






我也看过很多Sizzle源码分析的博客,伪类分割器setMatcher介绍的比较少。但是本人认为这是一个比较重要的难点,我第一遍看源码的时候也忽略了。现在回来看第二遍,一定要把这个东东弄懂。
a. 伪类分割器setMatcher
伪类分隔器对伪类选择器进行分隔处理,返回处理后的最终匹配器。
伪类和其他原子匹配器有些不同,伪类具有强制的位置关系,特别是和别的选择器并列的时候。比如"p[name]"中选择器“p”和选择器"[name]"这两者并列且没有强制位置关系,"p[name]" == "[name]p"。但是伪类往往都有强制的位置关系,比如
<div id="chua">
<a>
<span>chua的测试用例</span>
</a>
<p class="group">
<label for="age">年龄:</label>
<input type="text" id="age" value="20" readonly/>
<p>
<span class="group"><span>
</div>CSS选择器为"#chua .group:first",$.find("#chua .group:first") = [<p class="group">…</p>]
CSS选择器为"#chua :first.group", $.find("#chua :first.group") = []
两者完全不同。所以,我们不能再从右往左解析,应该分成四个部分来处理:伪类左边的CSS选择器为一组(前置选择器),伪类选择器为一组(伪类选择器),伪类之后和伪类并列的选择器为一组(伪类并列选择器),最后剩下的CSS选择器为一组(后置选择器);然后我们分别把这四组选择器对应生成的匹配函数叫做:前置匹配器,伪类匹配器,伪类并列匹配器,后置匹配器。
Sizzle的伪类分割器生成的匹配器内部执行流程是:
先执行前置匹配器筛选出备选种子matcherIn(实际上这个东东不能算是备选种子,因为最终matcherIn的作用是作为搜索范围context而不是seed)。
//通过前置匹配器preFilter先过滤出待选种子elems,把过滤结果放入matcherIn中
//preMap存放过滤后的种子集合matcherIn在过滤前的备选种子集合elems中的位置
matcherIn = preFilter && ( seed || !selector ) ? condense( elems, preMap, preFilter, context, xml ) :
elems,
//通过匹配函数filter先过滤出满足filter匹配函数的种子
//unmatched:备选种子
//map: 保存通过filter过滤出来的种子在备选种子unmatched中对应的位置
//filter:匹配函数
//返回:过滤出来的种子
function condense( unmatched, map, filter, context, xml ) {
var elem,
newUnmatched = [],
i = 0,
len = unmatched.length,
mapped = map != null;
for ( ; i < len; i++ ) {
if ( (elem = unmatched[i]) ) {
if ( !filter || filter( elem, context, xml ) ) {
newUnmatched.push( elem );
if ( mapped ) {
map.push( i );
}
}
}
}
return newUnmatched;
}然后执行伪类匹配器将备选种子matcherIn筛选一遍,筛选结果(匹配得上伪类匹配器的)存入matcherOut。
//如果存在伪类匹配器,使用之。将满足条件节点从matcherIn中取出来存到matcherOut中
//这个判断阻止伪类并列匹配器和后置匹配器使用setMatcher时进入该分支
if ( matcher ) {
matcher( matcherIn, matcherOut, context, xml );
}然后执行伪类并列匹配器(如果有的话),去除matcherOut中不符合条件的元素(该元素在matcherOut的位置置为false,后面循环matcherOut取出来的时候只有非false的节点才会被取出来:if ( (elem = matcherOut[i]) ) )。
//执行伪类并列匹配器
if ( postFilter ) {
//将matcherOut拷贝到temp中
temp = condense( matcherOut, postMap );
//执行匹配
postFilter( temp, [], context, xml );
// 丢掉不匹配的元素(把他们移回到matcherIn)
i = temp.length;
while ( i-- ) {
if ( (elem = temp[i]) ) {
//matcherOut[ postMap[i] ] = false;
matcherOut[ postMap[i] ] = !(matcherIn[ postMap[i] ] = elem);
}
}
}最后执行后置匹配器,把matcherOut拷贝一份作为搜索范围context传入后置匹配器中执行,获取到真正的结果。(其中需要注意的是如果参数中传递了备选种子seed过来,从种子seed中移动匹配节点【和后置匹配器结果相同】到results中,保证他们同步)。
if ( seed ) {
if ( postFinder || preFilter ) {
//如果有后置匹配器则先执行后置匹配器,
//将先前得到的种子matcherOut拷贝为temp作为搜索范围context传入
//执行结果获得新的种子放入matcherOut中
if ( postFinder ) {
//获取最终matcherOut(把matcherOut置为空后插入到postFinder上下文环境中获取结果)
temp = [];
i = matcherOut.length;
while ( i-- ) {
if ( (elem = matcherOut[i]) ) {
//修复matcherIn因为节点不是最终匹配的结果
temp.push( (matcherIn[i] = elem) );
}
}
postFinder( null, (matcherOut = []), temp, xml );
}
//从种子seed中移动匹配节点到results中,保证他们同步(所谓同步,就是将seed上该位置置为false)
i = matcherOut.length;
while ( i-- ) {
if ( (elem = matcherOut[i]) &&
(temp = postFinder ? indexOf.call( seed, elem ) : preMap[i]) > -1 ) {
seed[temp] = !(results[temp] = elem);
}
}
}
//添加节点到results(通过postFinder【如果定义了的话】)
} else {
matcherOut = condense(
matcherOut === results ?
matcherOut.splice( preexisting, matcherOut.length ) :
matcherOut
);
if ( postFinder ) {
//将matcherOut作为搜索范围context传入
postFinder( null, results, matcherOut, xml );
} else {
push.apply( results, matcherOut );
}
}
这里有一个细节,普通匹配器的参数是三个,没有备选种子这个参数,如下是没有经过setMatcher之前的伪类并列匹配器和后置匹配器
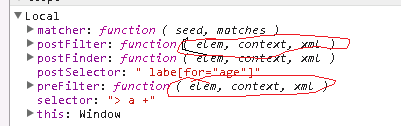
而伪类分割器setMatcher生成的匹配器是四个参数,如下是经过setMatcher之后的伪类并列匹配器和后置匹配器
//伪类并列匹配器存在且其中没有伪类原子选择器
if ( postFilter && !postFilter[ expando ] ) {
postFilter = setMatcher( postFilter );
}
//后置匹配器存在,且其中没有伪类原子选择器
if ( postFinder && !postFinder[ expando ] ) {
postFinder = setMatcher( postFinder, postSelector );
} 
这样做的目的在伪类分割器生成的匹配器函数中有体现(执行伪类并列匹配器,需要从先前执行过前置匹配器+伪类匹配器得到备选种子种筛选,需要传递备选种子,至于后置匹配器实际没有备选种子需要传递,为了统一而这样处理的)
完整源码分析如下
//函数用来分隔伪类选择器,并整合生成完整的匹配函数(执行分割后的匹配器的方法)。设用来分隔的伪类选择器为presudo
//preFilter:前置匹配器:presudo之前的所有选择器token组成的CSS选择器的匹配函数(没有包含伪类)
//selector:preFilter对应的CSS选择器字符串
//matcher:伪类匹配器:presudo的匹配函数
//postFilter:伪类并列匹配器:presudo之后和presudo并列(所谓并列指的是presudo和这些原子选择器直接相连,
//中间没有任何关系选择器,比如:"p :first.group[type='text'] > span"中伪类presudo=":first"
//,而选择器".gourp"和"[type='text']"就是和presudo并列的选择器)的选择器组的匹配函数
//postFinder:后置匹配器: presudo(如果有与presudo并列的选择器组,则此处应该是哪个选择器组)之后的所有选择器的匹配函数
//postSelector: postFinder匹配函数对应的CSS选择器字符串
function setMatcher( preFilter, selector, matcher, postFilter, postFinder, postSelector ) {
//伪类并列匹配器存在且其中没有伪类原子选择器
if ( postFilter && !postFilter[ expando ] ) {
postFilter = setMatcher( postFilter );
}
//后置匹配器存在,且其中没有伪类原子选择器
if ( postFinder && !postFinder[ expando ] ) {
postFinder = setMatcher( postFinder, postSelector );
}
//给最终匹配函数添加伪类标志属性并返回终匹配函数(最终匹配器)
return markFunction(function( seed, results, context, xml ) {
var temp, i, elem,
preMap = [],
postMap = [],
preexisting = results.length,
//从seed或context中获取备选种子
elems = seed || multipleContexts( selector || "*", context.nodeType ? [ context ] : context, [] ),
//通过前置匹配器preFilter先过滤出待选种子elems,把过滤结果放入matcherIn中
//preMap存放过滤后的种子集合matcherIn在过滤前的备选种子集合elems中的位置
matcherIn = preFilter && ( seed || !selector ) ?
condense( elems, preMap, preFilter, context, xml ) :
elems,
//过滤一些特出情况,这些特殊情况下可以直接得到CSS选择器组的结果matcherOut
matcherOut = matcher ?
//如果有后置匹配器
//或有备选种子的情况下前置匹配器存在
//或没有备选种子的情况下(a.存在部分已经确定的结果;b.伪类并列匹配器存在)a与b两者至少有一个成立
postFinder || ( seed ? preFilter : preexisting || postFilter ) ?
// ...中间处理是必要的
[] :
// ...否则,直接使用结果
results :
matcherIn;
//如果存在伪类匹配器,使用之。将满足条件节点从matcherIn中取出来存到matcherOut中
if ( matcher ) {
matcher( matcherIn, matcherOut, context, xml );
}
//执行伪类并列匹配器
if ( postFilter ) {
//将matcherOut拷贝到temp中
temp = condense( matcherOut, postMap );
//执行匹配
postFilter( temp, [], context, xml );
// 丢掉不匹配的元素(把他们移回到matcherIn)
i = temp.length;
while ( i-- ) {
if ( (elem = temp[i]) ) {
//matcherOut[ postMap[i] ] = false;
matcherOut[ postMap[i] ] = !(matcherIn[ postMap[i] ] = elem);
}
}
}
if ( seed ) {
if ( postFinder || preFilter ) {
//如果有后置匹配器则先执行后置匹配器,
//将先前得到的种子matcherOut拷贝为temp作为搜索范围context传入
//执行结果获得新的种子放入matcherOut中
if ( postFinder ) {
//获取最终matcherOut(把matcherOut置为空后插入到postFinder上下文环境中获取结果)
temp = [];
i = matcherOut.length;
while ( i-- ) {
if ( (elem = matcherOut[i]) ) {
//修复matcherIn因为节点不是最终匹配的结果
temp.push( (matcherIn[i] = elem) );
}
}
postFinder( null, (matcherOut = []), temp, xml );
}
//从种子seed中移动匹配节点到results中,保证他们同步(所谓同步,就是将seed上该位置置为false)
i = matcherOut.length;
while ( i-- ) {
if ( (elem = matcherOut[i]) &&
(temp = postFinder ? indexOf.call( seed, elem ) : preMap[i]) > -1 ) {
seed[temp] = !(results[temp] = elem);
}
}
}
//添加节点到results(通过postFinder【如果定义了的话】)
} else {
matcherOut = condense(
matcherOut === results ?
matcherOut.splice( preexisting, matcherOut.length ) :
matcherOut
);
if ( postFinder ) {
//将matcherOut作为搜索范围context传入
postFinder( null, results, matcherOut, xml );
} else {
push.apply( results, matcherOut );
}
}
});
}
//通过匹配函数filter先过滤出满足filter匹配函数的种子
//unmatched:备选种子
//map: 保存通过filter过滤出来的种子在备选种子unmatched中对应的位置
//filter:匹配函数
//返回:过滤出来的种子
function condense( unmatched, map, filter, context, xml ) {
var elem,
newUnmatched = [],
i = 0,
len = unmatched.length,
mapped = map != null;
for ( ; i < len; i++ ) {
if ( (elem = unmatched[i]) ) {
if ( !filter || filter( elem, context, xml ) ) {
newUnmatched.push( elem );
if ( mapped ) {
map.push( i );
}
}
}
}
return newUnmatched;
}这个函数有点难,需要点全局把握的观念和想象力。
b. matcherFromGroupMatchers——生成终极匹配器执行函数
有了终极匹配函数,但是我们还需要规定匹配开始的范围,然后将范围内的节点一一代入终极匹配函数中执行检索出匹配的结果。这就是matcherFromGroupMatchers函数做的事。
superMatcher 函数这个方法并不是一个直接定义的方法,通过matcherFromGroupMatchers( elementMatchers, setMatchers )方法return出来的一个curry化的函数,但是最后执行起重要作用的是它。
superMatcher 函数的执行步骤如下:
第一步,初始化各个变量,最重要的是初始化待选元素(参数传递的备选种子集合或搜索范围context的所有后代节点)
//确定起始查找范围或是参数中传递过来的备选种子seed,或是搜索范围context的所有后代节点
elems = seed || byElement && Expr.find["TAG"]( "*", expandContext && context.parentNode || context ),第二步,通过elementMatchers匹配(CSS选择器中没有伪类的选择器组对应的所有最终匹配器数组)的直接将元素添加到results中。特别需要注意两个变量,
matchedCount:整数,<=0,其绝对值是经过该次匹配但是没有匹配上的元素的数量;unmatched:数组,参数中传递的备选种子seed的拷贝。
//循环执行elementMatchers中的每一组CSS的最终匹配器
while ( (matcher = elementMatchers[j++]) ) {
if ( matcher( elem, context, xml ) ) {
results.push( elem );
break;
}
}第三步,备选元素在第二步的匹配中有部分没有匹配上且存在下一组最终匹配器集合setMatchers的时候进入setMatchers的循环匹配。
//CSS选择器存在伪类的情况下,进入setMatchers最终匹配器组匹配
while ( (matcher = setMatchers[j++]) ) {
matcher( unmatched, setMatched, context, xml );
}这里有一个点没有看懂(if ( matchedCount > 0 ) 里面的东东有啥作用?我觉得去掉也不影响,反正结果都已经保存在results 中了,pop出来有啥用
),希望那个仁兄帮我解释一下
if ( seed ) {
if ( matchedCount > 0 ) {
while ( i-- ) {
if ( !(unmatched[i] || setMatched[i]) ) {
setMatched[i] = pop.call( results );
}
}
}
//丢弃指数占位符值只得到实际的匹配
setMatched = condense( setMatched );
}还有关键的一点就是elementMatchers和setMatchers两中匹配结束后,需要对结果去重和排序
//如果参数没有备选种子seed,匹配成功的多个成功的匹配需要保证唯一并排序
if ( outermost && !seed && setMatched.length > 0 &&
( matchedCount + setMatchers.length ) > 1 ) {
Sizzle.uniqueSort( results );
}好了,大致流程就到这里,根据流程取看代码就不复杂了。附上源码
function matcherFromGroupMatchers( elementMatchers, setMatchers ) {
var matcherCachedRuns = 0,//一个计数器来指定哪些元素正在匹配
bySet = setMatchers.length > 0,
byElement = elementMatchers.length > 0,
superMatcher = function( seed, context, xml, results, expandContext ) {
var elem, j, matcher,
setMatched = [],
matchedCount = 0,
i = "0",
unmatched = seed && [],
outermost = expandContext != null,
contextBackup = outermostContext,
//确定起始查找范围或是参数中传递过来的备选种子seed,或是搜索范围context的所有后代节点
elems = seed || byElement && Expr.find["TAG"]( "*", expandContext && context.parentNode || context ),
//使用整数dirruns当且仅当这是最外面的匹配
dirrunsUnique = (dirruns += contextBackup == null ? 1 : Math.random() || 0.1);
if ( outermost ) {
outermostContext = context !== document && context;
cachedruns = matcherCachedRuns;
}
//通过elementMatchers匹配的直接将元素添加到results中
//假如这里没有元素则保持变量`i`为一个字符,从而`matchedCount`在后面的值将是"00"
for ( ; (elem = elems[i]) != null; i++ ) {
if ( byElement && elem ) {
j = 0;
//循环执行elementMatchers中的每一组CSS的最终匹配器
while ( (matcher = elementMatchers[j++]) ) {
if ( matcher( elem, context, xml ) ) {
results.push( elem );
break;
}
}
if ( outermost ) {
dirruns = dirrunsUnique;
cachedruns = ++matcherCachedRuns;//指定正在执行的CSS选择器组
}
}
//跟踪没有匹配的元素,设置过滤。如果有
if ( bySet ) {
//他们使用过了一切可能的匹配器,但是没有任何匹配器能够匹配才能进入该分支
if ( (elem = !matcher && elem) ) {
matchedCount--;
}
//如果参数有传递备选种子,拷贝到unmatched中
if ( seed ) {
unmatched.push( elem );
}
}
}
//使用伪类选择器组的最终匹配器来匹配,
matchedCount += i;
//如果bySet存在的情况下,则i !== matchedCount表示有的元素还没有匹配成功。
//i == matchedCount表示前一轮使用elementMatchers将所有的元素都匹配上了
if ( bySet && i !== matchedCount ) {
j = 0;
//匹配
while ( (matcher = setMatchers[j++]) ) {
matcher( unmatched, setMatched, context, xml );
}
if ( seed ) {
//重返元素匹配,无需进行排序。matchedCount>0表示前面使用elementMatchers过程中有元素有匹配上
//前面使用setMatchers匹配的时候备选种子集合unmatched中某个元素如果有匹配上,该元素在unmatched上的值会被赋值为false
if ( matchedCount > 0 ) {
while ( i-- ) {
//unmatched现在是所有没有匹配上setMatchers的备选种子集合
//setMatched现在为所有匹配上setMatchers的元素集合
//如果两者都没有则进入该分支
if ( !(unmatched[i] || setMatched[i]) ) {
setMatched[i] = pop.call( results );
}
}
}
//丢弃指数占位符值只得到实际的匹配
setMatched = condense( setMatched );
}
//添加匹配结果
push.apply( results, setMatched );
//如果参数没有备选种子seed,匹配成功的多个成功的匹配需要保证唯一并排序
if ( outermost && !seed && setMatched.length > 0 &&
( matchedCount + setMatchers.length ) > 1 ) {
Sizzle.uniqueSort( results );
}
}
//通过嵌套的匹配覆盖全局的操控
if ( outermost ) {
dirruns = dirrunsUnique;
outermostContext = contextBackup;
}
return unmatched;
};
return bySet ?
markFunction( superMatcher ) :
superMatcher;
}
如果觉得本文不错,请点击右下方【推荐】!















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









