






最近,遇到一个比较有意思的算法,现在将其简化抽象出来,记录在此。
1. 第一种情况:多对一
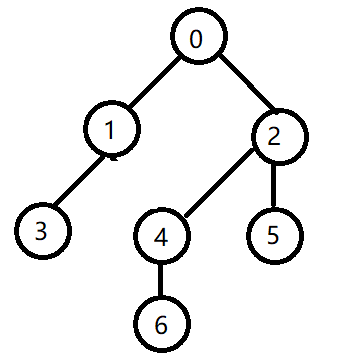
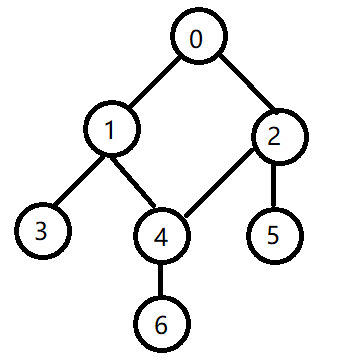
在某张表中存在如下右图所示的关系(左图是将其还原成树的形式,便于直观表达),多对一,多指的是多个节点,一指的是一个父子,现在的需求是要查出指定父节点下的所有子节点。

1. 思路:
将所有子节点放在set集合里,进行第一次遍历,找出其父节点为2的子节点,将set集合剔除第一次遍历符合条件的节点;
进行第二次遍历,找出其父节点为第一次遍历符合条件的节点,将set集合剔除第二次遍历符合条件的节点;
进行第三次遍历,重复以上步骤;
遍历结束的条件是:遍历没有找到符合条件的节点。
2. 过程:
假设现在找到节点为2的所有子节点,从allSons集合里第一次遍历:
节点3对应节点1,result集合没有节点1,不做操作,
节点1对应节点0,result集合没有节点0,不做操作,
节点6对应节点4,result集合没有节点4,不做操作,
节点4对应节点2,节点4符合要求,加入result集合,同时加入tmp集合,
节点5对应节点2,节点5符合要求,加入result集合,同时加入tmp集合,
节点2对应节点0,result集合没有节点0,不做操作。
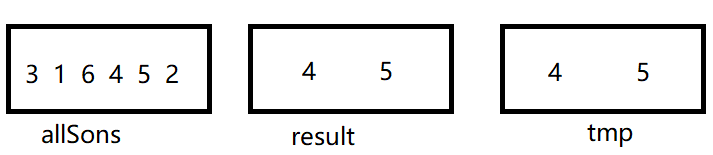
结果见上图,第一次遍历结束,其实只是找出了4,5这两个直接子节点,他们的父亲节点为2,然后在allSons集合中剔除tmp集合中数据,tmp集合再清空,此时结果如下:

第二次遍历:
节点3对应节点1,result集合没有节点1,不做操作,
节点1对应节点0,result集合没有节点0,不做操作,
节点6对应节点4,result集合有节点4,加入result集合,同时加入tmp集合,
节点2对应节点0,result集合没有节点0,不做操作。
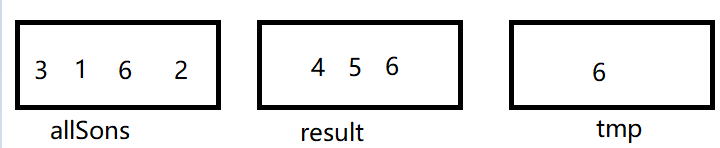
遍历结果见上图,第二次遍历只是找出数字为6的子节点,其父节点为4,而4的父节点为2,所以符合条件,然后在allSons集合中剔除tmp集合中数据,tmp集合再清空,此时结果如下:
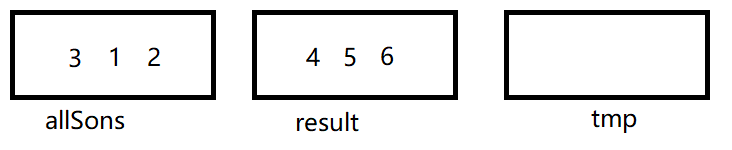
第三次遍历:
节点3对应节点1,result集合没有节点1,不做操作,
节点1对应节点0,result集合没有节点0,不做操作,
节点2对应节点0,result集合没有节点0,不做操作。
此次遍历,没有找到符合条件的子节点,遍历结束,result集合为最后集合。
3. 具体代码如下:
HashMap<Integer, Integer > map=new HashMap<>();
map.put(1, 0);
map.put(2, 0);
map.put(3, 1);
map.put(4, 2);
map.put(5, 2);
map.put(6, 4);
//多对一模型 map中存储的就是对应关系,拆成一对一
private static Set<Integer> findSons(Integer id,HashMap<Integer, Integer> map) {
Set<Integer> allSons = map.keySet(); //所有的子节点
Set<Integer> result=new HashSet<Integer>(); //符合要求的节点
Set<Integer> tmp=new HashSet<Integer>(); //临时辅助集合
boolean flag=false;
do {
flag=false;
for (Integer son:allSons) {
Integer parent = map.get(son);
if (id==parent||result.contains(parent)) {
result.add(son);
tmp.add(son);
flag=true;
}
}
allSons.removeAll(tmp);
tmp.clear();
} while (flag);
return result;
}这种算法的时间较优,循环次数和树的高度有关。
2. 第二种情况:多对多
多对多,指的是一个父节点有多个子节点,一个子节点有多个父节点,再数据库种的存储形式如下又图

这种情况思路和上面多对一的思路一样,可以拆成一对多的情况,存储的时候同样采用map集合
Map<Integer, Set<Integer>> map=new HashMap<Integer, Set<Integer>>();其中set集合用于存储多个父节点,按照上面的思路,代码稍微改动即可。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









