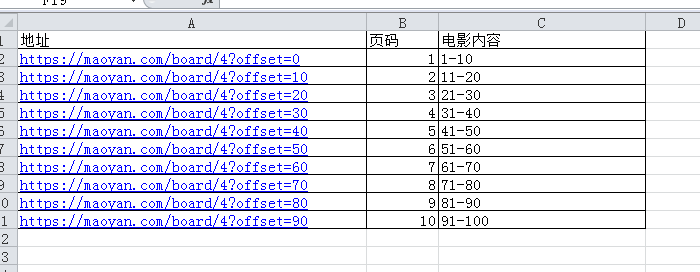
后续我们通过不断变化地址栏就可以实现翻页搜索信息的效果。
而,我们要获取的影片内容有哪些?下面这些:排名、影片名称、主演、上映时间、评分。
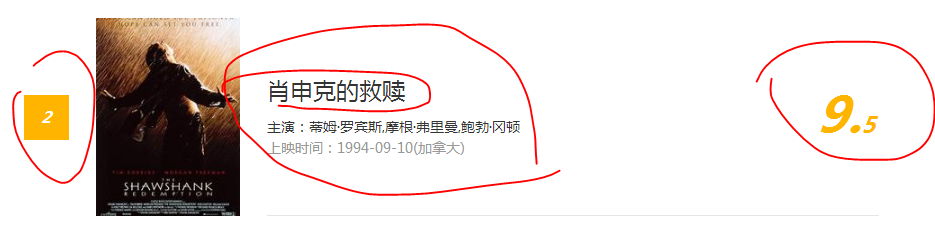
对于我们要获取的信息,我们要查看源码,看下对应的信息的通用格式是怎样的。
按F12键,在调试模式里面点击小箭头,选中对应的页面元素就可以看到元素的源代码了。
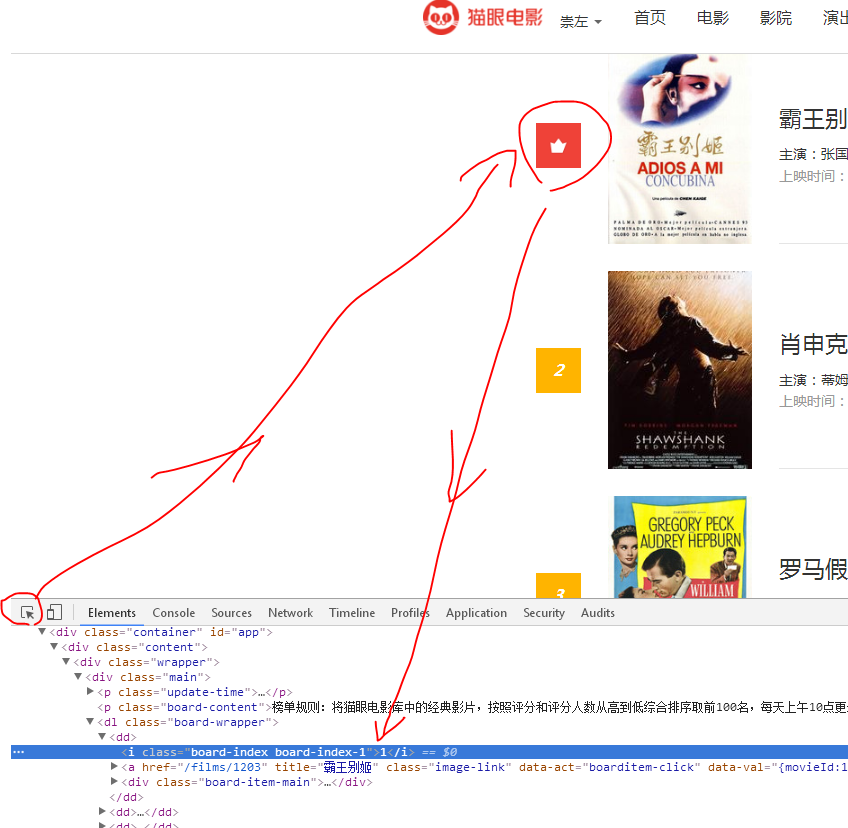
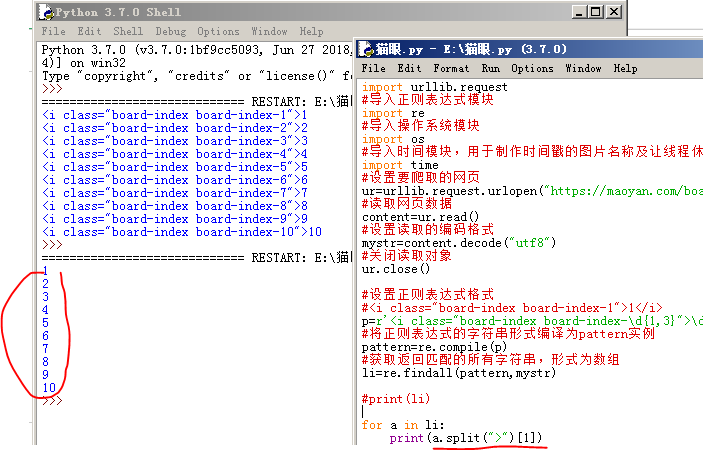
1、排名:
元素格式:<i class="board-index board-index-1">1</i>
上面格式中的红色字体是可以改变的,比如第二名就是:<i class="board-index board-index-2">2</i>
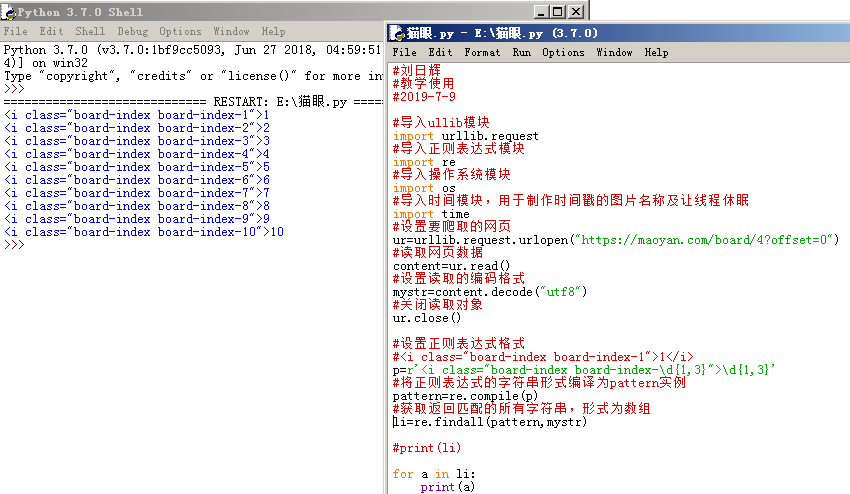
我们可以用\d{1,3} 代替1-100的数字,那么对应的正则表达式可以写成:
p=r'<i class="board-index board-index-\d{1,3}">\d{1,3}'
所以,我们获取排名的代码如下:
最后在修改一下,把数字提取出来,用split()函数:
2、电影名称:
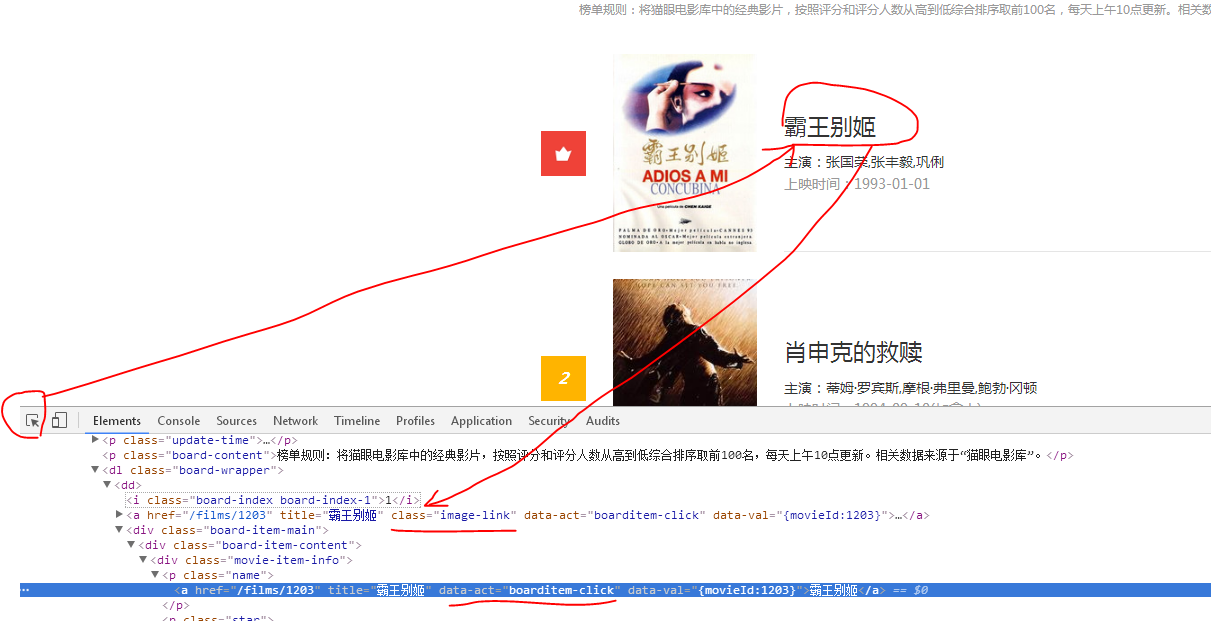
有两条,我们只取一条就可以了。
元素格式:<a href="/films/1203" title="霸王别姬" class="image-link"
根据上面,我们可以写正则表达式为:p2=r'<a href="/films/\d{1,}" title="\S{1,}" class="image-link"
代码如下:

最后,我们要修改下,只过滤电影名称,采用split()函数
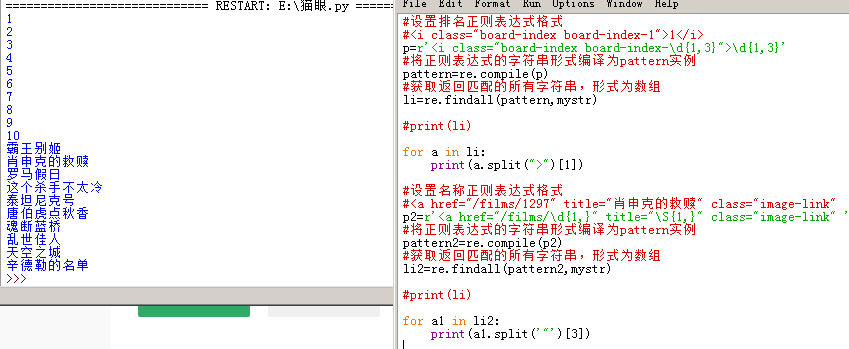
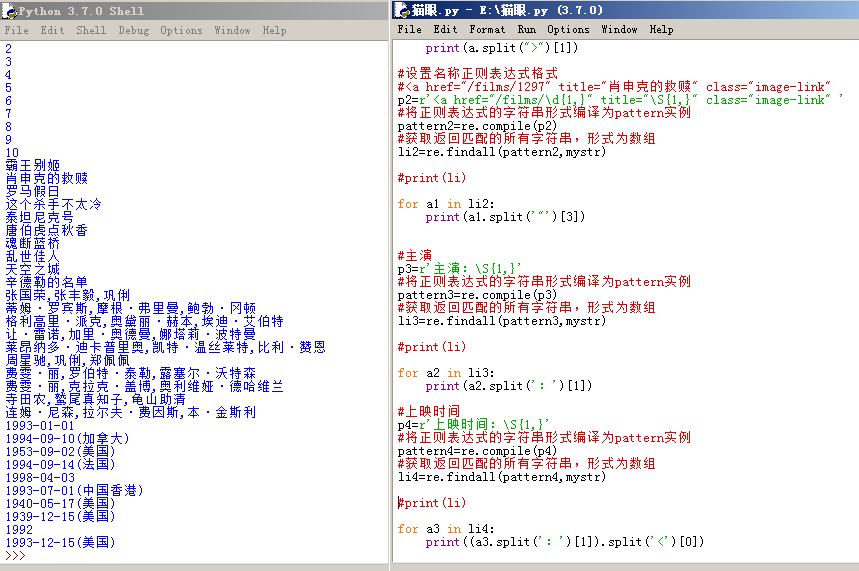
3、主演与上映时间:
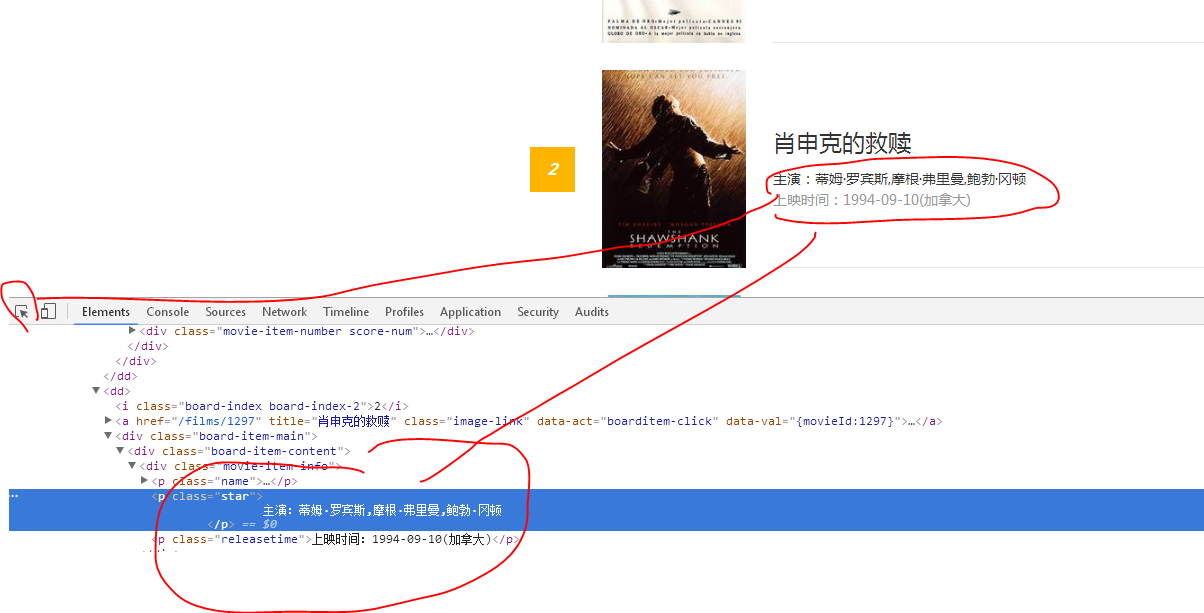
4、最后是评分
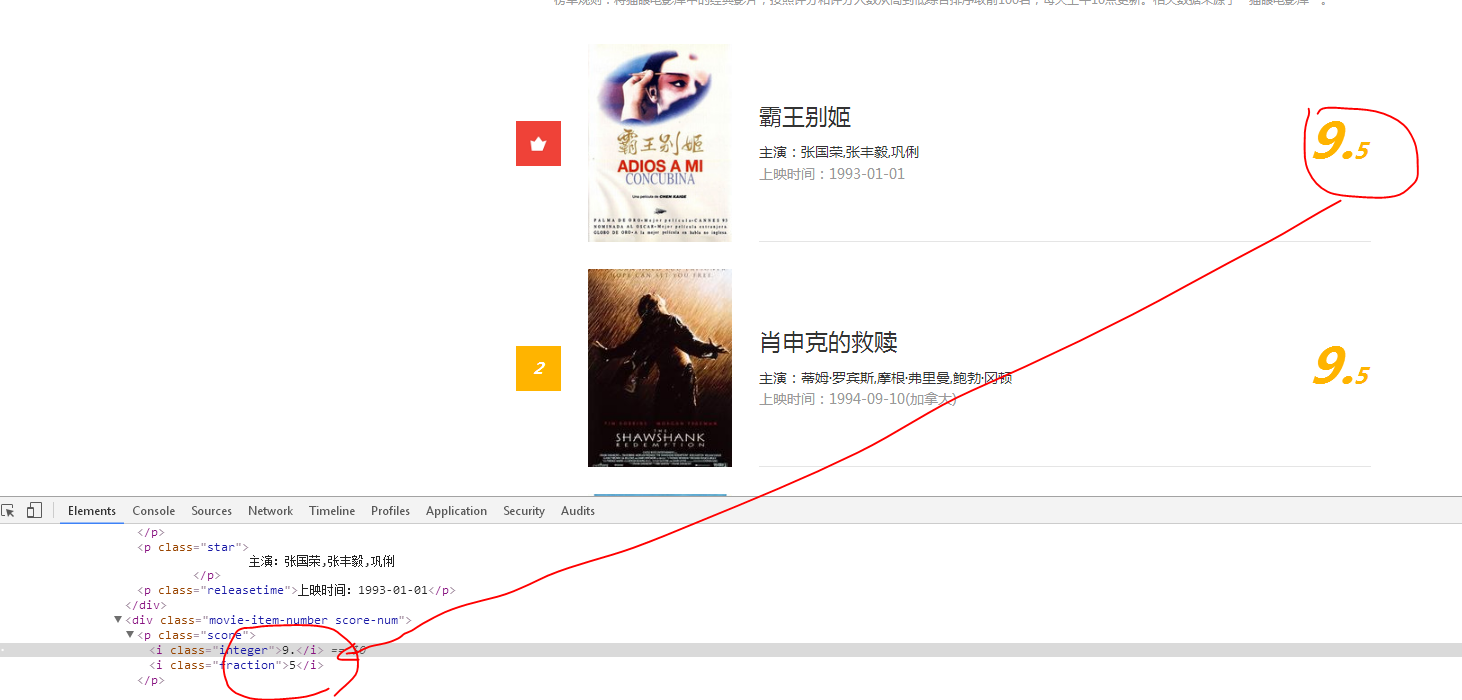
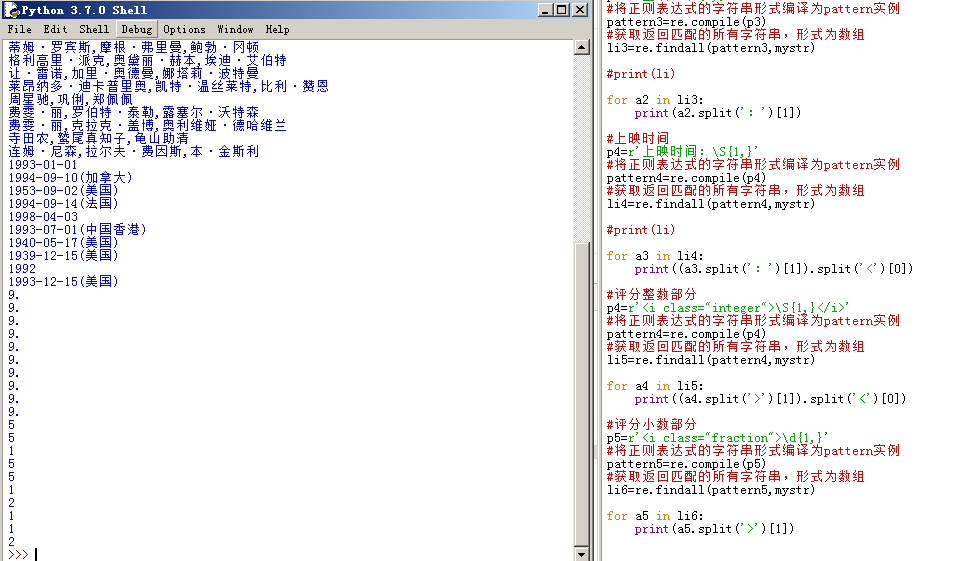
最后,我们要做的是:
1、分值合并。
2、以上各个值的组装。
3、写入数据库。
4、翻页
先写到这里,同学们思考上面两个,答案下面一讲再公布。
注:其实我们的正则表达式更加精准的话,就不用截取那么多次。后续再重点讲正则表达式这块知识。















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









